Download as PDF, PPTX






![enter mechanize + nokogiri
require "mechanize"
agent = Mechanize.new do | agent |
agent.user_agent_alias = "Linux Mozilla"
end
agent.get("http://example.com/login") do | login_page |
result_page = login_page.form_with(:name => "login") do | login_form |
login["username"] = username
login["password"] = password
end.submit
result_page.search("//table[starts-with(@class,'boundaries')]").map do | option_table |
{ "name" => option_table.search("./caption/child::text()")
"credits" => option_table.search("./descendant::td[position()=3]/child::text()")
}
end
end](https://image.slidesharecdn.com/magicofruby-101220111550-phpapp01/85/Magic-of-Ruby-7-320.jpg)

![enter commander
describe arguments
command :is_registered do | command |
command.syntax = "is_registered --username TELEPHONE_NUMBER [ --without-cache ]"
command.description = "Check if user is registered"
command.option "-u", "--username TELEPHONE_NUMBER", String, "user's telephone number"
command.option "-n", "--without-cache", "bypass user's profile informations cache"
command.when_called do | arguments, options |
options.default :username => "", :without_cache => false
ok(is_registered(options.username, options.without_cache))
end
end
extract code into functions](https://image.slidesharecdn.com/magicofruby-101220111550-phpapp01/85/Magic-of-Ruby-9-320.jpg)
![use page object pattern
def is_registered(username)
browse do | agent, configuration |
LoginPage.new(
agent.get(configuration["login_page_url"])
).is_registered?(username)
end
end](https://image.slidesharecdn.com/magicofruby-101220111550-phpapp01/85/Magic-of-Ruby-10-320.jpg)
![use page object pattern
class LoginPage < PageToScrub
def is_registered?(username)
begin
login(username, "fake password")
rescue WrongPassword
true
rescue NotRegistered, WrongUsername, WrongArea
false
end
end
def login(username, password)
check_page(
use_element(:login_form) do | login |
login["username"] = username
login["password"] = password
end.submit
)
end
def login_form
@page.form_with(:name => "login")
end](https://image.slidesharecdn.com/magicofruby-101220111550-phpapp01/85/Magic-of-Ruby-11-320.jpg)
![use page object pattern
class LoginPage < PageToScrub
def is_registered?(username)
begin
login(username, "fake password")
rescue WrongPassword
true
rescue NotRegistered, WrongUsername, WrongArea
false
end
end useful abstractions
def login(username, password)
check_page(
use_element(:login_form) do | login |
login["username"] = username
login["password"] = password
end.submit
)
end
def login_form
@page.form_with(:name => "login")
end](https://image.slidesharecdn.com/magicofruby-101220111550-phpapp01/85/Magic-of-Ruby-12-320.jpg)



![rspec is your friend :-)
describe "is_registered" do
context "XXX3760593" do
it "should be a consumer registered" do
result = command(:is_registered, :username => "XXX3760593")
result.should_not be_an_error
result["area"].should == "consumer"
result["registered"].should == true
end
end
end](https://image.slidesharecdn.com/magicofruby-101220111550-phpapp01/85/Magic-of-Ruby-16-320.jpg)


![enter the cache
single line change
def is_registered(username, without_cache)
browse do | agent, configuration, cache |
cache.command([ username, "is_registered" ]) do
LoginPage.new(
agent.get(configuration["login_page_url"])
).is_registered?(username)
end
end
end](https://image.slidesharecdn.com/magicofruby-101220111550-phpapp01/85/Magic-of-Ruby-19-320.jpg)



