Downloaded 22 times






























![Pseudocode for Nested Loop Join
with Inner Sequential Scan
for (i = 0; i < length(outer); i++)
for (j = 0; j < length(inner); j++)
if (outer[i] == inner[j])
output(outer[i], inner[j]);
Explaining the Postgres Query Optimizer 34 / 56](https://image.slidesharecdn.com/postgresoptmizer-momjian-140923125617-phpapp01/85/Explaining-the-Postgres-Query-Optimizer-34-320.jpg)


![Pseudocode for Hash Join
for (j = 0; j < length(inner); j++)
hash_key = hash(inner[j]);
append(hash_store[hash_key], inner[j]);
for (i = 0; i < length(outer); i++)
hash_key = hash(outer[i]);
for (j = 0; j < length(hash_store[hash_key]); j++)
if (outer[i] == hash_store[hash_key][j])
output(outer[i], inner[j]);
Explaining the Postgres Query Optimizer 37 / 56](https://image.slidesharecdn.com/postgresoptmizer-momjian-140923125617-phpapp01/85/Explaining-the-Postgres-Query-Optimizer-37-320.jpg)


![Pseudocode for Merge Join
sort(outer);
sort(inner);
i = 0;
j = 0;
save_j = 0;
while (i < length(outer))
if (outer[i] == inner[j])
output(outer[i], inner[j]);
if (outer[i] <= inner[j] && j < length(inner))
j++;
if (outer[i] < inner[j])
save_j = j;
else
i++;
j = save_j;
Explaining the Postgres Query Optimizer 40 / 56](https://image.slidesharecdn.com/postgresoptmizer-momjian-140923125617-phpapp01/85/Explaining-the-Postgres-Query-Optimizer-40-320.jpg)








![Pseudocode for Nested Loop Join
with Inner Index Scan
for (i = 0; i < length(outer); i++)
index_entry = get_first_match(outer[j])
while (index_entry)
output(outer[i], inner[index_entry]);
index_entry = get_next_match(index_entry);
Explaining the Postgres Query Optimizer 49 / 56](https://image.slidesharecdn.com/postgresoptmizer-momjian-140923125617-phpapp01/85/Explaining-the-Postgres-Query-Optimizer-49-320.jpg)








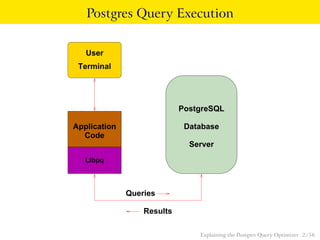
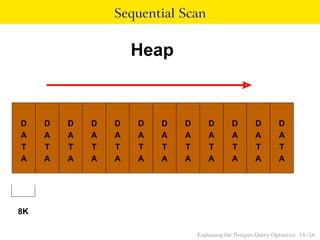
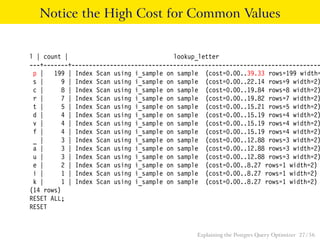
The document explains the Postgres query optimizer, describing its role in interpreting SQL queries and determining efficient execution paths. It covers various strategies including scan methods, join methods, and how distribution affects performance, using examples and the EXPLAIN command to illustrate these concepts. Additionally, it provides practical examples with SQL commands to demonstrate how different queries are executed and optimized.






![[pgday.Seoul 2022] PostgreSQL구조 - 윤성재](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2022-postgresql-20221112-221114014106-bbfb1955-thumbnail.jpg?width=640&height=640&fit=bounds)














![[Pgday.Seoul 2020] SQL Tuning](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-201117134901-thumbnail.jpg?width=640&height=640&fit=bounds)