Download to read offline



1.2.2 Disclaimer
This is a buzzword intensive presentation but by no means intended to trick you into
thinking I’m a very smart person! Buzzwords just sound nice when put together...
1.2.3 But before we get started ....
replace this image
1.2.4 MongoDB Developer Courses
https://university.mongodb.com/
2](https://image.slidesharecdn.com/opsmanager-kubernetes-190102171635/85/MongoDB-Ops-Manager-Kubernetes-2-320.jpg)


![is now maintained by the Cloud Native Computing Foundation
Kubernetes uses containers. Well, we can say that kubernetes loves containers. Deploys and
manages containers and containerized applications
Kubernetes has standardized the container definition on the Docker format.
1.3.4 Container Definition
cat mflix/Dockerfile
# base image of mflix container
FROM java:8
# port number the container exposes
EXPOSE 90000
# make the jar file available in the container image
COPY mflix-1.0-SNAPSHOT.jar ./mflix-1.0-SNAPSHOT.jar
# application run command
CMD ["java", "-jar", "./mflix-1.0-SNAPSHOT.jar"]
In this file we can see an example of a Docker image file. Sets the instructions to load, expose
and execute containarized applications or instances.
The Docker images are hiearchical, this means that we can compose images uppon each other,
inheriting the configuration and image setup
In this example we are creating a container image using as baseline a Java image.
1.3.5 Image vs Container
An image determines what and how to run, using/inherinting which requierements and the de-
fault configuration of a containerized application
A container is the the runtime execution of a built Docker image.
5](https://image.slidesharecdn.com/opsmanager-kubernetes-190102171635/85/MongoDB-Ops-Manager-Kubernetes-5-320.jpg)









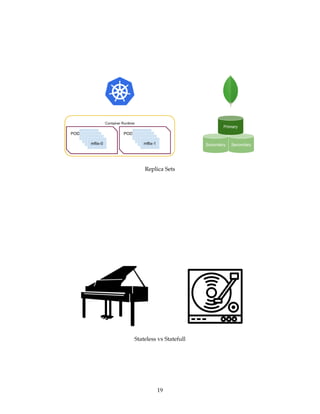

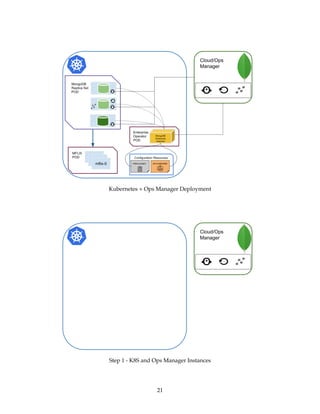
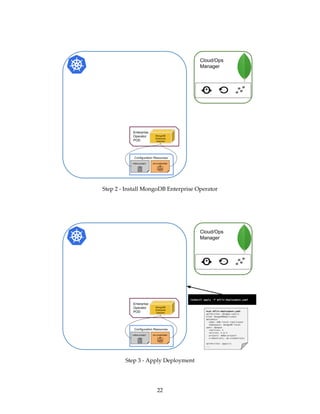




The document provides a comprehensive overview of Kubernetes and its integration with MongoDB, detailing the architecture and components of a Kubernetes cluster, as well as the functionality of the MongoDB Enterprise Kubernetes Operator for deploying and managing MongoDB instances. It emphasizes the distinctions between Kubernetes and MongoDB clusters, particularly regarding replication and state management, and guides readers through setting up a local Kubernetes cluster with MongoDB integration. The presentation aims to equip attendees with practical knowledge for managing containerized applications effectively.






















































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)
































