The document discusses Lex and Yacc. It provides information on:
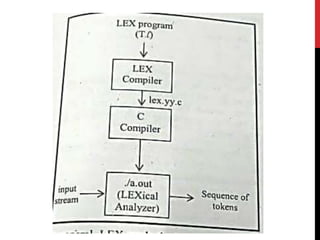
1) Lex is a tool for pattern matching that generates a lexical analyzer. A Lex program has a declaration section, rule section, and C code section.
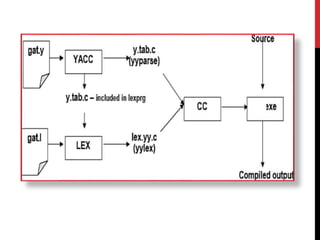
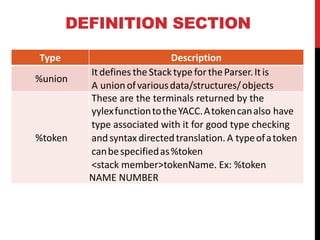
2) Yacc is a tool for imposing structure on input using grammar rules. It generates a C parser. A Yacc program has a definition section, rule section, and code section.
3) Lex and Yacc are commonly used together, with Yacc calling Lex's yylex() function to retrieve tokens which are then parsed according to the grammar rules.






![A SIMPLE LEX PROGRAM
Program to identify numbers and letters
%{
#include<stdio.h>
%}
%%
[0-9]+ printf(“found an integer:%dn”, yytext);
[A-Za-z0-9]+ printf(“fount an string %sn”, yytext);
%%
void main()
{
yylex();
}](https://image.slidesharecdn.com/module4-220816110114-3d2d0a3b/85/module-4-pptx-7-320.jpg)











![Lex file: Pg2.l
%{
#include "y.tab.h"
%}
%%
[a-zA-Z] {return L;}
[0-9] {return D;}
[tn] {return 0;}
. {printf("Invalid Variable"); exit(0);}
%%](https://image.slidesharecdn.com/module4-220816110114-3d2d0a3b/85/module-4-pptx-21-320.jpg)



![Character Meaning
A-Z, 0-9, a-z Characters and numbers that form part of the pattern.
. Matches any character except n.
-
Used to denote range. Example:A-Zimplies all charactersfromAto
Z.
[ ]
Acharacter class. Matches any character in thebrackets. If thefirst
characteris ^then it indicatesa negationpattern. Example:[abC]
matches either of a, b, and C.
* Match zero or more occurrences of the preceding pattern.
+
Matches one or more occurrences of the preceding pattern.(no
empty string)
Ex: [0-9]+ matches “1”,”111” or “123456” but not an empty string.](https://image.slidesharecdn.com/module4-220816110114-3d2d0a3b/85/module-4-pptx-25-320.jpg)
![Character Meaning
?
Matches zero or one occurrences of the preceding pattern.
Ex: -?[0-9]+ matches a signed number including an optional leading
minus.
$ Matches end of line as the last character of the pattern.
{ }
1) Indicates how many times a pattern can be present.
2) If they contain name, they refer to a substitution by that
name.
Used to escape meta characters.Also used to remove the special
meaning of characters as defined in this table.
^ Negation.
|
Matches either the preceding regular expression or the following
regular expression. Ex: cow|sheep|pig matches any of the three
words.](https://image.slidesharecdn.com/module4-220816110114-3d2d0a3b/85/module-4-pptx-26-320.jpg)


![%{
int c=0,w=0,s=0,l=0;
%}
%%
[ t] {s++;w++;}
[n] {l++;w++;}
[a-z A-Z 0-9] {c++;}
%%
int main(int argc,char *argv[])
{
if(argc==2)
{
yyin=fopen(argv[1],"r");
yylex();
printf(" no of charcters are:%dn",c);
printf(" no of words are:%dn",w);
printf(" no of lines are:%dn",l);
printf(" no of spaces are:%dn",s);
}
else
{
printf(" insufficient argumentn");
return 0;
}
Pg3.l](https://image.slidesharecdn.com/module4-220816110114-3d2d0a3b/85/module-4-pptx-29-320.jpg)

![Output:
[student@localhost ~]$ gedit pg3.l
[student@localhost ~]$ lex pg.l
[student@localhost ~]$ vi text.txt
[student@localhost ~]$ cc lex.yy.c
[student@localhost ~]$ ./a.out text.txt
The number of lines=2
The number of spaces=8
The number of words=8
The number of characters are=36
[student@localhost ~]$ cat text.txt
hi welcome to word count program
Lets begin](https://image.slidesharecdn.com/module4-220816110114-3d2d0a3b/85/module-4-pptx-31-320.jpg)
![PROGRAM TO EVALUATE AN ARITHMETIC EXPRESSION INVOLVING
OPERATORS +, -, * AND /.
To identify numbers, lex rule is
[0-9]+|([0-9]*.[0-9]+) this will retrun NUM
To identify the operators from the runtime input we have lex
action as [-+*/()] and in pattern part we return the data in
yytext
to identify the invalid Expression we use lex rule . In action
part
Lex file will only identify the numbers and operators.
Yacc file will perform the necessary arithmetic operations
and will give the file answer of the expression](https://image.slidesharecdn.com/module4-220816110114-3d2d0a3b/85/module-4-pptx-32-320.jpg)
![Lex part : lab1b.l
%{
#include"y.tab.h"
%}
%%
[0-9]+|([0-9]*.[0-9]+) {yylval.dval = atof(yytext); return NUM;}
[-+*/()] {return (*yytext);}
n { return (*yytext); }
. { printf("Invalid Expressionn"); }
%%](https://image.slidesharecdn.com/module4-220816110114-3d2d0a3b/85/module-4-pptx-33-320.jpg)



![OUTPUT:
[student@localhost ~]$ lex lab1b.l
[student@localhost ~]$ yacc -d lab1b.y
[student@localhost ~]$ gcc lex.yy.c y.tab. -ll
[student@localhost ~]$ ./a.out
Enter the arithmetic expression 2.0+3.5*4.0
Valid expression and the value is 16
[student@localhost ~]$ ./a.out
Enter expression a+b
invalid expression
[student@localhost ~]](https://image.slidesharecdn.com/module4-220816110114-3d2d0a3b/85/module-4-pptx-37-320.jpg)
![PROGRAM TO RECOGNIZE STRINGS ‘AAAB’, ‘ABBB’, ‘AB’
AND ‘A’ USING THE GRAMMAR (AN BN , N>= 0).
Lex part : lab5b.l
%{
#include"y.tab.h"
%}
%%
a return A;
b return B;
[ ]+ return empty;
n return *yytext;
. { printf( "Invalid String n" ); exit(0); }
%%](https://image.slidesharecdn.com/module4-220816110114-3d2d0a3b/85/module-4-pptx-38-320.jpg)


![OUTPUT:
[root@localhost ~]# lex exp5b.l
[root@localhost ~]# yacc -d exp5b.y
[root@localhost ~]# cc lex.yy.c y.tab.c
[root@localhost ~]# ./a.out
enter the string aaabbb
valid string
[root@localhost ~]# ./a.out
enter the string
aab
invalid string
[root@localhost ~]#](https://image.slidesharecdn.com/module4-220816110114-3d2d0a3b/85/module-4-pptx-41-320.jpg)





















































