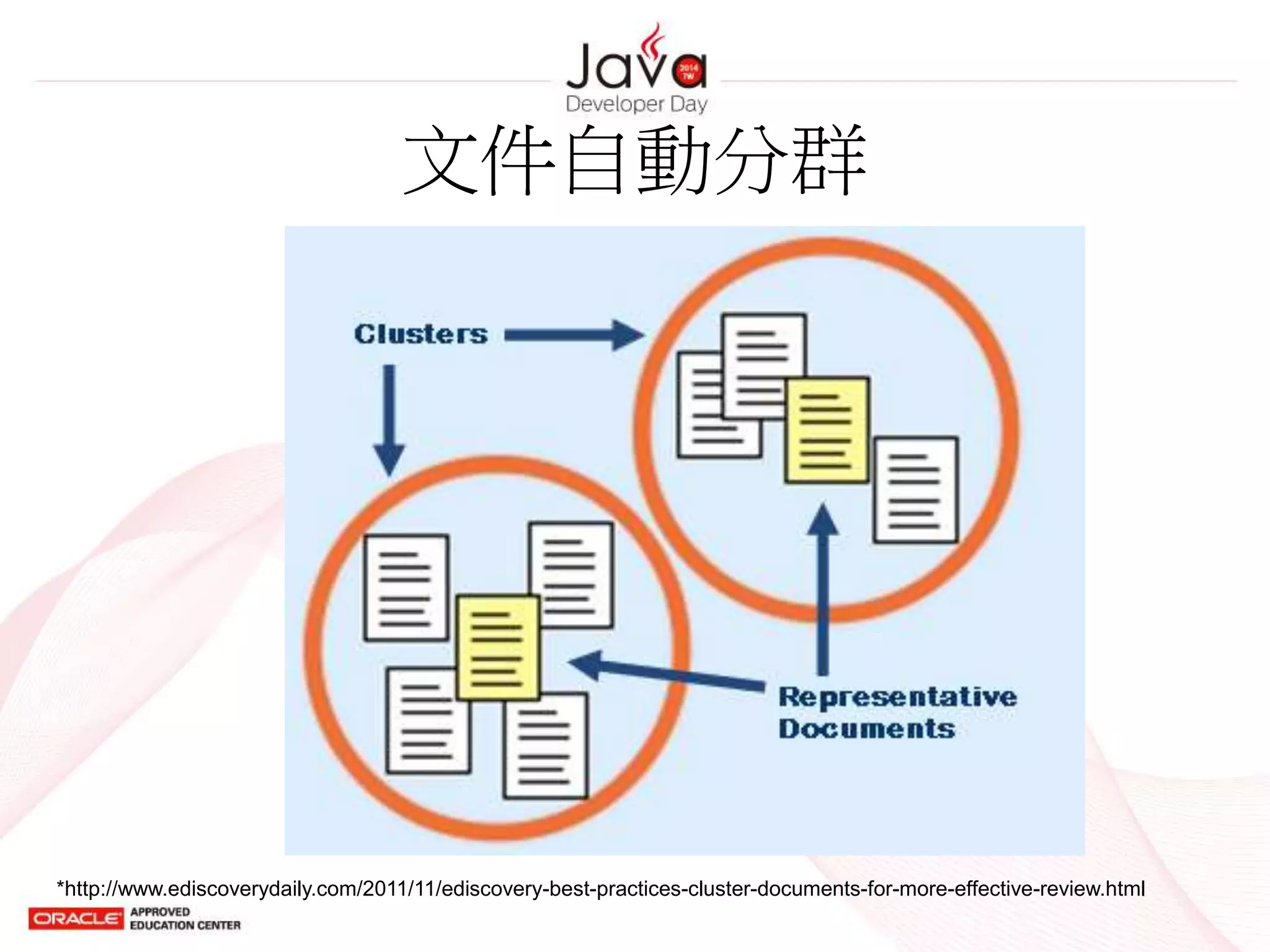
文字探勘(Text Mining)
• 文字探勘意指從文字資訊中發掘出有用資
訊的程序
•Data Mining vs. Text Mining
– Data Mining 假設處理的資料為具結構的資料
– Text Mining 的資源輸入為自然語言型式的文件
