Download as PDF, PPTX



![mongo console
$ ~/Work/opt/mongodb-‐1.6.5/bin/mongod
-‐-‐dbpath=~/Work/src/nosqlday/db/mongodb.01
-‐-‐logpath=~/Work/src/nosqlday/log/mongodb.01
-‐-‐fork -‐-‐port 30001
$ ~/Work/opt/mongodb-‐1.6.5/bin/mongo localhost:30001
MongoDB shell version: 1.6.5
connecting to: localhost:30001/test
> use nosqlday
switched to db nosqlday
> db.getCollectionNames()
[ "system.indexes", "users" ]
> db.users.find({ "name": "Gabriele" })
{ "_id" : ObjectId("4d8706767bb037a8a8f98db2"), "name" : "Gabriele",
"surname" : "Lana", "job" : "softwarecraftsman" }
> exit
bye](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-3-320.jpg)
![ruby driver
require "mongo"
db = Mongo::Connection.new("localhost", 30001).db("nosqlday")
puts "Collections:"
db.collections.each do |collection|
puts "t#{collection.name}"
end
puts "Gabriele:"
db["users"].find(:name => "Gabriele").each do |user|
puts "t#{user["_id"]}"
end
db.connection.close](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-4-320.jpg)
![ruby driver
require "mongo"
db = Mongo::Connection.new("localhost", 30001).db("nosqlday")
puts "Collections:"
db.collections.each do |collection|
puts "t#{collection.name}"
$ ruby src/connect.rb
Collections:
end users
system.indexes
Gabriele:
puts "Gabriele:" 4d8706767bb037a8a8f98db2
db["users"].find(:name => "Gabriele").each do |user|
puts "t#{user["_id"]}"
end
db.connection.close](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-5-320.jpg)



![puts "Gabriele:"
db["users"].find(:name => "Gabriele").each do |user|
puts "t#{user["_id"]}"
end
puts "Gabriele:"
db["users"].select{|user| user["name"] == "Gabriele"}.each do |user|
puts "t#{user["_id"]}"
end
mongo
smart driver](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-9-320.jpg)
![puts "Gabriele:"
db["users"].find(:name => "Gabriele").each do |user|
puts "t#{user["_id"]}"
end
puts "Gabriele:"
$ ruby src/find_vs_select.rb
db["users"].select{|user| user["name"] == "Gabriele"}.each do |user|
Gabriele:
puts "t#{user["_id"]}" 4d8706767bb037a8a8f98db2
Gabriele:
end 4d8706767bb037a8a8f98db2
mongo
smart driver](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-10-320.jpg)
![puts "Gabriele:"
db["users"].find(:name => "Gabriele").each do |user|
puts "t#{user["_id"]}"
end
puts "Gabriele:"
db["users"].select{|user| user["name"] == "Gabriele"}.each do |user|
puts "t#{user["_id"]}"
end
mongo
smart driver](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-11-320.jpg)




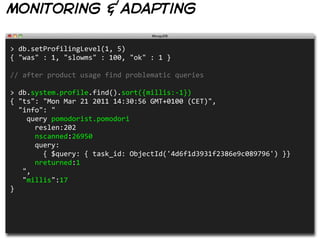
![monitoring & adapting
> db.pomodori.find({
$query: { task_id: ObjectId('4d6f1d3931f2386e9c089796') },
$explain: true
})
{ "cursor": "BasicCursor",
"nscanned": 26950,
"nscannedObjects": 26950,
"n": 1,
"millis": 17,
"indexBounds": { },
"allPlans": [
{ "cursor" : "BasicCursor", "indexBounds" : { } }
]
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-17-320.jpg)
![monitoring & adapting
> db.pomodori.ensureIndex({"task_id": 1})
> db.pomodori.find({
$query: { task_id: ObjectId('4d6f1d3931f2386e9c089796') },
$explain: true
})
{ "cursor": "BtreeCursor task_id_1",
"nscanned": 1,
"nscannedObjects": 1,
"n": 1,
"millis": 0,
"indexBounds": {
"task_id": [
[
ObjectId("4d6f1d3931f2386e9c089796"),
ObjectId("4d6f1d3931f2386e9c089796")
]
]}, "allPlans": [...]
