Download as PDF, PPTX





![6 07:48:08 AM
The new way: SHOW PROCESSLIST + SHOW EXPLAIN
• Available in MariaDB 10.0+
• Displays EXPLAIN of a running statement
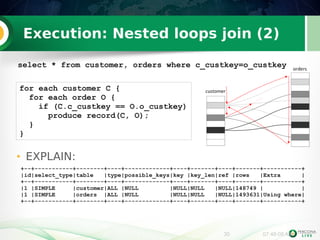
MariaDB> show processlist;
+--+----+---------+-------+-------+----+------------+-------------------------...
|Id|User|Host |db |Command|Time|State |Info
+--+----+---------+-------+-------+----+------------+-------------------------...
| 1|root|localhost|dbt3sf1|Query | 10|Sending data|select max(o_totalprice) ...
| 2|root|localhost|dbt3sf1|Query | 0|init |show processlist
+--+----+---------+-------+-------+----+------------+-------------------------...
MariaDB> show explain for 1;
+--+-----------+------+----+-------------+----+-------+----+-------+-----------+
|id|select_type|table |type|possible_keys|key |key_len|ref |rows |Extra |
+--+-----------+------+----+-------------+----+-------+----+-------+-----------+
|1 |SIMPLE |orders|ALL |NULL |NULL|NULL |NULL|1498194|Using where|
+--+-----------+------+----+-------------+----+-------+----+-------+-----------+
MariaDB [dbt3sf1]> show warnings;
+-----+----+-----------------------------------------------------------------+
|Level|Code|Message |
+-----+----+-----------------------------------------------------------------+
|Note |1003|select max(o_totalprice) from orders where year(o_orderDATE)=1995|
+-----+----+-----------------------------------------------------------------+](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-6-320.jpg)