資料
• Text Mining 可先將自然語言型式的文件資料
轉換成為具結構的資料,再套用 Data
Mining 方法處理
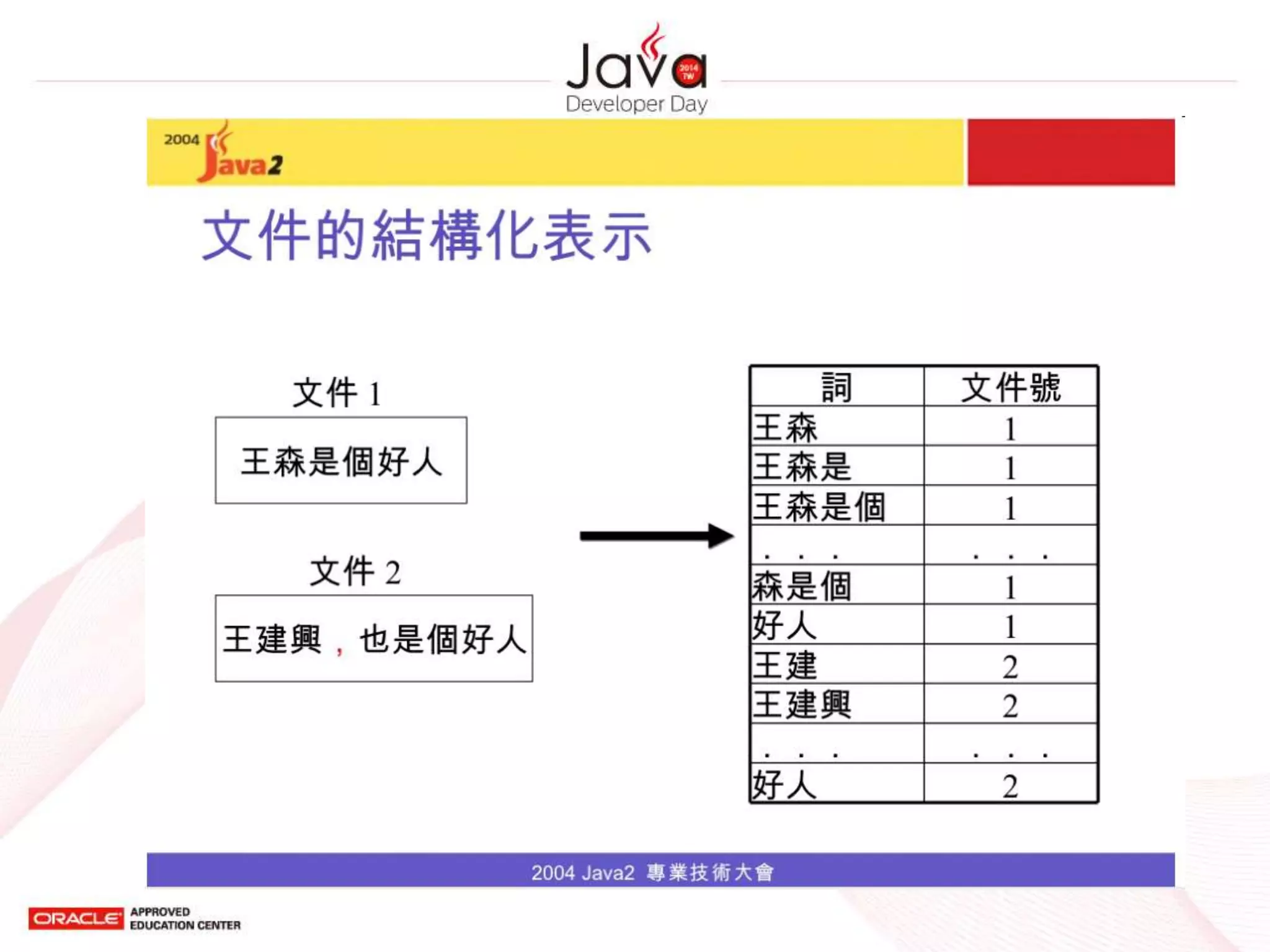
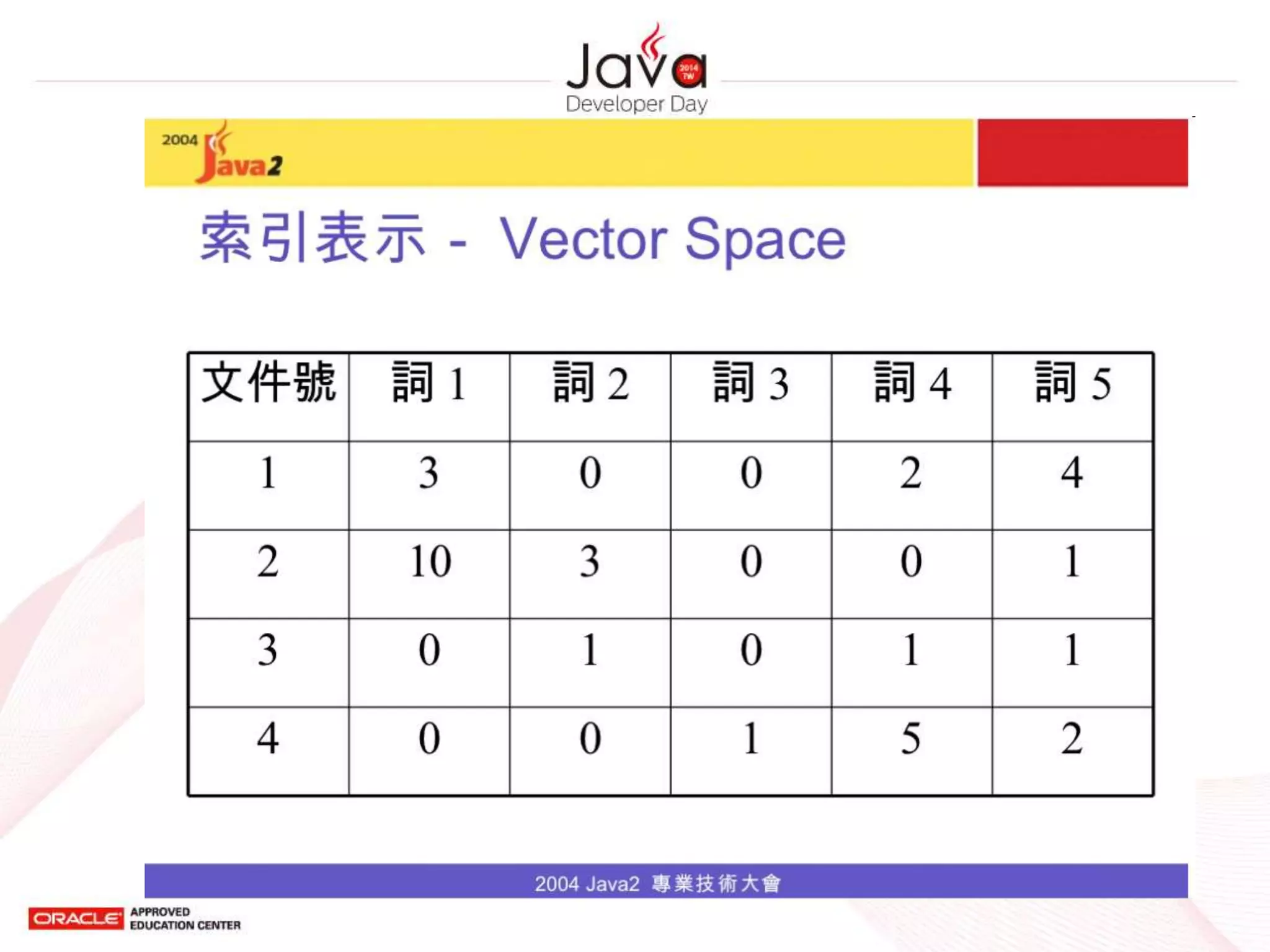