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-18-320.jpg)


![retrieve all objects with $in
users = [
{:name => "Gabriele", :surname => "Lana", :job => "softwarecraftsman"},
{:name => "Federico", :surname => "Galassi", :job => "softwarecraftsman"},
{:name => "Giordano", :surname => "Scalzo", :job => "softwarecraftsman"}
]
ids = users.map{|user| db["users"].insert(user)}
puts ids.map{|id| db["users"].find_one(:_id => id)}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-21-320.jpg)
![retrieve all objects with $in
users = [
{:name => "Gabriele", :surname => "Lana", :job => "softwarecraftsman"},
{:name => "Federico", :surname => "Galassi", :job => "softwarecraftsman"},
{:name => "Giordano", :surname => "Scalzo", :job => "softwarecraftsman"}
]
$ ruby src/find_by_all_ids.rb
{"_id"=>BSON::ObjectId('4d87605731f23824a0000001'), ...}
ids = users.map{|user| db["users"].insert(user)}
{"_id"=>BSON::ObjectId('4d87605731f23824a0000002'), ...}
{"_id"=>BSON::ObjectId('4d87605731f23824a0000003'), ...}
puts ids.map{|id| db["users"].find_one(:_id => id)}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-22-320.jpg)
![retrieve all objects with $in
users = [
{:name => "Gabriele", :surname => "Lana", :job => "softwarecraftsman"},
{:name => "Federico", :surname => "Galassi", :job => "softwarecraftsman"},
{:name => "Giordano", :surname => "Scalzo", :job => "softwarecraftsman"}
]
ids = users.map{|user| db["users"].insert(user)}
puts ids.map{|id| db["users"].find_one(:_id => id)}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-23-320.jpg)
![retrieve all objects with $in
users = [
{:name => "Gabriele", :surname => "Lana", :job => "softwarecraftsman"},
{:name => "Federico", :surname => "Galassi", :job => "softwarecraftsman"},
{:name => "Giordano", :surname => "Scalzo", :job => "softwarecraftsman"}
]
ids = users.map{|user| db["users"].insert(user)}
ids = db["users"].insert(users)
puts ids.map{|id| db["users"].find_one(:_id => id)}
puts db["users"].find(:_id => {:$in => ids}).all](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-24-320.jpg)
![retrieve all objects with $in
users = [
{:name => "Gabriele", :surname => "Lana", :job => "softwarecraftsman"},
{:name => "Federico", :surname => "Galassi", :job => "softwarecraftsman"},
{:name => "Giordano", :surname => "Scalzo", :job => "softwarecraftsman"}
]
$ ruby src/find_by_all_ids.rb
{"_id"=>BSON::ObjectId('4d87605731f23824a0000001'), ...}
ids = users.map{|user| db["users"].insert(user)}
{"_id"=>BSON::ObjectId('4d87605731f23824a0000002'), ...}
ids = db["users"].insert(users)
{"_id"=>BSON::ObjectId('4d87605731f23824a0000003'), ...}
puts ids.map{|id| db["users"].find_one(:_id => id)}
puts db["users"].find(:_id => {:$in => ids}).all](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-25-320.jpg)


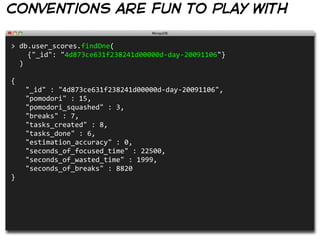
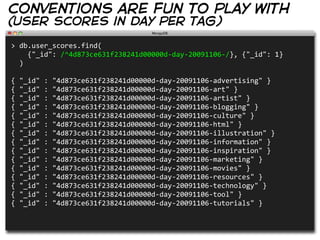
![conventions are fun to play with
(list of tags per day)
> db.user_scores.find(
{"_id": /^4d873ce631f238241d00000d-‐day-‐20091106-‐/}, {"_id": 1}
).map(function(document) {
return document._id.replace(
"4d873ce631f238241d00000d-‐day-‐20091106-‐", ""
)
})
[
"advertising",
"art",
"artist",
"blogging",
"culture",
"html",
"illustration",
"information",
...
]](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-30-320.jpg)
![conventions are fun to play with
(anchored regexp uses indexes)
> db.user_scores.find(
{"_id": /^4d873ce631f238241d00000d-‐day-‐20091106-‐/}, {"_id": 1}
).explain()
{
"cursor" : "BtreeCursor _id_ multi",
"nscanned" : 15,
"nscannedObjects" : 15,
"n" : 15,
"millis" : 0,
"indexBounds" : {
"_id" : [
[
"4d873ce631f238241d00000d-‐day-‐20091106-‐",
"4d873ce631f238241d00000d-‐day-‐20091106."
],
[
/^4d873ce631f238241d00000d-‐day-‐20091106-‐/,
/^4d873ce631f238241d00000d-‐day-‐20091106-‐/
]
]](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-31-320.jpg)
![conventions are fun to play with
(anchored regexp uses indexes)
> db.user_scores.find(
{"_id": /4d873ce631f238241d00000d-‐day-‐20091106-‐/}, {"_id": 1}
).explain()
{
"cursor" : "BtreeCursor _id_ multi",
"nscanned" : 109349,
"nscannedObjects" : 15,
"n" : 15,
"millis" : 217,
"indexBounds" : {
"_id" : [
...
]
}
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-32-320.jpg)

![group to compute data in mongo
(inject client side)
days = [ 20091110, 20091111, 20091112 ]
scores_id = %r{^4d87d00931f2380c7700000d-day-(#{days.join("|")})$}
scores = db["user_scores"].find(:_id => scores_id)
pomodori = scores.inject(0) do |pomodori, scores|
pomodori + scores["pomodori"]
end
puts "Pomodori in days #{days.join(",")}: #{pomodori}"](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-34-320.jpg)
![group to compute data in mongo
(inject client side)
days = [ 20091110, 20091111, 20091112 ]
scores_id = %r{^4d87d00931f2380c7700000d-day-(#{days.join("|")})$}
scores = db["user_scores"].find(:_id => scores_id)
pomodori = scores.inject(0) do |pomodori, scores|
$ ruby src/inject_for_reduce.rb
pomodori + scores["pomodori"]
Pomodori in days 20091110,20091111,20091112: 36
end
puts "Pomodori in days #{days.join(",")}: #{pomodori}"](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-35-320.jpg)
![group to compute data in mongo
(group server side)
days = [ 20091110, 20091111, 20091112 ]
scores_id = %r{^4d87d00931f2380c7700000d-day-(#{days.join("|")})$}
result = db["user_scores"].group(
:cond => { :_id => scores_id },
:initial => { :pomodori => 0 },
:reduce => <<-EOF
function(document, result) {
result.pomodori += document.pomodori
}
EOF
)
puts "Pomodori in days #{days.join(",")}: #{result.first["pomodori"]}"](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-36-320.jpg)
![group to compute data in mongo
(group server side)
days = [ 20091110, 20091111, 20091112 ]
scores_id = %r{^4d87d00931f2380c7700000d-day-(#{days.join("|")})$}
result = db["user_scores"].group(
:cond => { :_id => scores_id },
:initial => { :pomodori => 0 },
:reduce => <<-EOF $ ruby src/group_for_reduce.rb
Pomodori in days 20091110,20091111,20091112: 36
function(document, result) {
result.pomodori += document.pomodori
}
EOF
)
puts "Pomodori in days #{days.join(",")}: #{result.first["pomodori"]}"](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-37-320.jpg)
![group to compute data in mongo
(ex. sum pomodori by tag “ruby”)
result = db["user_scores"].group(
:cond => {
:_id => /^4d87d00931f2380c7700000d-day-d{8}-ruby$/
},
:initial => { :pomodori => 0, :days => 0 },
:reduce => <<-EOF
function(document, result) {
result.days += 1
result.pomodori += document.pomodori
}
EOF
).first
puts "In #{result["days"]} days, #{result["pomodori"]} done for ruby"](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-38-320.jpg)
![group to compute data in mongo
(ex. sum pomodori by tag “ruby”)
result = db["user_scores"].group(
:cond => {
:_id => /^4d87d00931f2380c7700000d-day-d{8}-ruby$/
},
:initial => { :pomodori => 0, :days => 0 },
:reduce => <<-EOF
function(document, result) {
$ ruby src/group_for_ruby_tag.rb
In 43 days, 45 pomodori
result.days += 1
result.pomodori += document.pomodori
}
EOF
).first
puts "In #{result["days"]} days, #{result["pomodori"]} pomodori"](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-39-320.jpg)
![group to compute data in mongo
(ex. sum pomodori by tag “ruby”)
> db.user_scores.find({
"_id": /^4d87d00931f2380c7700000d-‐day-‐d{8}-‐ruby$/
}).explain()
{
"cursor" : "BtreeCursor _id_ multi",
"nscanned" : 43,
"nscannedObjects" : 43,
"n" : 43,
"millis" : 3,
"indexBounds" : {
"_id" : [...]
