Download to read offline








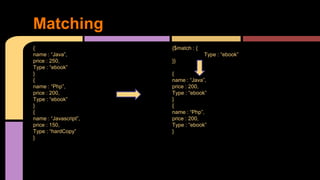


![{
name : “Java”,
price : 250,
Type : “ebook”,
quantity : 3
}
{
name : “Php”,
price : 200,
Type : “ebook”,
quantity : 2
}
Custom Field Computation
{$project : {
fullStock : {
$mul : [“$price”, “$quantity”]
},
Title : “$name”
}}
{
fullStock : 750,
Title: “Java”
}
{
price : 400,
Title: “Php”
}](https://image.slidesharecdn.com/mongo-150817173056-lva1-app6891/85/Mongo-an-intermediate-introduction-12-320.jpg)
![{
name : “Java”,
price : 250,
Type : “ebook”,
quantity : 3
}
{
name : “Php”,
price : 200,
Type : “ebook”,
quantity : 2
}
Generating Sub-Document
{$project : {
fullStock : {
$mul : [“$price”, “$quantity”]
},
details : {Title : “$name”, quantity : “$quantity” }
}}
{
fullStock : 750,
details : {Title: “Java”, quantity : 3}
},
{,
fullStock : 400,
details : {Title: “Php”, quantity : 2}
}](https://image.slidesharecdn.com/mongo-150817173056-lva1-app6891/85/Mongo-an-intermediate-introduction-13-320.jpg)



![{
publisher :“manning”,
title: [“java”, “Php”],
discount : 50%
}
$unwind
{$unwind : $category}
{
publisher : manning,
title: java,
discount :50%
},
{
publisher : manning,
title: Php,
discount :50%
}](https://image.slidesharecdn.com/mongo-150817173056-lva1-app6891/85/Mongo-an-intermediate-introduction-17-320.jpg)

![{
_id :123,
name : logo,
security : “ANYONE”,
Profit : {
security : “MARKETING”,
revenue : 500%,
ProfitByCountry : {
security : “BOARD_OF_DIRECTOR”
PL : 800 %
NO : 700 %
DK : 600%
SW : 500 %
}
}
}
$redact
db.products.aggregate([
{$match : {name : “logo”}},
$redact : {
$cond : {
if : {$eq : …},
then : “$$DESCEND”,
else : “$PRUNE
}
}
])
{...}](https://image.slidesharecdn.com/mongo-150817173056-lva1-app6891/85/Mongo-an-intermediate-introduction-19-320.jpg)







The document provides an overview of MongoDB, highlighting its features such as the aggregation framework, sharding, and replica sets, focusing on their scalability, performance, and flexibility. It illustrates MongoDB's capabilities through real-life examples and describes various query operators and their usage in managing data. The emphasis is on MongoDB's advantages over traditional RDBMS, especially in handling large datasets and high throughput applications.

![Internet and Web Technology (CLASS-14) [JSP] | NIC/NIELIT Web Technology](https://cdn.slidesharecdn.com/ss_thumbnails/iwtclass-14-200809204913-thumbnail.jpg?width=640&height=640&fit=bounds)




























































































