Download to read offline























![Benchmarks Won’t
Find Everything
•[RocksDB] Prefix collision could happen between
restarts
https://github.com/mongodb-partners/mongo/
commit/
da8a90b3b71bf291684ffc5a6d2fd32118ce1a7b
•[MongoDB] Secondary reads block replication
https://jira.mongodb.org/browse/SERVER-18190](https://image.slidesharecdn.com/mongobenchmarkingcopy-150605202722-lva1-app6891/75/Benchmarking-Load-Testing-and-Preventing-Terrible-Disasters-30-2048.jpg)
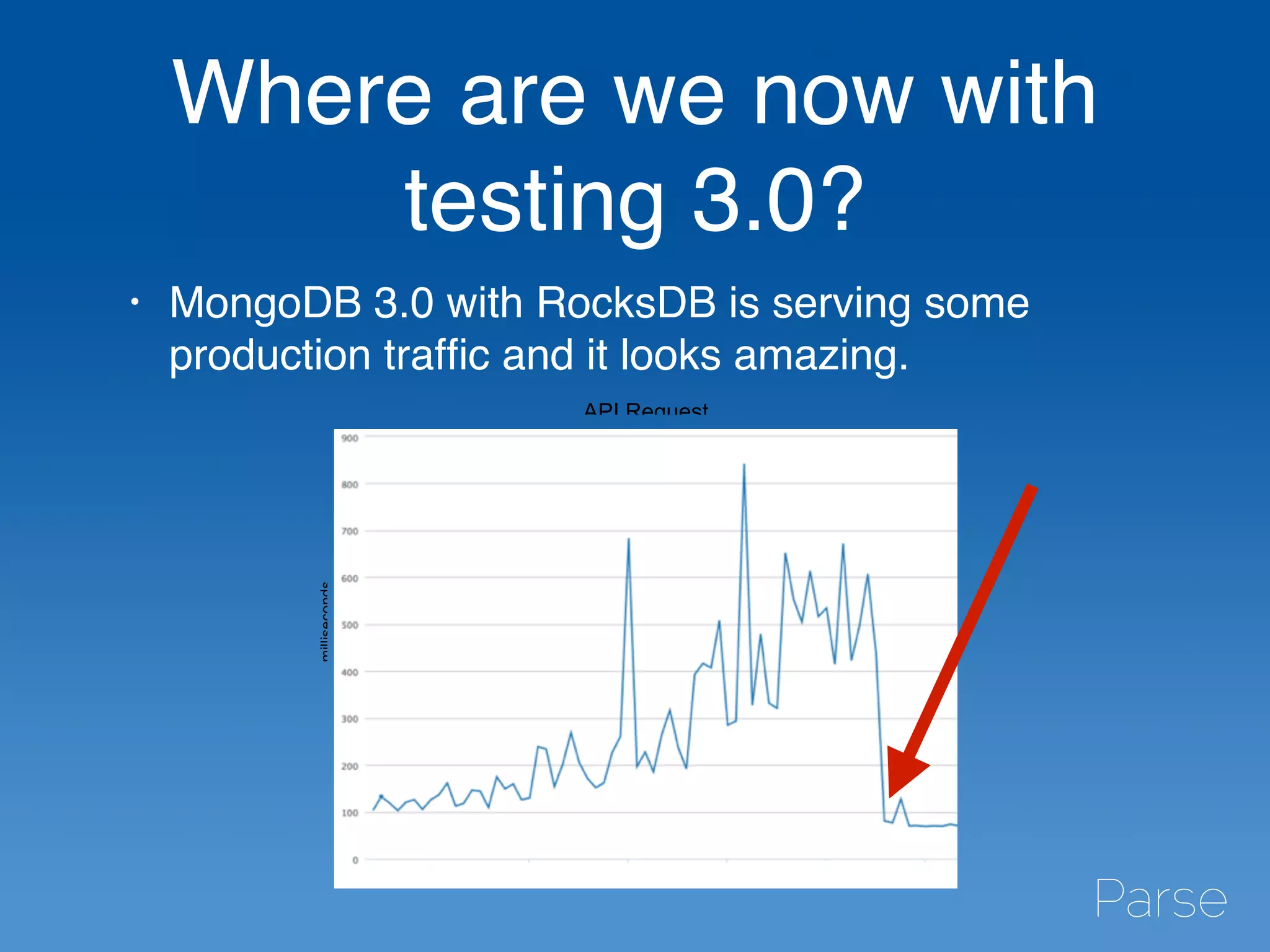