}
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-40-320.jpg)

![reverse index in place
(an array could be indexed)
> db.tasks.find({ "tags": { $in: [ "nosqlday" ] } })
{ "_id" : ObjectId("4d7de446175ca8243d000004"),
"tags" : [ "nosqlday" ],
"description" : "#nosqlday keynote",
"is_recurrent" : false,
"estimated" : 0,
"worked_in" : [
"Mon Mar 14 2011 00:00:00 GMT+0100 (CET)",
"Tue Mar 15 2011 00:00:00 GMT+0100 (CET)"
],
"done_at" : "Tue Mar 15 2011 13:05:03 GMT+0100 (CET)",
"todo_at" : null,
"created_at" : "Mon Mar 14 2011 10:47:50 GMT+0100 (CET)",
"updated_at" : "Tue Mar 15 2011 13:05:03 GMT+0100 (CET)",
"keywords": [ "nosqldai", "keynot" ],
"user_id": ObjectId("4d53996c137ce423ff000001"),
"annotations" : [ ]
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-42-320.jpg)
![reverse index in place
(an array could be indexed)
> db.tasks.getIndexes()
[
{
"name" : "_id_",
"ns" : "app435386.tasks",
"key" : {
"_id" : 1
}
},
{
"name" : "tags_1",
"ns" : "app435386.tasks",
"key" : {
"tags" : 1
},
"unique" : false
},
...
]](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-43-320.jpg)
![reverse index in place
(container for deduced data, array)
db["orders"].insert({
:placed_at => [
now.strftime("%Y"), # year: "2011"
now.strftime("%Y%m"), # month: "201103"
now.strftime("%Yw%U"), # week: "2011w11"
now.strftime("%Y%m%d") # day: "20110316"
],
:user_id => user,
:items => items_in_order.map{|item| item[:id]},
:total => items_in_order.inject(0){|total,item| total += item[:price]}
})
# ...
db["orders"].ensure_index([["placed_at", Mongo::DESCENDING]])](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-44-320.jpg)
![reverse index in place
(container for deduced data, array)
> db.orders.findOne()
{ "_id" : ObjectId("4d88bf1f31f23812de0003fd"),
"placed_at" : [ "2011", "201103", "2011w11", "20110316" ],
"user_id" : ObjectId("4d88bf1f31f23812de0003e9"),
"items" : [
ObjectId("4d88bf1f31f23812de0003da"),
ObjectId("4d88bf1f31f23812de000047"),
ObjectId("4d88bf1f31f23812de000078"),
ObjectId("4d88bf1f31f23812de000068"),
ObjectId("4d88bf1f31f23812de000288")
],
"total" : 3502
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-45-320.jpg)
![reverse index in place
(container for deduced data, array)
> db.orders.find({ "placed_at": "20110310" }).count()
77
> db.orders.find({ "placed_at": "20110310" }).explain()
{
"cursor" : "BtreeCursor placed_at_-‐1",
"nscanned" : 77,
"nscannedObjects" : 77,
"n" : 77,
"millis" : 0,
"indexBounds" : {
"placed_at" : [
[
"20110310",
"20110310"
]
]
}
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-46-320.jpg)
![reverse index in place
(container for deduced data, hash)
db["orders"].insert({
:placed_at => [
{ :year => now.strftime("%Y") },
{ :month => now.strftime("%Y%m") },
{ :week => now.strftime("%Y%U") },
{ :day => now.strftime("%Y%m%d") }
],
:user_id => user,
:items => items_in_order.map{|item| item[:id]},
:total => items_in_order.inject(0){|total,item| total += item[:price]}
})
# ...
db["orders"].ensure_index([["placed_at", Mongo::DESCENDING]])](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-47-320.jpg)
![reverse index in place
(container for deduced data, hash)
> db.orders.findOne()
{ "_id" : ObjectId("4d88c31531f23812fe0003ea"),
"placed_at" : [
{ "year" : "2009" },
{ "month" : "200911" },
{ "week" : "200945" },
{ "day" : "20091109" }
],
"user_id" : ObjectId("4d88c31531f23812fe0003e9"),
"items" : [
ObjectId("4d88c31531f23812fe00013f"),
ObjectId("4d88c31531f23812fe000176"),
ObjectId("4d88c31531f23812fe0003e2"),
ObjectId("4d88c31531f23812fe0003d1"),
ObjectId("4d88c31531f23812fe0001c1"),
ObjectId("4d88c31531f23812fe000118"),
ObjectId("4d88c31531f23812fe00031d")
],
"total" : 10149
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-48-320.jpg)
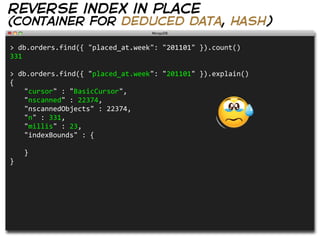
![reverse index in place
(container for deduced data, hash)
> db.orders.find({ "placed_at": { "week": "201101" }}).count()
331
> db.orders.find({ "placed_at": { "week": "201101" }}).explain()
{
"cursor" : "BtreeCursor placed_at_-‐1",
"nscanned" : 331,
"nscannedObjects" : 331,
"n" : 331,
"millis" : 0,
"indexBounds" : {
"placed_at" : [
[
{ "week" : "2011w01" },
{ "week" : "2011w01" }
]
]
}
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-50-320.jpg)

![plain dates are good too
db["orders"].insert({
:placed_at => now,
:user_id => user,
:items => items_in_order.map{|item| item[:id]},
:total => items_in_order.inject(0){|total,item| total += item[:price]}
})