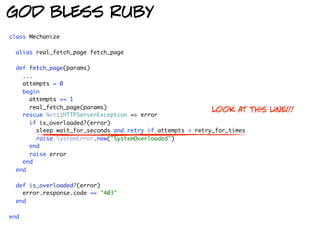
![god bless mechanize
def browse
begin
cache = CommandCache.new(database_path)
configuration = YAML::load(File.open(configuration_path))
proxy = configuration["proxy"]
agent = Mechanize.new do | agent |
agent.user_agent_alias = "Linux Mozilla"
agent.set_proxy(proxy["host"], proxy["port"]) if proxy
end
yield(agent, configuration, cache)
rescue Mechanize::ResponseCodeError => error single line change
failure(LoadPageError.new(error))
rescue Timeout::Error
failure(TimeoutPageError.new)
rescue ScrubError => error
failure(error)
rescue => error
failure(UnknownError.new(error.to_s))
ensure
cache.close!
end
end](https://image.slidesharecdn.com/magicofruby-101220111550-phpapp01/85/Magic-of-Ruby-23-320.jpg)


![we can also test it :-)
class WEBrick::HTTPResponse
def serve(content)
self.body = content
self["Content-Length"] = content.length
end
def overloaded
serve("<html><body>squid</body></html>")
self.status = 403
end
end
proxy = WEBrick::HTTPProxyServer.new(
:Port => 2200,
:ProxyContentHandler => Proc.new do | request, response |
response.overloaded
end
)
trap("INT") { proxy.shutdown }
proxy.start](https://image.slidesharecdn.com/magicofruby-101220111550-phpapp01/85/Magic-of-Ruby-27-320.jpg)



![If you want something done, do it yourself
how to transform a command line program
into a web application
class ScrubsHandler < Mongrel::HttpHandler
def process(request, response)
command = request.params["PATH_INFO"].tr("/", "")
elements = Mongrel::HttpRequest.query_parse(request.params["QUERY_STRING"])
parameters = elements.inject([]) do | parameters, parameter |
name, value = parameter
parameters << if value.nil?
"--#{name}"
else
"--#{name}='#{value}'"
end
end.join(" ")
almost a single line change
response.start(200) do | head, out |
head["Content-Type"] = "application/json"
out.write(scrubs.execute(command, parameters))
end
end
...
end](https://image.slidesharecdn.com/magicofruby-101220111550-phpapp01/85/Magic-of-Ruby-32-320.jpg)


![change the cache implementation
use the file system luke...
def expire(keys, result = nil)
FileUtils.rm path(keys), :force => true
result.merge({ "from_cache" => false }) unless result.nil?
end
def expire_after(keys, seconds, result = nil)
expire(keys, result) if (from_cache(keys)["cached_at"] + seconds) <= now rescue nil
end
def from_cache(keys)
cache_file_path = path(keys)
raise NotInCache.new(keys) unless File.exists?(cache_file_path)
JSON.parse(File.read(cache_file_path)).merge({ "from_cache" => true })
end
def to_cache(keys, result)
result = result.merge({ "cached_at" => now })
File.write(path(keys), JSON.generate(result))
result.merge({ "from_cache" => false })
end](https://image.slidesharecdn.com/magicofruby-101220111550-phpapp01/85/Magic-of-Ruby-36-320.jpg)

![maintenance page detection
class PageToScrub
def initialize(page)
@page = page
check_page_errors
check_for_maintenance
end
def check_for_maintenance
@page.search("//td[@class='txtbig']").each do | node |
if extract_text_from(node.search("./descendant::text()")) =~
/^.+?area.+?clienti.+?non.+?disponibile.+?stiamo.+?lavorando/im
raise OnMaintenancePage.new(@page, "??? is on maintenance")
end
end
end
...
end](https://image.slidesharecdn.com/magicofruby-101220111550-phpapp01/85/Magic-of-Ruby-38-320.jpg)








The document describes the evolution of a web scraping project using Ruby from a simple initial implementation to a robust production system. It started as a quick script but grew to handle logging in, extracting data from multiple pages, error handling, caching, and performance improvements like using a proxy. Testing and refactoring helped increase confidence and maintainability. The system was eventually able to replicate most of the target website's features, handling high volumes of traffic through caching and other optimizations.




























































