![8 07:48:08 AM
Catching slow queries (NEW)
PERFORMANCE SCHEMA [MySQL 5.6, MariaDB 10.0]
● use performance_schema
● Many ways to analyze via queries
– events_statements_summary_by_digest
● count_star, sum_timer_wait,
min_timer_wait, avg_timer_wait, max_timer_wait
● digest_text, digest
● sum_rows_examined, sum_created_tmp_disk_tables,
sum_select_full_join
– events_statements_history
● sql_text, digest_text, digest
● timer_start, timer_end, timer_wait
● rows_examined, created_tmp_disk_tables,
select_full_join
8](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-8-320.jpg)
![9 07:48:08 AM
Catching slow queries (NEW)
PERFORMANCE SCHEMA [MySQL 5.6, MariaDB 10.0]
• Modified Q18 from DBT3
select c_name, c_custkey, o_orderkey, o_orderdate,
o_totalprice, sum(l_quantity)
from customer, orders, lineitem
where
o_totalprice > ?
and c_custkey = o_custkey
and o_orderkey = l_orderkey
group by c_name, c_custkey, o_orderkey,
o_orderdate, o_totalprice
order by o_totalprice desc, o_orderdate
LIMIT 10;
• App executes Q18 many times with
? = 550000, 500000, 400000, ...
9](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-9-320.jpg)
![10 07:48:08 AM
Catching slow queries (NEW)
PERFORMANCE SCHEMA [MySQL 5.6, MariaDB 10.0]
● Find candidate slow queries
● Simple tests: select_full_join > 0,
created_tmp_disk_tables > 0, etc
● Complex conditions:
max execution time > X sec OR
min/max time vary a lot:
select max_timer_wait/avg_timer_wait as max_ratio,
avg_timer_wait/min_timer_wait as min_ratio
from events_statements_summary_by_digest
where max_timer_wait > 1000000000000
or max_timer_wait / avg_timer_wait > 2
or avg_timer_wait / min_timer_wait > 2G](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-10-320.jpg)
![11 07:48:08 AM
Catching slow queries (NEW)
PERFORMANCE SCHEMA [MySQL 5.6, MariaDB 10.0]
*************************** 5. row ***************************
DIGEST: 3cd7b881cbc0102f65fe8a290ec1bd6b
DIGEST_TEXT: SELECT `c_name` , `c_custkey` , `o_orderkey` , `o_orderdate` ,
`o_totalprice` , SUM ( `l_quantity` ) FROM `customer` , `orders` , `lineitem` WHERE
`o_totalprice` > ? AND `c_custkey` = `o_custkey` AND `o_orderkey` = `l_orderkey` GROUP BY
`c_name` , `c_custkey` , `o_orderkey` , `o_orderdate` , `o_totalprice` ORDER BY `o_totalprice`
DESC , `o_orderdate` LIMIT ?
COUNT_STAR: 3
SUM_TIMER_WAIT: 3251758347000
MIN_TIMER_WAIT: 3914209000 → 0.0039 sec
AVG_TIMER_WAIT: 1083919449000
MAX_TIMER_WAIT: 3204044053000 → 3.2 sec
SUM_LOCK_TIME: 555000000
SUM_ROWS_SENT: 25
SUM_ROWS_EXAMINED: 0
SUM_CREATED_TMP_DISK_TABLES: 0
SUM_CREATED_TMP_TABLES: 3
SUM_SELECT_FULL_JOIN: 0
SUM_SELECT_RANGE: 3
SUM_SELECT_SCAN: 0
SUM_SORT_RANGE: 0
SUM_SORT_ROWS: 25
SUM_SORT_SCAN: 3
SUM_NO_INDEX_USED: 0
SUM_NO_GOOD_INDEX_USED: 0
FIRST_SEEN: 1970-01-01 03:38:27
LAST_SEEN: 1970-01-01 03:38:43
max_ratio: 2.9560
min_ratio: 276.9192
High variance of
execution time](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-11-320.jpg)
![12 07:48:08 AM
Catching slow queries (NEW)
PERFORMANCE SCHEMA [MySQL 5.6, MariaDB 10.0]
● Check the actual queries and constants
● The events_statements_history table
select timer_wait/1000000000000 as exec_time, sql_text
from events_statements_history
where digest in
(select digest from events_statements_summary_by_digest
where max_timer_wait > 1000000000000
or max_timer_wait / avg_timer_wait > 2
or avg_timer_wait / min_timer_wait > 2)
order by timer_wait;](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-12-320.jpg)
![13 07:48:08 AM
Catching slow queries (NEW)
PERFORMANCE SCHEMA [MySQL 5.6, MariaDB 10.0]
+-----------+-----------------------------------------------------------------------------------+
| exec_time | sql_text |
+-----------+-----------------------------------------------------------------------------------+
| 0.0039 | select c_name, c_custkey, o_orderkey, o_orderdate, o_totalprice, sum(l_quantity)
from customer, orders, lineitem
where o_totalprice > 550000 and c_custkey = o_custkey ... LIMIT 10 |
| 0.0438 | select c_name, c_custkey, o_orderkey, o_orderdate, o_totalprice, sum(l_quantity)
from customer, orders, lineitem
where o_totalprice > 500000 and c_custkey = o_custkey ... LIMIT 10 |
| 3.2040 | select c_name, c_custkey, o_orderkey, o_orderdate, o_totalprice, sum(l_quantity)
from customer, orders, lineitem
where o_totalprice > 400000 and c_custkey = o_custkey ... LIMIT 10 |
+-----------+-----------------------------------------------------------------------------------+
Observation:
orders.o_totalprice > ? is less and less selective](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-13-320.jpg)