# ...
db["orders"].ensure_index([["placed_at", Mongo::DESCENDING]])](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-52-320.jpg)
![plain dates are good too
> db.orders.findOne()
{
"_id" : ObjectId("4d88d1f931f23813a10003ea"),
"placed_at" : "Mon Nov 09 2009 08:00:00 GMT+0100 (CET)",
"user_id" : ObjectId("4d88d1f931f23813a10003e9"),
"items" : [
ObjectId("4d88d1f931f23813a100016d"),
ObjectId("4d88d1f931f23813a1000346"),
ObjectId("4d88d1f931f23813a10001e7"),
ObjectId("4d88d1f931f23813a10000db"),
ObjectId("4d88d1f931f23813a1000091"),
ObjectId("4d88d1f931f23813a10001c1"),
ObjectId("4d88d1f931f23813a10001d3"),
ObjectId("4d88d1f931f23813a100031b"),
ObjectId("4d88d1f931f23813a1000130")
],
"total" : 5871
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-53-320.jpg)
![plain dates are good too
> db.orders.find({
"placed_at": {
$gte: new Date(2011,2,10),
$lt: new Date(2011,2,11)
}
}).explain()
{
"cursor" : "BtreeCursor placed_at_-‐1",
"nscanned" : 53,
"nscannedObjects" : 53,
"n" : 53,
"millis" : 0,
"indexBounds" : {
"placed_at" : [
[
"Fri Mar 11 2011 00:00:00 GMT+0100 (CET)",
"Thu Mar 10 2011 00:00:00 GMT+0100 (CET)"
]
]
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-54-320.jpg)
![plain dates are good too, but...
(total sold on this year’s mondays)
# find all mondays of the year
now = Time.now.beginning_of_year
now += 1.day until now.monday?
mondays = [ now ]
mondays << now += 7.days while now.year == Time.now.year
# find all orders placed on mondays
query = {
:$or => mondays.map do |day|
{ :placed_at => {
:$gte => day.beginning_of_day,
:$lte => day.end_of_day
}
}
end
}
puts query](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-55-320.jpg)
![plain dates are good too, but...
(total sold on this year’s mondays)
# find all mondays of the year
now = Time.now.beginning_of_year
now += 1.day until now.monday?
mondays = [ now ]
mondays << now += 7.days while now.year == Time.now.year
$ ruby src/orders_on_mondays.rb
# find all orders placed on mondays
{:$or=>[
query = { {:placed_at=>{
:$or => mondays.map do |day|
:$gte=>2011-‐01-‐03 00:00:00 +0100,
{ :placed_at => { :$lte=>2011-‐01-‐03 23:59:59 +0100
}},
:$gte => day.beginning_of_day,
{:placed_at=>{
:$lte => day.end_of_day
:$gte=>2011-‐01-‐10 00:00:00 +0100,
:$lte=>2011-‐01-‐10 23:59:59 +0100
} }},
} {:placed_at=>{
:$gte=>2011-‐01-‐17 00:00:00 +0100,
end :$lte=>2011-‐01-‐17 23:59:59 +0100
} }},
...
]}
puts query](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-56-320.jpg)
![plain dates are good too, but...
(it works but it’s too slooow)
db["orders"].find({
:$or => mondays.map do |day|
{ :placed_at => {
:$gte => day.beginning_of_day,
:$lte => day.end_of_day
}
}
end
})](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-57-320.jpg)
![plain dates are good too, but...
(why it’s too slow)
> db.orders.find({
$or: [
"placed_at":{ $gte: new Date(2011,2,3), $lt: new Date(2011,2,4) },
"placed_at":{ $gte: new Date(2011,2,10), $lt: new Date(2011,2,11) }
]
}).explain()
{
"clauses" : [{
"cursor" : "BtreeCursor placed_at_-‐1",
"indexBounds" : {
"placed_at" : [[
"Tue Mar 3 2011 00:00:00 GMT+0100 (CET)",
"Wed Mar 4 2011 00:00:00 GMT+0100 (CET)"
]]}
}, {
"cursor" : "BtreeCursor placed_at_-‐1",
"indexBounds" : {
"placed_at" : [[
"Tue Mar 10 2011 00:00:00 GMT+0100 (CET)",
"Wed Mar 11 2011 00:00:00 GMT+0100 (CET)"](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-58-320.jpg)
![with destructured dates
(total sold on mondays this year)
> db.orders.findOne()
{ "_id" : ObjectId("4d88bf1f31f23812de0003fd"),
"placed_at" : [ "2011", "201103", "2011w11", "20110316" ],
"user_id" : ObjectId("4d88bf1f31f23812de0003e9"),
"items" : [
ObjectId("4d88bf1f31f23812de0003da"),
ObjectId("4d88bf1f31f23812de000047"),
ObjectId("4d88bf1f31f23812de000078"),
ObjectId("4d88bf1f31f23812de000068"),
ObjectId("4d88bf1f31f23812de000288")
],
"total" : 3502
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-59-320.jpg)
![with destructured dates
(total sold on mondays this year)
now = Time.now.beginning_of_year
now += 1.day until now.monday?
