Download as PDF, PPTX






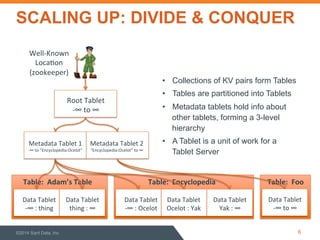
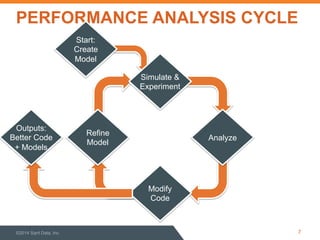


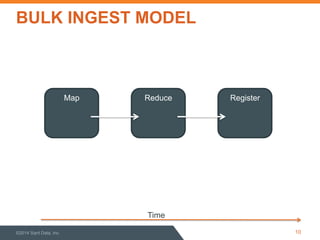


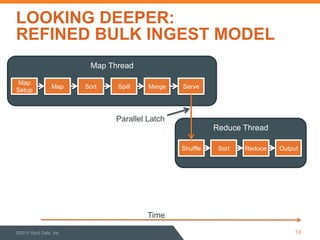

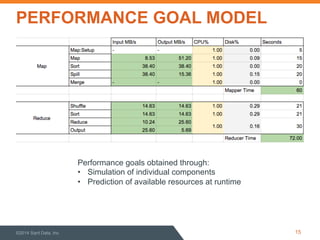

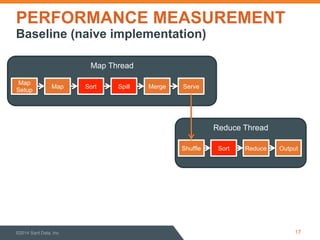


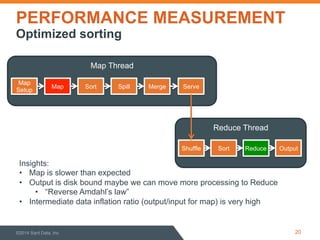






This document discusses performance optimization of Apache Accumulo, a distributed key-value store. It describes modeling Accumulo's bulk ingest process to identify bottlenecks, such as disk utilization during the reduce phase. Optimization efforts included improving data serialization to speed sorting, avoiding premature data expansion, and leveraging compression. These techniques achieved a 6x speedup. Current Accumulo performance projects include optimizing metadata operations and write-ahead log performance.








































































