
Downloaded 519 times





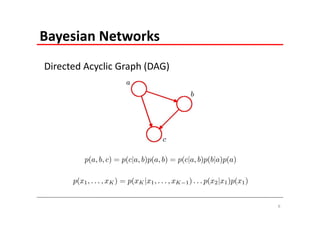
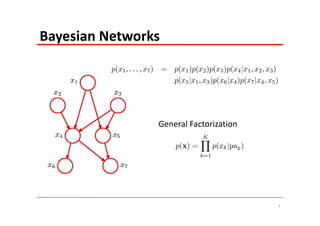




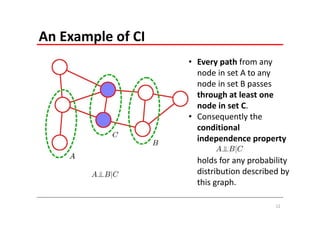
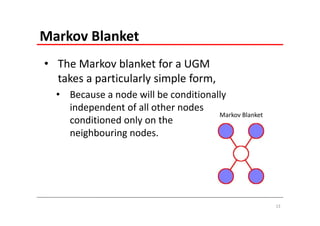




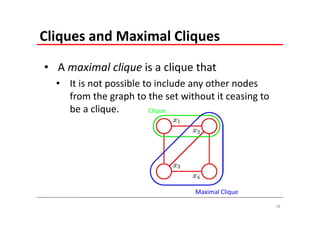
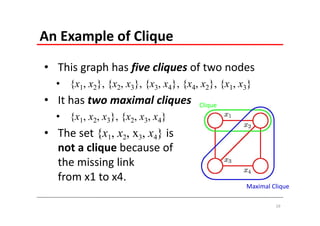










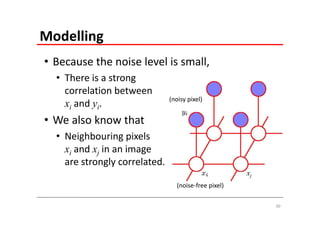
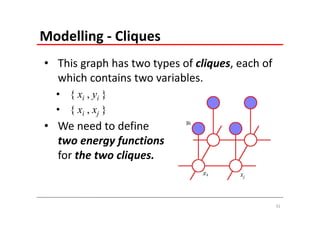
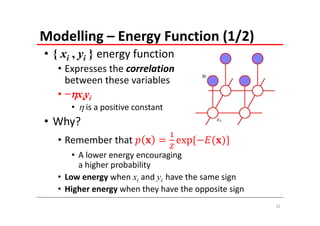
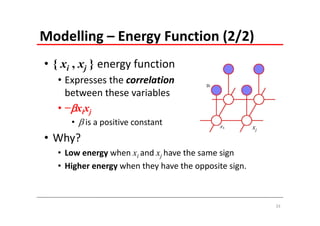
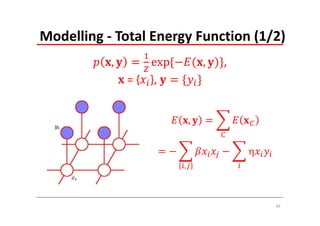
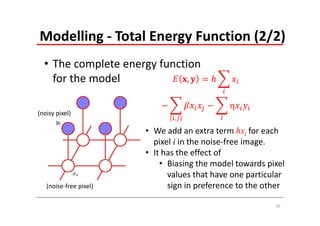
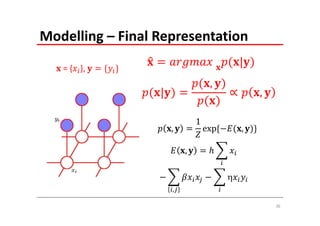




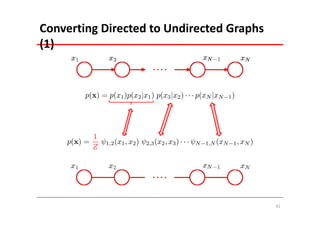
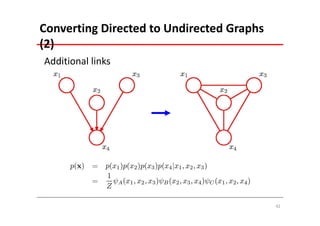
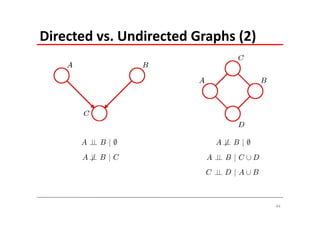
The document explains Markov Random Fields (MRFs) as a class of undirected graphical models used for modeling joint distributions and conditional independence properties, contrasting them with directed graphical models like Bayesian networks. It covers the factorization of joint distributions, the significance of energy functions in applications such as image de-noising, and the underlying relationships between directed and undirected graphs. Key concepts such as cliques, potential functions, and solution algorithms are also discussed.





![Competitive Learning [Deep Learning And Nueral Networks].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/competitivelearning-240211053020-bc9a8437-thumbnail.jpg?width=640&height=640&fit=bounds)














































