mondays = [ now ]
mondays << now += 7.days while now.year == Time.now.year
orders = db["orders"].find({
:placed_at => {
:$in => mondays.map {|day| day.strftime("%Y%m%d")}
}
})
puts orders.explain](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-60-320.jpg)
![with destructured dates
(total sold on mondays this year)
now = Time.now.beginning_of_year
now += 1.day until now.monday?
mondays = [ now ]
mondays << now += 7.days while now.year == Time.now.year
orders = db["orders"].find({
$ ruby src/orders_on_mondays.rb
:placed_at => {
{ "cursor"=>"BtreeCursor placed_at_-‐1 multi",
:$in => mondays.map "nscanned"=>744,
{|day| day.strftime("%Y%m%d")}
} "nscannedObjects"=>744,
"n"=>744,
}) "millis"=>1,
"indexBounds"=>{
"placed_at"=>[
puts orders.explain ["20120102", "20120102"], ["20111226", "20111226"],
["20111219", "20111219"], ["20111212", "20111212"],
["20111205", "20111205"], ["20111128", "20111128"],
["20111121", "20111121"], ...
]
}
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-61-320.jpg)

![pomodori
(find who is ticking)
> db.pomodori.findOne()
{
"_id" : ObjectId("4d8916ed31f2381480000021"),
"duration" : 1500,
"interruptions" : 0,
"after_break_of" : 0,
"started_at" : "Mon Mar 14 2011 08:05:00 GMT+0100 (CET)",
"squashed_at" : "Mon Mar 14 2011 08:07:31 GMT+0100 (CET)",
"in_day" : {
"position" : 1,
"is_last" : false
},
"task_id" : ObjectId("4d8916ec31f2381480000014"),
"user_id" : ObjectId("4d8916ec31f2381480000010"),
"annotations" : [ ]
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-63-320.jpg)
![pomodori
(find who is ticking)
now = Time.now.yesterday.beginning_of_day + 10.hours
timestamp_of_now = now.to_i
ticking = db["pomodori"].find(
:$where => <<-EOF
var startedAt = this.started_at.getTime()/1000
return
((startedAt + this.duration) > #{timestamp_of_now}) &&
(startedAt < #{timestamp_of_now})
EOF
)
puts ticking.map{|pomodoro| pomodoro["_id"]}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-64-320.jpg)
![pomodori
(find who is ticking)
now = Time.now.yesterday.beginning_of_day + 10.hours
timestamp_of_now = now.to_i
ticking = db["pomodori"].find(
:$where => <<-EOF
var startedAt = this.started_at.getTime()/1000
return $ ruby src/find_who_is_ticking.rb
4d8916ef31f238148000011d
((startedAt + this.duration) > #{timestamp_of_now}) &&
4d8916f231f2381480000271
(startedAt < #{timestamp_of_now})
4d8916f931f23814800004dd
4d8916f931f23814800004e0
EOF
)
puts ticking.map{|pomodoro| pomodoro["_id"]}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-65-320.jpg)
![pomodori
(find who is ticking for an user)
now = Time.now.yesterday.beginning_of_day + 10.hours
timestamp_of_now = now.to_i
user_id = BSON::ObjectId.from_string("4d8916ec31f2381480000010")
ticking = db["pomodori"].find(
:user_id => user_id,
:$where => <<-EOF
var startedAt = this.started_at.getTime()/1000
return
((startedAt + this.duration) > #{timestamp_of_now}) &&
(startedAt < #{timestamp_of_now})
EOF
)
puts ticking.map{|pomodoro| pomodoro["_id"]}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-66-320.jpg)
![pomodori
(find who is ticking for an user)
now = Time.now.yesterday.beginning_of_day + 10.hours
timestamp_of_now = now.to_i
user_id = BSON::ObjectId.from_string("4d8916ec31f2381480000010")
ticking = db["pomodori"].find(
:user_id => user_id,
:$where => <<-EOF $ ruby src/find_who_is_ticking_for_an_user.rb
4d8916ef31f238148000011d
var startedAt = this.started_at.getTime()/1000
return
((startedAt + this.duration) > #{timestamp_of_now}) &&
(startedAt < #{timestamp_of_now})
EOF
)
puts ticking.map{|pomodoro| pomodoro["_id"]}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-67-320.jpg)
![pomodori
(related to tasks tagged with “maps”)
related_to_maps = db["pomodori"].find(
:$where => <<-EOF
db.tasks.findOne({ "_id": this.task_id }).tags.indexOf("maps") >= 0
EOF
)
puts related_to_maps.map{|pomodoro| pomodoro["_id"]}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-68-320.jpg)
![pomodori
(related to tasks tagged with “maps”)
related_to_maps = db["pomodori"].find(
:$where => <<-EOF
db.tasks.findOne({ "_id": this.task_id }).tags.indexOf("maps") >= 0
EOF
)
$ ruby src/related_to_maps.rb
puts related_to_maps.map{|pomodoro| pomodoro["_id"]}
4d8916fa31f2381480000579
4d8916fa31f238148000057b
4d8916fa31f238148000057d
4d8916fa31f2381480000580](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-69-320.jpg)
![pomodori
(don’t be carried away :-))
related_to_maps = db["pomodori"].find(
:$where => <<-EOF
db.tasks.findOne({ "_id": this.task_id }).tags.indexOf("maps") >= 0
EOF
)
$ ruby src/related_to_maps.rb
puts related_to_maps.explain
{ "cursor"=>"BasicCursor",
"nscanned"=>461,
"nscannedObjects"=>461,
"n"=>4,
"millis"=>52,
"indexBounds"=>{},
"allPlans"=>[...]