![23 07:48:08 AM
New in MySQL-5.6: optimizer_trace
...
"range_scan_alternatives": [
{
"index": "i_o_orderdate",
"ranges": [
"1992-06-01 <= o_orderDATE < 1992-06-12",
"1992-06-12 < o_orderDATE <= 1992-07-03"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 319082,
"cost": 382900,
"chosen": true
},
{
"index": "i_o_date_clerk",
"ranges": [
"1992-06-01 <= o_orderDATE < 1992-06-12",
"1992-06-12 < o_orderDATE <= 1992-07-03"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 406336,
"cost": 487605,
"chosen": false,
"cause": "cost"
}
],
...
● Considered ranges are shown
in range_scan_alternatives
section
● This is actually original use
case of optimizer_trace
● Alas, recent mysql-5.6 displays
misleading info about ranges
on multi-component keys (will
file a bug)
● Still, very useful.](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-23-320.jpg)

















![42 07:48:08 AM
Index statistics in MySQL 5.6
● Sample [8] random index leaf pages
● Table statistics (stored)
– rows - estimated number of rows in a table
– Other stats not used by optimizer
● Index statistics (stored)
– fields - #fields in the index
– rows_per_key - rows per 1 key value, per prefix fields
([1 column value], [2 columns value], [3 columns value], …)
– Other stats not used by optimizer.](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-42-320.jpg)
![43 07:48:08 AM
Index statics updates
● Statistics updated when:
– ANALYZE TABLE tbl_name [, tbl_name] …
– SHOW TABLE STATUS, SHOW INDEX
– Access to INFORMATION_SCHEMA.[TABLES|
STATISTICS]
– A table is opened for the first time
(after server restart)
– A table has changed >10%
– When InnoDB Monitor is turned ON.](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-43-320.jpg)
![44 07:48:08 AM
Displaying optimizer statistics
● MySQL 5.5, MariaDB 5.3, and older
– Issue SQL statements to count rows/keys
– Indirectly, look at EXPLAIN for simple queries
● MariaDB 5.5, Percona Server 5.5 (using XtraDB)
– information_schema.[innodb_index_stats, innodb_table_stats]
– Read-only, always visible
● MySQL 5.6
– mysql.[innodb_index_stats, innodb_table_stats]
– User updatetable
– Only available if innodb_analyze_is_persistent=ON
● MariaDB 10.0
– Persistent updateable tables mysql.[index_stats, column_stats, table_stats]
– User updateable
– + current XtraDB mechanisms.](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-44-320.jpg)
![45 07:48:08 AM
Plan [in]stability
● Statistics may vary a lot (orders)
MariaDB [dbt3]> select * from information_schema.innodb_index_stats;
+------------+-----------------+--------------+ +---------------+
| table_name | index_name | rows_per_key | | rows_per_key | error (actual)
+------------+-----------------+--------------+ +---------------+
| partsupp | PRIMARY | 3, 1 | | 4, 1 | 25%
| partsupp | i_ps_partkey | 3, 0 | => | 4, 1 | 25% (4)
| partsupp | i_ps_suppkey | 64, 0 | | 91, 1 | 30% (80)
| orders | i_o_orderdate | 9597, 1 | | 1660956, 0 | 99% (6234)
| orders | i_o_custkey | 15, 1 | | 15, 0 | 0% (15)
| lineitem | i_l_receiptdate | 7425, 1, 1 | | 6665850, 1, 1 | 99.9% (23477)
+------------+-----------------+--------------+ +---------------+
MariaDB [dbt3]> select * from information_schema.innodb_table_stats;
+-----------------+----------+ +----------+
| table_name | rows | | rows |
+-----------------+----------+ +----------+
| partsupp | 6524766 | | 9101065 | 28% (8000000)
| orders | 15039855 | ==> | 14948612 | 0.6% (15000000)
| lineitem | 60062904 | | 59992655 | 0.1% (59986052)
+-----------------+----------+ +----------+
.](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-45-320.jpg)
![46 07:48:08 AM
Controlling statistics (MySQL 5.6)
● Persistent and user-updatetable InnoDB statistics
– innodb_analyze_is_persistent = ON,
– updated manually by ANALYZE TABLE or
– automatically by innodb_stats_auto_recalc = ON
● Control the precision of sampling [default 8]
– innodb_stats_persistent_sample_pages,
– innodb_stats_transient_sample_pages
●
No new statistics compared to older versions.](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-46-320.jpg)






