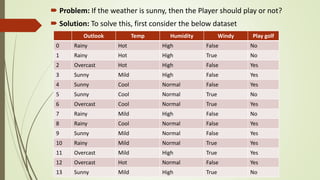
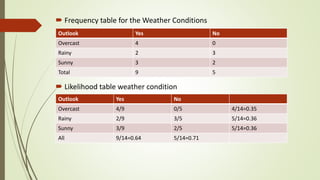
The document discusses Naive Bayes classifiers, which are a family of algorithms for classification that are based on Bayes' theorem and assume independence between features. It provides definitions of key terms like conditional probability and Bayes' theorem. It then derives the Naive Bayes classifier equation and discusses how it works, including an example of classifying whether to play golf based on weather conditions. The document also covers advantages like speed, disadvantages like the independence assumption, and applications like spam filtering.










![For all classes of Y we calculate probabilities and the class with
max(P) is returned as the final class
Result = argmax{(Yi / x1 x2 x3 ..xn)} like if we have 2 classes of Y
i.e. 0 and 1 then we calculate P[Y=1 / x1 x2 x3 …]and P[Y=0 / x1
x2 x3 …]
Now if P [Y=1] > P[Y=0] then 1 else 0 class is returned.](https://image.slidesharecdn.com/naviesbayes-210126083108/85/Navies-bayes-11-320.jpg)