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-70-320.jpg)
![pomodori
(related to... a better solution)
related_to_maps = db["pomodori"].find(:task_id => {
:$in => db["tasks"].find(
{:tags => "maps"}, :fields => {:_id => 1}
).map{|task| task["_id"]}
})
$ ruby src/related_to_maps.rb
4d8916fa31f2381480000579
puts related_to_maps.map{|pomodoro| pomodoro["_id"]}
4d8916fa31f238148000057b
4d8916fa31f238148000057d
4d8916fa31f2381480000580](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-71-320.jpg)
![pomodori
(related to... a better solution)
related_to_maps = db["pomodori"].find(:task_id => {
:$in => db["tasks"].find(
{:tags => "maps"}, :fields => {:_id => 1}
).map{|task| task["_id"]}
})
$ ruby src/related_to_maps.rb
{ "cursor"=>"BtreeCursor tags_1",
puts related_to_maps.map{|pomodoro| pomodoro["_id"]}
"nscanned"=>3,
"nscannedObjects"=>3,
"n"=>3,
"millis"=>0,
...
}
{ "cursor"=>"BtreeCursor task_id_1 multi",
"nscanned"=>4,
"nscannedObjects"=>4,
"n"=>4,
"millis"=>0,
...
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-72-320.jpg)

![keep track of url’s visits
(upsert with custom id)
result = db["visits"].update(
{ :_id => Digest::MD5.hexdigest(url) },
{ :$inc => { :hits => 1 } },
:upsert => true,
:safe => true
)
puts "Update: #{result.inspect}"
puts db["visits"].find_one(:_id => Digest::MD5.hexdigest(url))](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-74-320.jpg)
![keep track of url’s visits
(upsert with custom id)
result = db["visits"].update(
{ :_id => Digest::MD5.hexdigest(url) },
{ :$inc => { :hits => 1 } },
:upsert => true,
:safe => true
)
$ ruby src/realtime_analytics.rb
Update: {
puts "Update: #{result.inspect}"
"err"=>nil,
"updatedExisting"=>false,
"n"=>1,
puts db["visits"].find_one(:_id => Digest::MD5.hexdigest(url))
"ok"=>1.0
}
{"_id"=>"2d86a774beffe90e715a8028c7bd177b", "hits"=>1}
$ ruby src/realtime_analytics.rb
Update: {
"err"=>nil,
"updatedExisting"=>true,
"n"=>1,
"ok"=>1.0
}
{"_id"=>"2d86a774beffe90e715a8028c7bd177b", "hits"=>2}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-75-320.jpg)
![url’s visits aggregated by time
(upsert with multiple documents)
url_digest = Digest::MD5.hexdigest(url)
ids = [
[ url_digest, Time.now.strftime("%Y%m%d") ].join("-"),
[ url_digest, Time.now.strftime("%Y%m") ].join("-"),
[ url_digest, Time.now.strftime("%Y") ].join("-"),
[ url_digest, user_id ].join("-")
]
puts "Expect to upsert: n#{ids}"
result = db["visits"].update(
{ :_id => { :$in => ids } },
{ :$inc => { :hits => 1 } },
:multi => true,
:upsert => true,
:safe => true
)
puts result.inspect
puts db["visits"].all](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-76-320.jpg)
![url’s visits aggregated by time
(upsert with multiple documents)
url_digest = Digest::MD5.hexdigest(url)
ids = [
[ url_digest, Time.now.strftime("%Y%m%d") ].join("-"),
[ url_digest, Time.now.strftime("%Y%m") ].join("-"),
[ url_digest, Time.now.strftime("%Y") ].join("-"),
[ url_digest, user_id ].join("-")
] $ ruby src/realtime_analytics_with_aggregation.rb
Expect to upsert:[
puts "Expect to upsert: "2d86a774beffe90e715a8028c7bd177b-‐20110323",
n#{ids}"
"2d86a774beffe90e715a8028c7bd177b-‐201103",
"2d86a774beffe90e715a8028c7bd177b-‐2011",
result = db["visits"].update(
"2d86a774beffe90e715a8028c7bd177b-‐4d899fab31f238165c000001"
{ :_id => { :$in => ids } },
]
{ :$inc => { :hits => { "err"=>nil,
1 } },
:multi => true, "updatedExisting"=>false,
"upserted"=>BSON::ObjectId('4d899fabe23bd37e768ae76d'),
:upsert => true, "n"=>1,
:safe => true "ok"=>1.0
}
)
puts result.inspect {"_id"=>BSON::ObjectId('4d899fabe23bd37e768ae76d'), "hits"=>1}
puts db["visits"].all](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-77-320.jpg)
![url’s visits aggregated by time
(upsert with multiple documents)
url_digest = Digest::MD5.hexdigest(url)
ids = [
[ url_digest, Time.now.strftime("%Y%m%d") ].join("-"),
[ url_digest, Time.now.strftime("%Y%m") ].join("-"),
[ url_digest, Time.now.strftime("%Y") ].join("-"),
[ url_digest, user_id ].join("-")
] $ ruby src/realtime_analytics_with_aggregation.rb
Expect to upsert:[
puts "Expect to upsert: "2d86a774beffe90e715a8028c7bd177b-‐20110323",
n#{ids}"
"2d86a774beffe90e715a8028c7bd177b-‐201103",
"2d86a774beffe90e715a8028c7bd177b-‐2011",
result = db["visits"].update(
"2d86a774beffe90e715a8028c7bd177b-‐4d899fab31f238165c000001"
{ :_id => { :$in => ids } },
]
{ :$inc => { :hits => { "err"=>nil,
1 } },
:multi => true, "updatedExisting"=>false,
"upserted"=>BSON::ObjectId('4d899fabe23bd37e768ae76e'),
:upsert => true, "n"=>1,
:safe => true "ok"=>1.0
}
)
