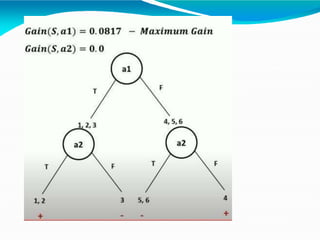
The document discusses attribute selection measures used in decision tree algorithms like ID3. It describes three popular measures - information gain, gain ratio, and Gini index. Information gain selects the attribute that minimizes the expected number of tests needed to classify tuples. Gain ratio normalizes information gain to account for attributes with many values. Gini index measures the impurity of a data partition based on the probability of misclassifying tuples. The document also discusses pruning decision trees to reduce overfitting, and issues like handling continuous attributes.