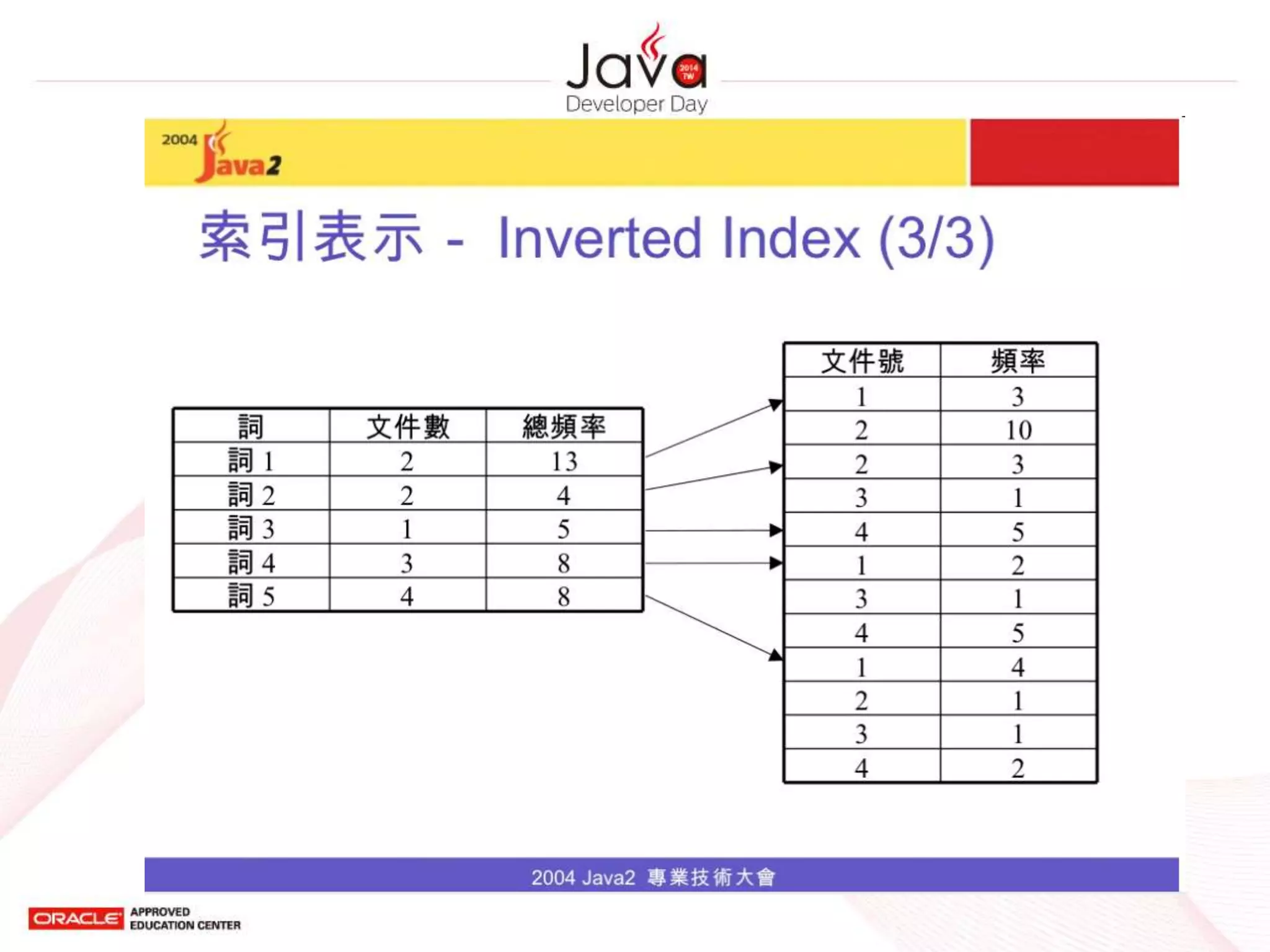
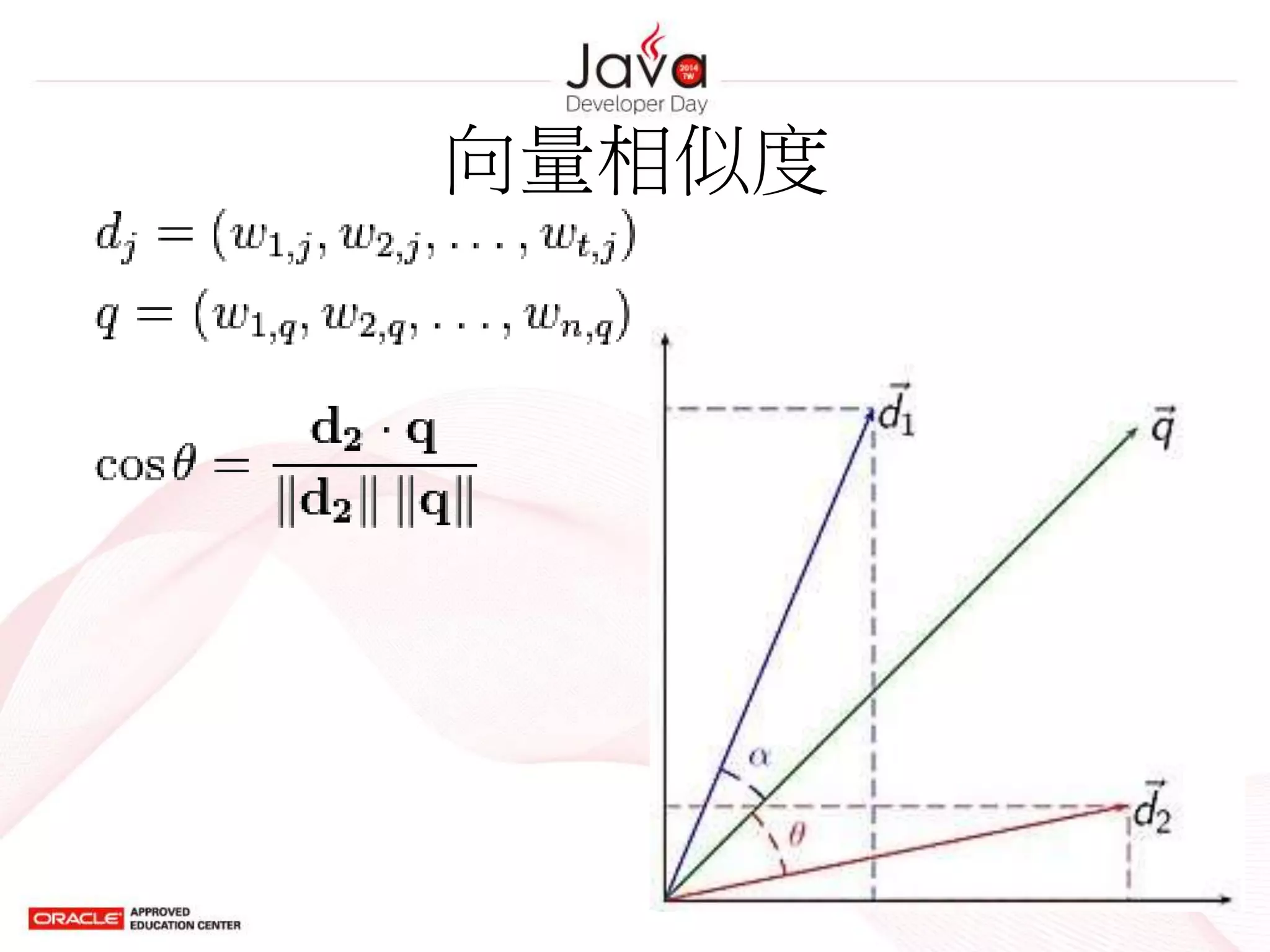
Vector Space Model(2/2)
• 將文件表示為 n 維的向量
– n 即所有文字中的所有可能詞
– 若一文件被表示為向量 V,其中的第 i 個元素之
為 v(i) ,其值為詞 wi 的權重
– 詞 wi 的權重可以有不同的表示,例如
• 詞 wi 的出現次數
• 詞 wi 的 TF-IDF 值









































































![[오픈소스컨설팅] EFK Stack 소개와 설치 방법](https://cdn.slidesharecdn.com/ss_thumbnails/elasticstack-210712042246-thumbnail.jpg?width=640&height=640&fit=bounds)














