puts result.inspect {"_id"=>BSON::ObjectId('4d899fabe23bd37e768ae76d'), "hits"=>1}
puts db["visits"].all {"_id"=>BSON::ObjectId('4d899fabe23bd37e768ae76e'), "hits"=>1}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-78-320.jpg)
![url’s visits aggregated by time
(look before you leap)
result = db["visits"].update(
{ :_id => { :$in => ids } },
{ :$inc => { :hits => 1 } },
:multi => true,
:upsert => true,
:safe => true
)
if result["n"] != ids.size
updated_ids = db["visits"].find(
{ :_id => { :$in => ids } }, :fields => { :_id => true }
).map{|document| document["_id"]}
db["visits"].insert((ids - updated_ids).map do |id|
{ :_id => id, :hits => 1 }
end)
db["visits"].remove(:_id => result["upserted"]) if result["upserted"]
end](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-79-320.jpg)
![url’s visits aggregated by time
(look before you leap)
result = db["visits"].update(
{ :_id => { :$in => ids } },
{ :$inc => { :hits => 1 } },
:multi => true,
:upsert => true,
:safe => true
) $ ruby src/realtime_analytics_with_aggregation.rb
{ "err"=>nil,
"updatedExisting"=>false,
if result["n"] != ids.size
"upserted"=>BSON::ObjectId('4d89a5ebe23bd37e768ae76f'),
"n"=>1,
updated_ids = db["visits"].find(
"ok"=>1.0
{ :_id => { :$in => ids } }, :fields => { :_id => true }
).map{|document| document["_id"]}
}
{"_id"=>"<url_digest>-‐20110323", "hits"=>1}
db["visits"].insert((ids - updated_ids).map do |id|
{"_id"=>"<url_digest>-‐201103", "hits"=>1}
{"_id"=>"<url_digest>-‐2011", "hits"=>1}
{ :_id => id, :hits {"_id"=>"<url_digest>-‐4d89a43b31f238167a000001", "hits"=>1}
=> 1 }
end)
db["visits"].remove(:_id => result["upserted"]) if result["upserted"]
end](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-80-320.jpg)
![url’s visits aggregated by time
(look before you leap)
result = db["visits"].update(
{ :_id => { :$in => ids } },
{ :$inc => { :hits => 1 } },
:multi => true,
:upsert => true,
:safe => true
) $ ruby src/realtime_analytics_with_aggregation.rb
{ "err"=>nil,
"updatedExisting"=>true,
if result["n"] != ids.size
"n"=>3,
"ok"=>1.0
updated_ids = db["visits"].find(
}
{ :_id => { :$in => ids } }, :fields => { :_id => true }
{"_id"=>"<url_digest>-‐20110323", "hits"=>2}
).map{|document| document["_id"]}
{"_id"=>"<url_digest>-‐201103", "hits"=>2}
{"_id"=>"<url_digest>-‐2011", "hits"=>2}
db["visits"].insert((ids - updated_ids).map do |id|
{"_id"=>"<url_digest>-‐4d89a43b31f238167a000001", "hits"=>1}
{"_id"=>"<url_digest>-‐4d89a44231f238167e000001", "hits"=>1}
{ :_id => id, :hits => 1 }
end)
db["visits"].remove(:_id => result["upserted"]) if result["upserted"]
end](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-81-320.jpg)

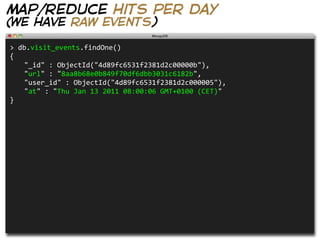
![map/reduce hits per day
(generate data WITH something like)
def generate_events(visits, db, now)
visits.times do |time|
now += BETWEEN_VISITS.sample.seconds
db["visit_events"].insert(
:url => Digest::MD5.hexdigest(URLS.sample),
:user_id => USERS.sample[:id],
:at => now
)
end
end
generate_events(10_000, db, now)](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-84-320.jpg)
![map/reduce hits per day
(simple map/reduce)
MAP = <<-EOF
function() {
emit([ this.url, this.at.format("Ymd") ].join("-"), { "hits": 1 })
}
EOF
REDUCE = <<-EOF
function(key, values) {
var hits = 0
for(var index in values) hits += values[index]["hits"]
return { "hits": hits }
}
EOF
result = db["visit_events"].map_reduce(
MAP, REDUCE, :out => "visits", :raw => true, :verbose => true
)
puts result.inspect](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-85-320.jpg)
![map/reduce hits per day
(date.prototype.format don’t exists)
MAP = <<-EOF
function() {
emit([ this.url, this.at.format("Ymd") ].join("-"), { "hits": 1 })
}
EOF
REDUCE = <<-EOF
function(key, values) {
var hits = 0
for(var index in values) hits += values[index]["hits"]
return { "hits": hits }
}
EOF
result = db["visit_events"].map_reduce(
MAP, REDUCE, :out => "visits", :raw => true, :verbose => true
)
puts result.inspect](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-86-320.jpg)
![map/reduce hits per day
(implement format in place)
MAP = <<-EOF
function() {
Date.prototype.format = function(format) {
...
}
emit([ this.url, this.at.format("Ymd") ].join("-"), { "hits": 1 })
}
EOF
REDUCE = <<-EOF
function(key, values) {
var hits = 0
for(var index in values) hits += values[index]["hits"]
return { "hits": hits }
}
EOF](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-87-320.jpg)
![map/reduce hits per day
(implement format only if needed)
MAP = <<-EOF
function() {
if (!Date.prototype.format) {
Date.prototype.format = function(format) {
...
