Download as PDF, PPTX






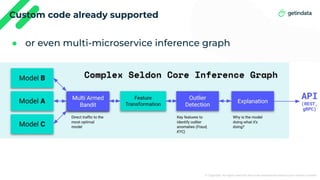








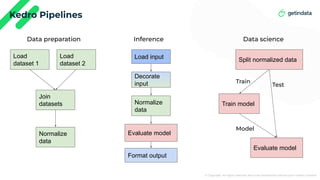





This document discusses using Kedro to streamline the model serving process in machine learning projects by integrating it with Seldon and MLflow. It emphasizes the advantages of combining training and serving in one project, enabling faster iteration and consistency in environments, although it notes some performance overhead. The document highlights Kedro's role in improving reproducibility and bridging the gap between data science and software development.









![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)













































































