Download to read offline


















![ Supported drivers: Java, .NET, Ruby, PHP, JavaScript, node.js, Python,
Perl, PHP, Scala and others
Implemented as methods or functions within the API of a specific
programming language, as opposed to a completely separate language like
SQL
[Example here]](https://image.slidesharecdn.com/mongodb-150808150712-lva1-app6892/75/MongoDB-22-2048.jpg)


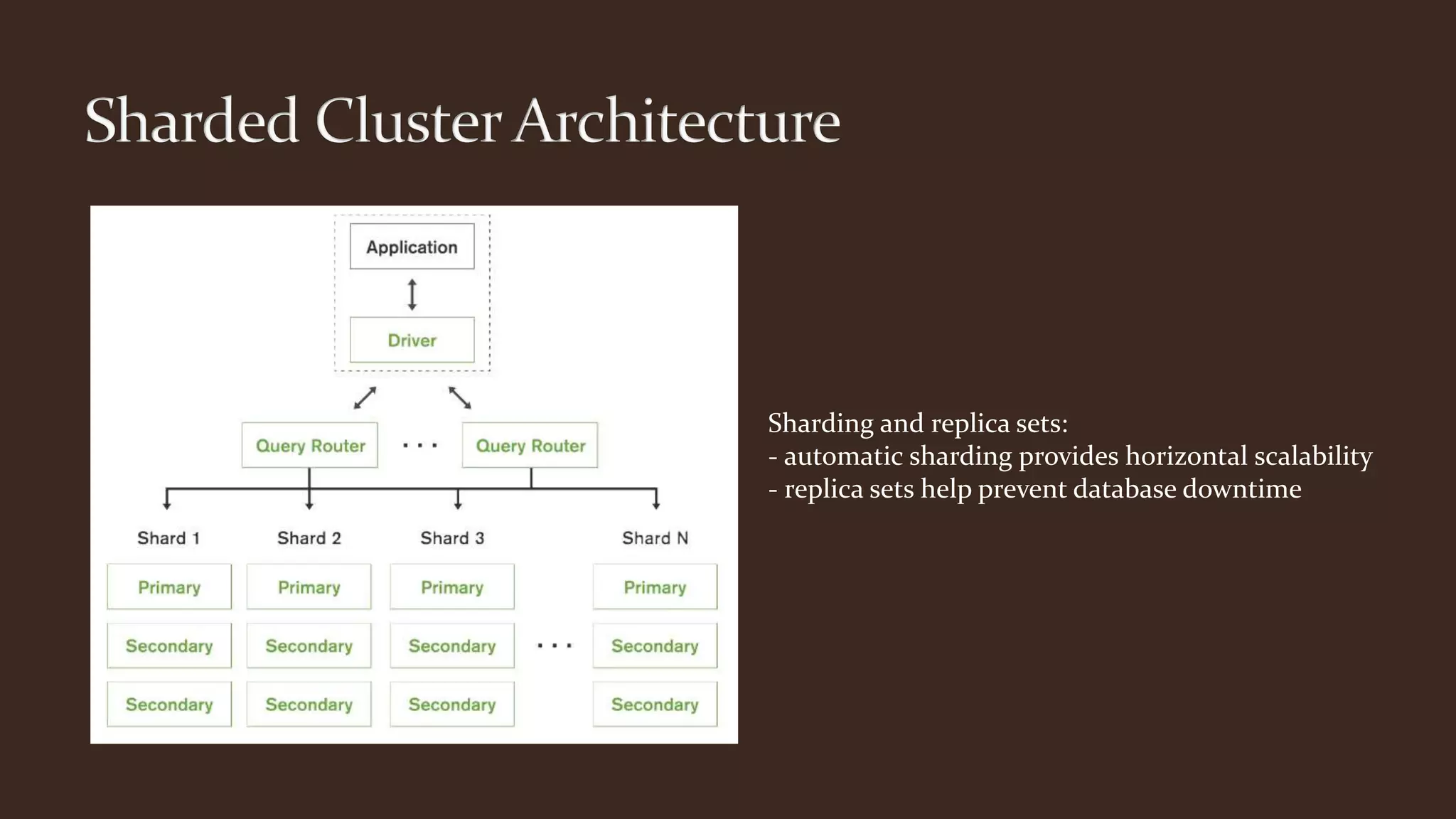
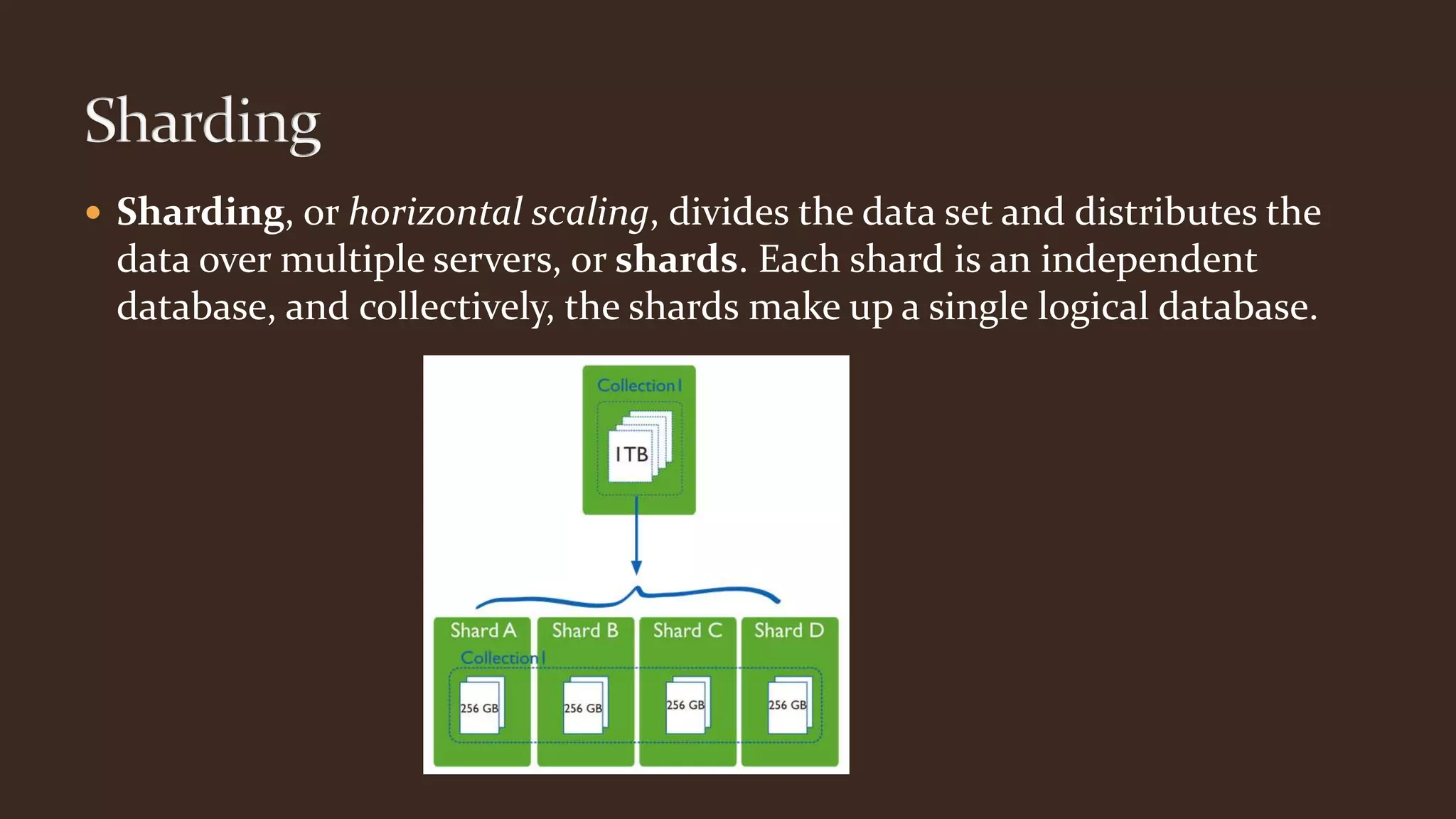
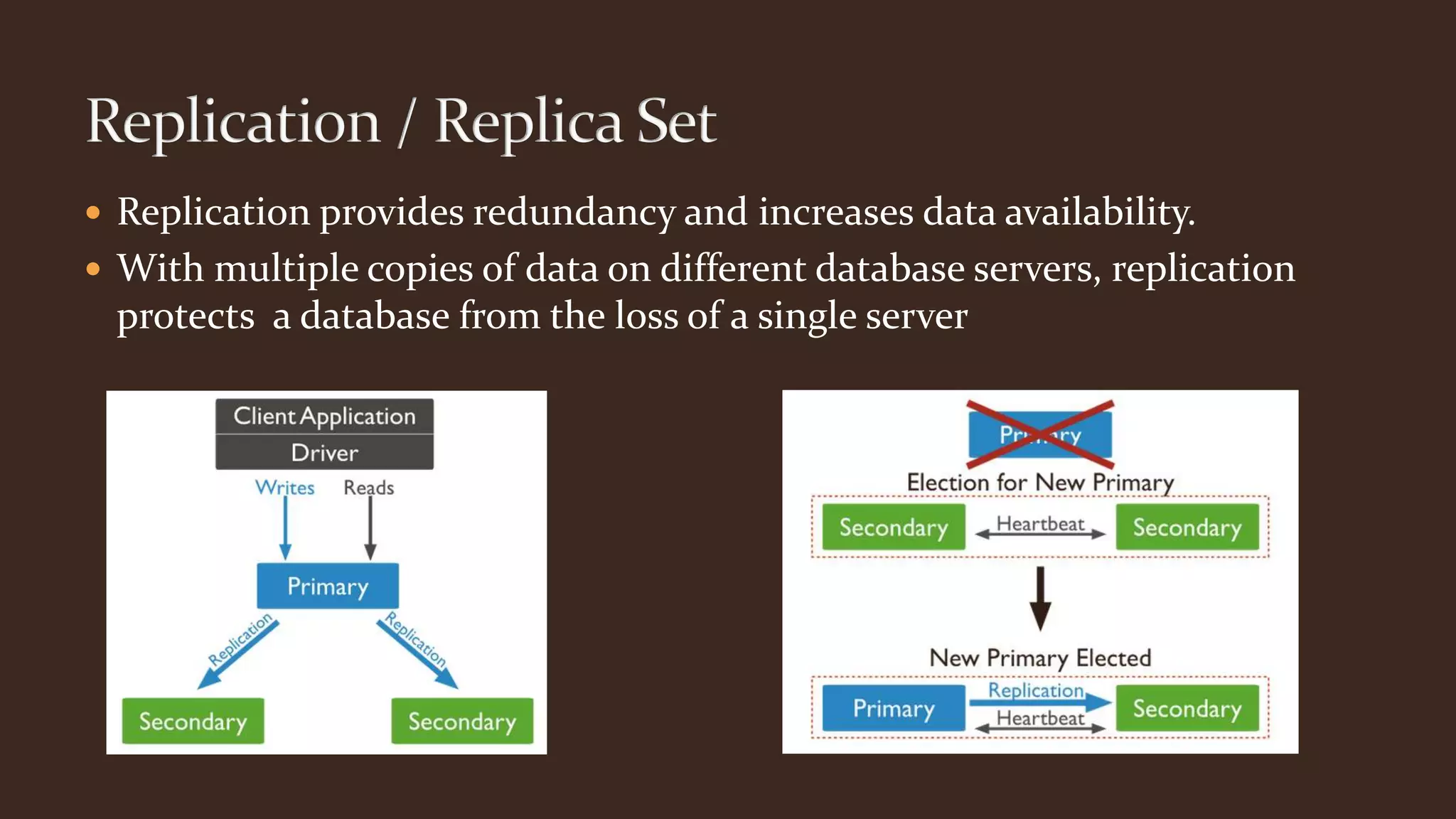





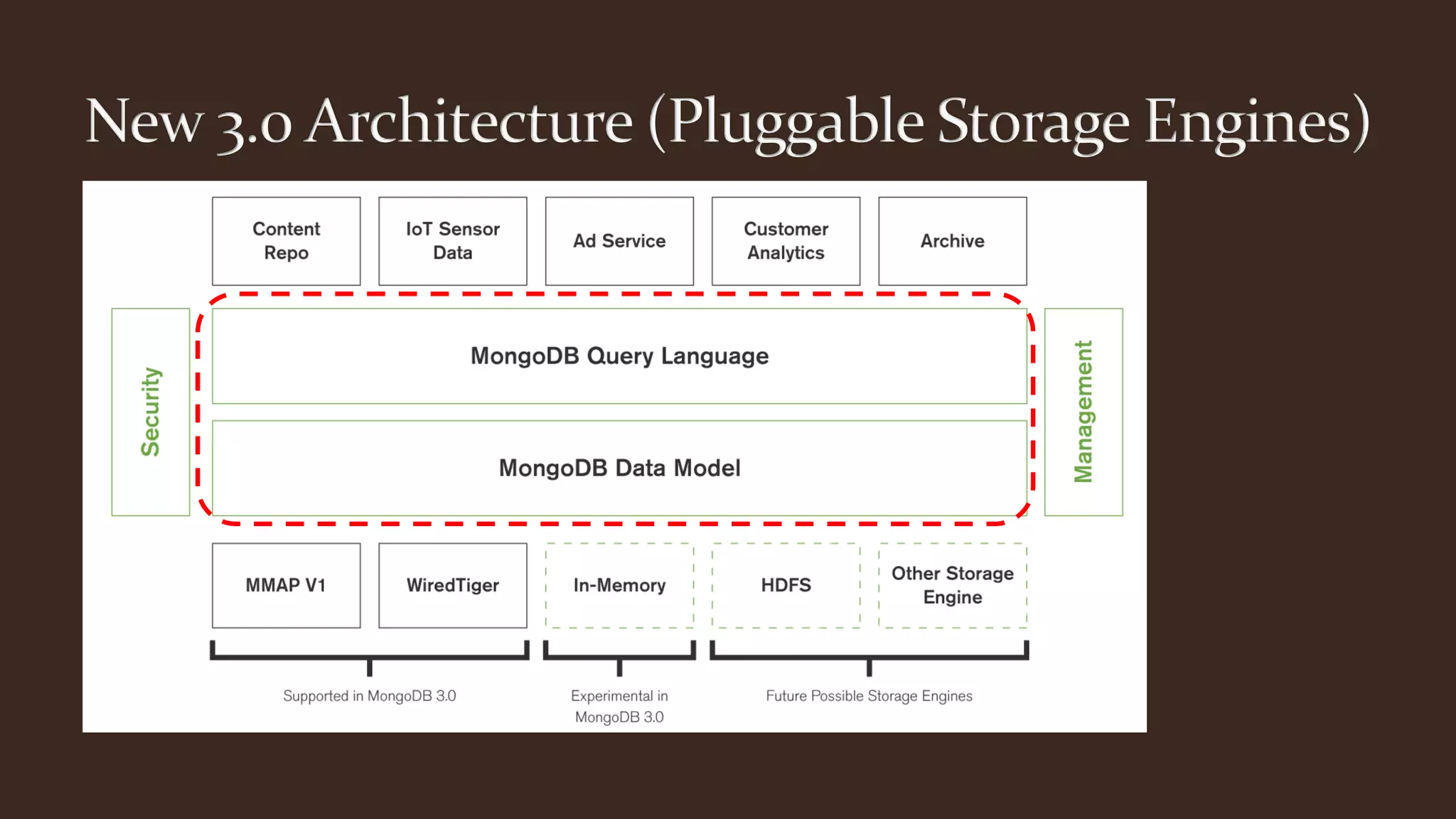
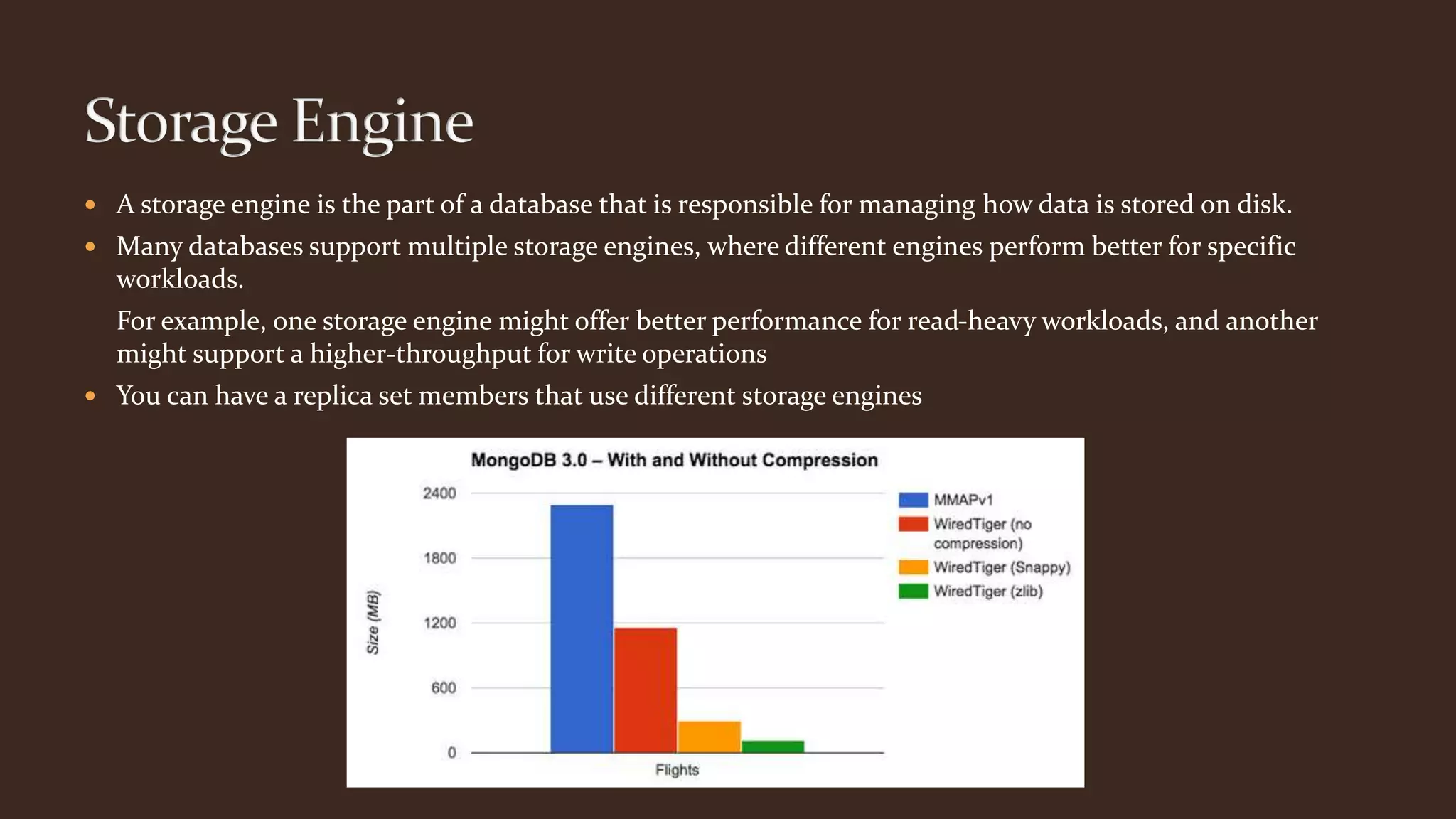