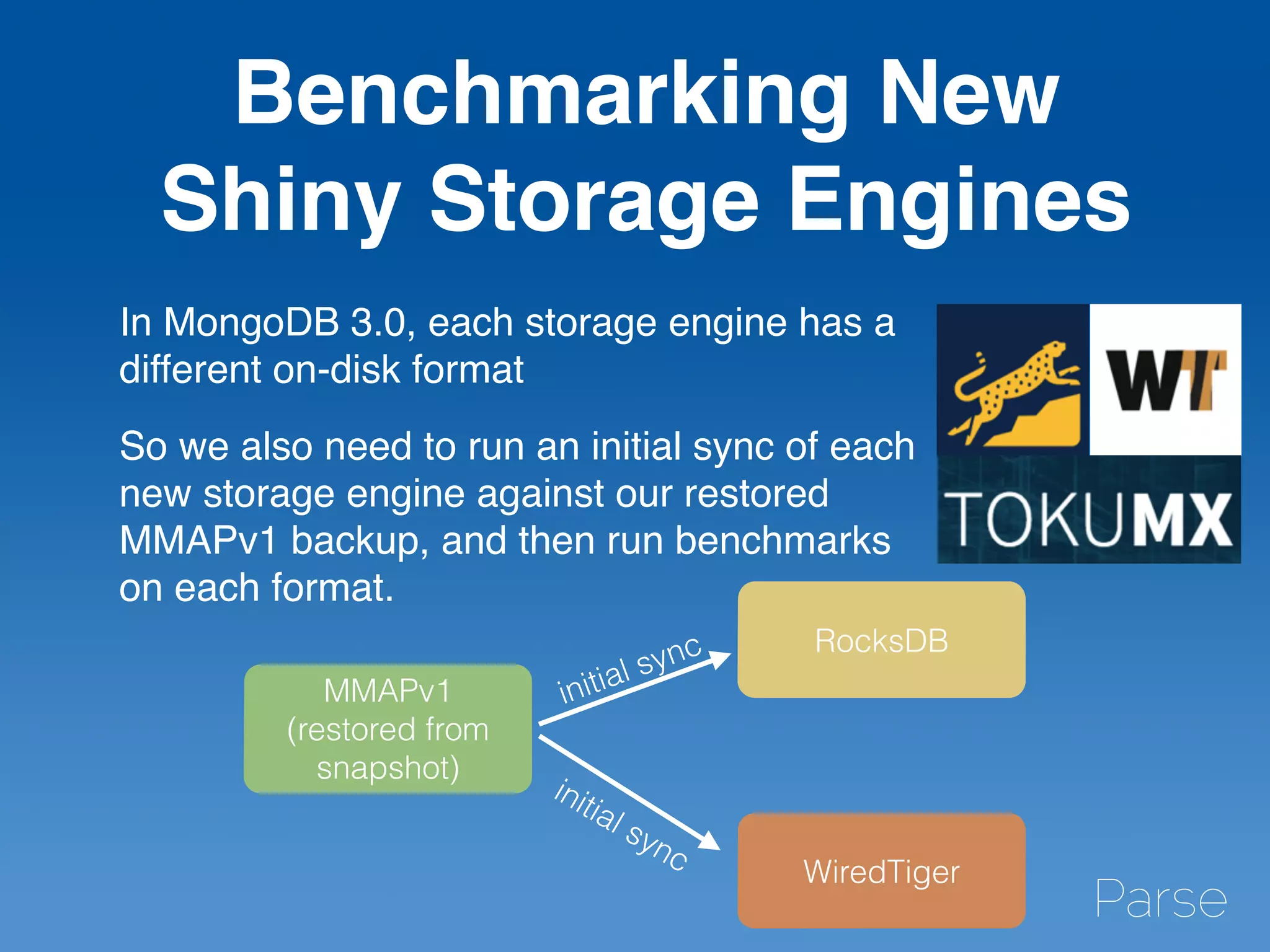
The document discusses Mike Kania's experiences and insights as a production engineer at Parse, focusing on benchmarking and load testing with MongoDB. It outlines the complexities of Parse's infrastructure, including processes for upgrading MongoDB versions, potential performance issues, and the use of open-source tools for capturing workloads. Additionally, it provides details on how Parse has implemented storage solutions, benchmarking strategies, and the performance comparisons between different storage engines in MongoDB 3.0.
















![[AWSKRUG&JAWS-UG Meetup #1] 70% Cost Reduction with On-demand resizing](https://cdn.slidesharecdn.com/ss_thumbnails/awsjawsondemandresizing-160526114219-thumbnail.jpg?width=640&height=640&fit=bounds)











































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)













![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)