}
}
emit([ this.url, this.at.format("Ymd") ].join("-"), { "hits": 1 })
}
EOF
REDUCE = <<-EOF
function(key, values) {
var hits = 0
for(var index in values) hits += values[index]["hits"]
return { "hits": hits }
}
EOF](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-88-320.jpg)
![map/reduce hits per day
(implement format once and for all)
db[Mongo::DB::SYSTEM_JS_COLLECTION].save(
:_id => "formatDate",
:value => BSON::Code.new(
<<-EOF
function(date, format) {
if (!Date.prototype.format) {
Date.prototype.format = function(format) { ... }
}
return date.format(format)
}
EOF
)
)
MAP = <<-EOF
function() {
emit([ this.url, formatDate(this.at, "Ymd") ].join("-"), {"hits":1})
}
EOF](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-89-320.jpg)
![map/reduce hits per day
(implement format once and for all)
db[Mongo::DB::SYSTEM_JS_COLLECTION].save(
:_id => "load",
:value => BSON::Code.new(
<<-EOF
function(module) {
if ((module === "date") && !Date.prototype.format) {
Date.prototype.format = function(format) { ... }
}
return true
}
EOF
)
)
MAP = <<-EOF
function() {
load("date") && emit(
[ this.url, this.at.format("Ymd") ].join("-"),
{ "hits": 1 }
)
}
EOF](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-90-320.jpg)
![map/reduce hits per day
(ok, but could be taking too long)
MAP = <<-EOF
function() {
emit([ this.url, this.at.format("Ymd") ].join("-"), { "hits": 1 })
}
EOF
REDUCE = <<-EOF $ ruby src/incremental_mr.rb
function(key, values)
{
{ "result"=>"visits",
var hits = 0 "timeMillis"=>4197,
for(var index in values) hits += values[index]["hits"]
"timing"=> {
"mapTime"=>3932,
return { "hits": hits }
"emitLoop"=>4170,
} "total"=>4197
EOF },
"counts"=> {
"input"=>10000,
result = db["visit_events"].map_reduce(
"emit"=>10000,
"output"=>200
MAP, REDUCE, :out => "visits", :raw =>
}, true, :verbose => true
) "ok"=>1.0
}
puts result.inspect](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-91-320.jpg)

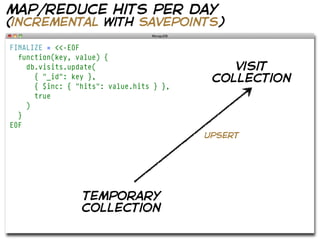
![map/reduce hits per day
(incremental with savepoints)
generate_events(number_of_events, db, now)
from = from_last_updated(db)
to = to_last_inserted(db)
result = db["visit_events"].map_reduce(
MAP, REDUCE,
:finalize => FINALIZE,
:query => { :_id => { :$gt => from, :$lte => to } },
:raw => true,
:verbose => true
)
db["visits"].save(:_id => "savepoint", :at => to)](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-96-320.jpg)
![map/reduce hits per day
(incremental with savepoints)
generate_events(number_of_events, db, now)
from = from_last_updated(db)
to = to_last_inserted(db)
result = db["visit_events"].map_reduce(
MAP, REDUCE, $ ruby src/incremental_mr.rb -‐e 10000
:finalize => FINALIZE,{ "result"=>"tmp.mr.mapreduce_1300892393_60",
:query => { :_id => { :$gt => from, :$lte => to } },
"timeMillis"=>4333,
"timing"=>{...},
:raw => true, "counts"=>{
:verbose => true "input"=>10000,
"emit"=>10000,
) "output"=>196
},
"ok"=>1.0
db["visits"].save(:_id => "savepoint",
} :at => to)
{ "_id"=>"05241f07d0e3ab6a227e67b33ea0b509-‐20110113",
"hits"=>26
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-97-320.jpg)
![map/reduce hits per day
(incremental with savepoints)
generate_events(number_of_events, db, now)
from = from_last_updated(db)
to = to_last_inserted(db)
result = db["visit_events"].map_reduce(
MAP, REDUCE, $ ruby src/incremental_mr.rb -‐e 4999
:finalize => FINALIZE,{ "result"=>"tmp.mr.mapreduce_1300892399_61",
:query => { :_id => { :$gt => from, :$lte => to } },
"timeMillis"=>2159,
"timing"=>{...},
:raw => true, "counts"=>{
:verbose => true "input"=>4999,
"emit"=>4999,
) "output"=>146
},
"ok"=>1.0
db["visits"].save(:_id => "savepoint",
} :at => to)
{ "_id"=>"05241f07d0e3ab6a227e67b33ea0b509-‐20110113",
"hits"=>64
}](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-98-320.jpg)
![map/reduce hits per day
(incremental with savepoints)
def savepoint(db)
db["visits"].find_one(:_id => "savepoint") or
{ "at" => BSON::ObjectId.from_time(10.years.ago) }
end
def from_last_updated(db)
savepoint["at"]
end
def to_last_inserted(db)
db["visit_events"].find.sort([:_id, Mongo::DESCENDING]).first["_id"]
end](https://image.slidesharecdn.com/mongodb-with-style-110327120557-phpapp01/85/MongoDB-With-Style-99-320.jpg)

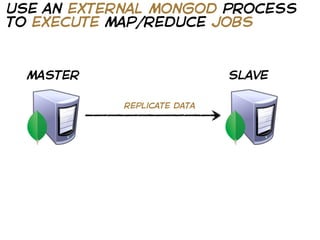
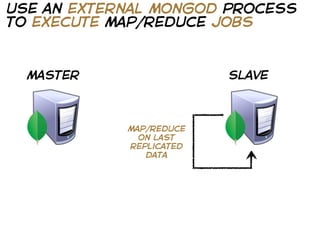
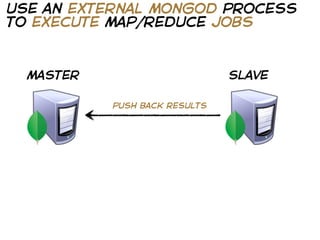











The document provides a guide on using MongoDB with operations demonstrated in Ruby, including setting up the database, querying data, and optimizing performance through monitoring and indexing. It emphasizes the importance of design based on query patterns and conventions for identifying and retrieving data. Additionally, it covers various techniques for data retrieval, such as batch queries and statistical computations.






























































