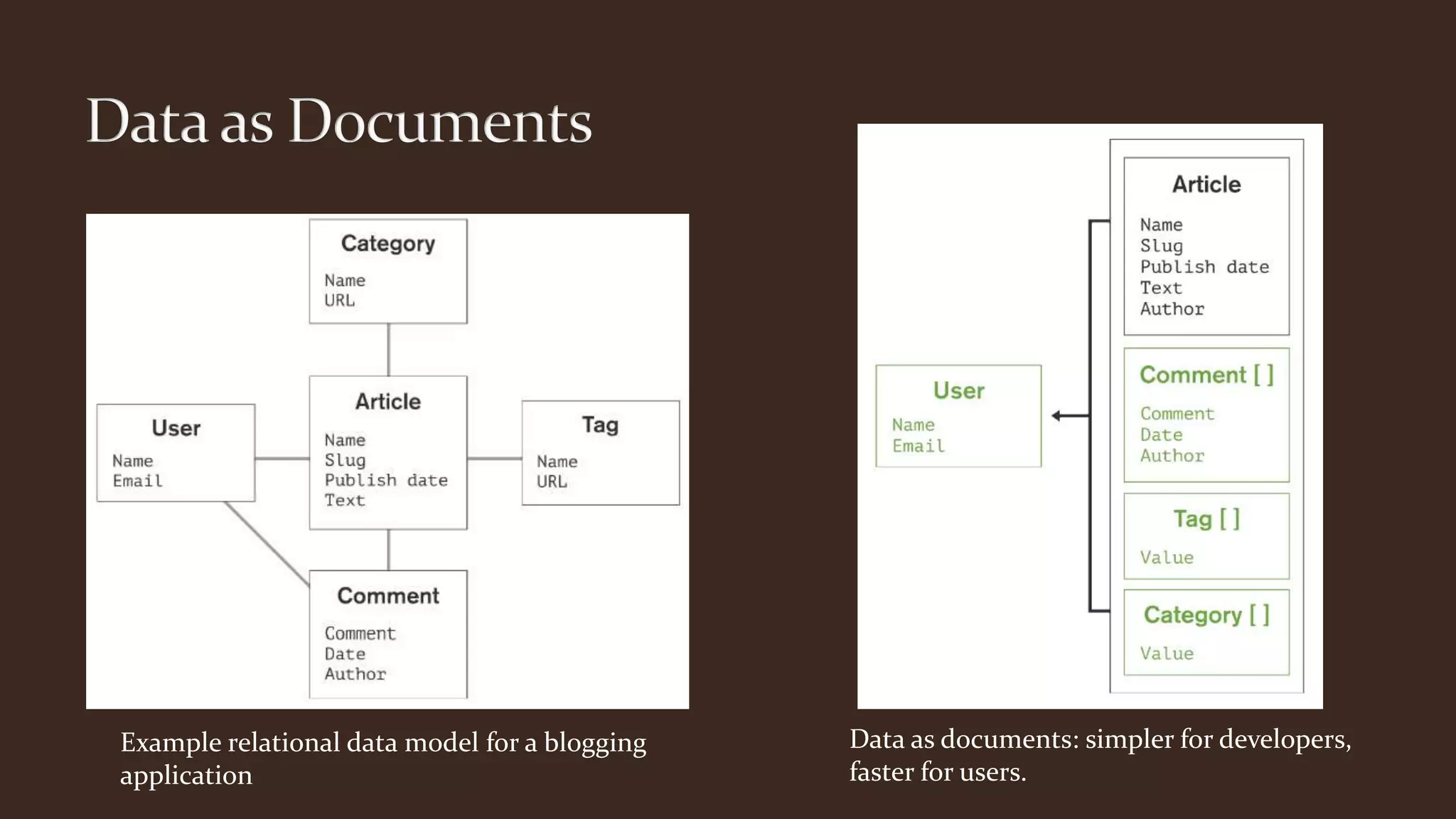
This document summarizes key aspects of MongoDB including its data model, query language, and data management features. It discusses how MongoDB uses storage engines to manage data storage and supports different engines for different workloads. It also covers MongoDB's dynamic and flexible schema, data modeling approaches using embedded documents, and core tools for importing, exporting, and diagnosing MongoDB deployments.




















































![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)



![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)