![53 07:48:08 AM
Observing join condition pushdown
EXPLAIN: {
"query_block": {
"select_id": 1,
"nested_loop": [
{
"table": {
"table_name": "orders",
"access_type": "ALL",
"possible_keys": [
"i_o_custkey"
],
"rows": 1499715,
"filtered": 100,
"attached_condition": "((`dbt3sf1`.`orders`.`o_orderpriority` =
'1-URGENT') and (`dbt3sf1`.`orders`.`o_custkey` is not null))"
}
},
{
"table": {
"table_name": "customer",
"access_type": "eq_ref",
"possible_keys": [
"PRIMARY"
],
"key": "PRIMARY",
"used_key_parts": [
"c_custkey"
],
"key_length": "4",
"ref": [
"dbt3sf1.orders.o_custkey"
],
"rows": 1,
"filtered": 100,
"attached_condition": "(`dbt3sf1`.`customer`.`c_acctbal` <
<cache>(-(500)))"
}
● Before mysql-5.6:
EXPLAIN shows only
“Using where”
– The condition itself
only visible in debug
trace
● Starting from 5.6:
EXPLAIN FORMAT=JSON
shows attached
conditions.](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-53-320.jpg)







![61 07:48:08 AM
Attached conditions
● Ideally, should be used for table access
● Not all conditions can be used [at the same time]
– Unused ones are still useful
– They reduce number of scans for subsequent tables
select *
from
customer, orders
where
c_custkey=o_custkey and c_acctbal < -500 and
o_orderpriority='1-URGENT';
+--+-----------+--------+----+-------------+-----------+-------+------------------+------+-----------+
|id|select_type|table |type|possible_keys|key |key_len|ref |rows |Extra |
+--+-----------+--------+----+-------------+-----------+-------+------------------+------+-----------+
|1 |SIMPLE |customer|ALL |PRIMARY |NULL |NULL |NULL |150081|Using where|
|1 |SIMPLE |orders |ref |i_o_custkey |i_o_custkey|5 |customer.c_custkey|7 |Using where|
+--+-----------+--------+----+-------------+-----------+-------+------------------+------+-----------+](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-61-320.jpg)







![69 07:48:08 AM
Join analysis: PERFORMANCE SCHEMA
[MySQL 5.6, MariaDB 10.0]
● summary tables with read/write statistics
– table_io_waits_summary_by_table
– table_io_waits_summary_by_index_usage
● Superset of the userstat tables
● More overhead
● Not possible to associate statistics with a query
=> truncate stats tables before running a query
● Possible bug
– performance schema not ignored
– Disable by
UPDATE setup_consumers SET ENABLED = 'NO'
where name = 'global_instrumentation';](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-69-320.jpg)

























![95 07:48:08 AM
GROUP BY strategies
There are three strategies
● Ordered index scan
● Loose Index Scan (LooseScan)
● Groups table
(Using temporary; [Using filesort]).](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-95-320.jpg)





![101 07:48:08 AM
What if it still picks a poor query plan?
For both MariaDB and MySQL:
● Check EXPLAIN [EXTENDED], find a keyword around a
subquery table
● Google “site:kb.askmonty.org $subuqery_keyword”
or https://kb.askmonty.org/en/subquery-optimizations-map/
● Find which optimization it was
● set optimizer_switch='$subquery_optimization=off'](https://image.slidesharecdn.com/mysql-conf-2013-optimizer-tuning-130423095037-phpapp01/85/MySQL-MariaDB-query-optimizer-tuning-tutorial-from-Percona-Live-2013-101-320.jpg)


The document discusses techniques for identifying and addressing problems with a database query optimizer. It describes old and new tools for catching slow queries, such as the slow query log, SHOW PROCESSLIST, and the Performance Schema. It also provides examples of using these tools to analyze query plans, identify inefficient plans, and determine if optimizer settings or query structure need to be modified to address performance issues.
































































































