51
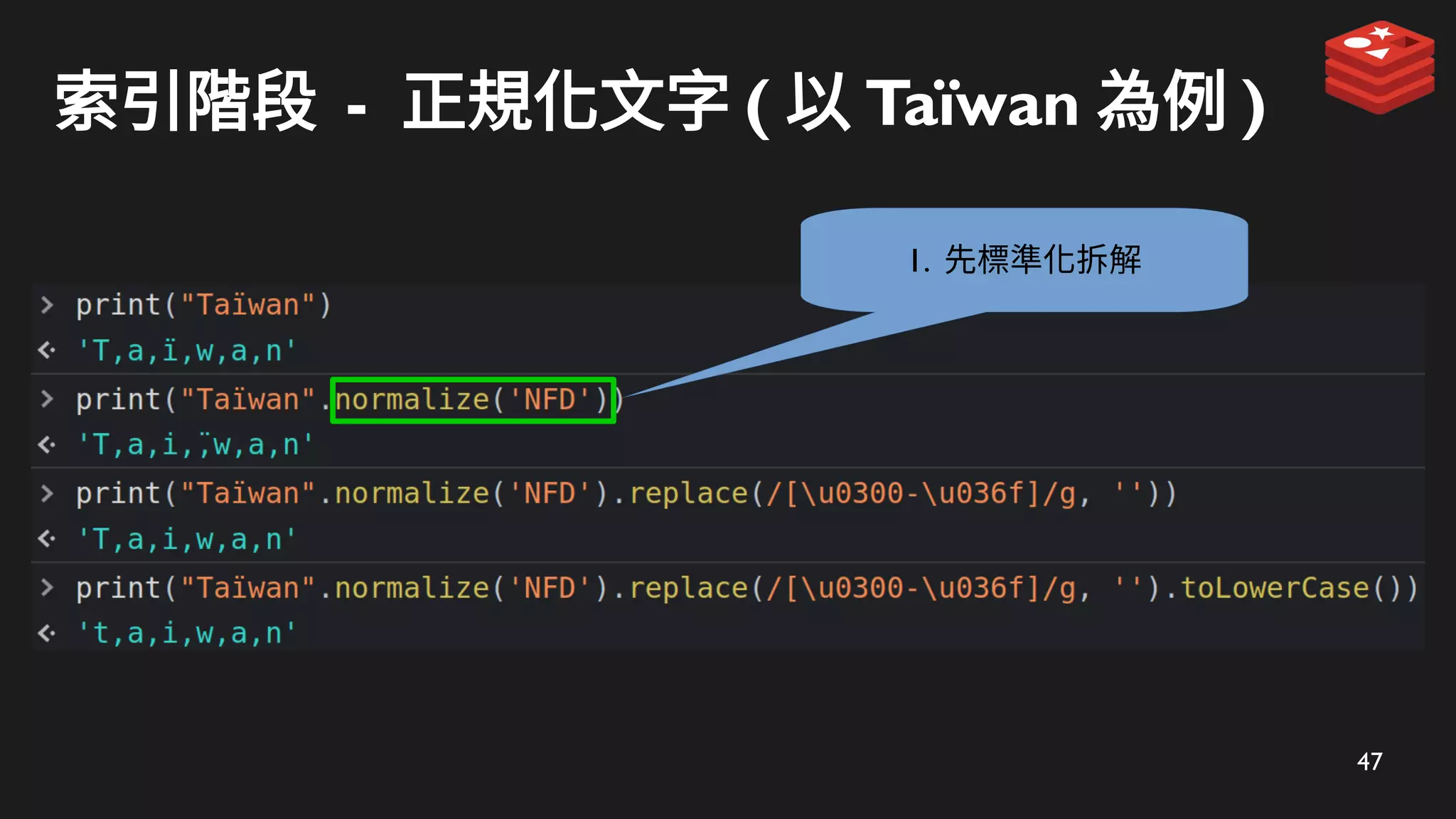
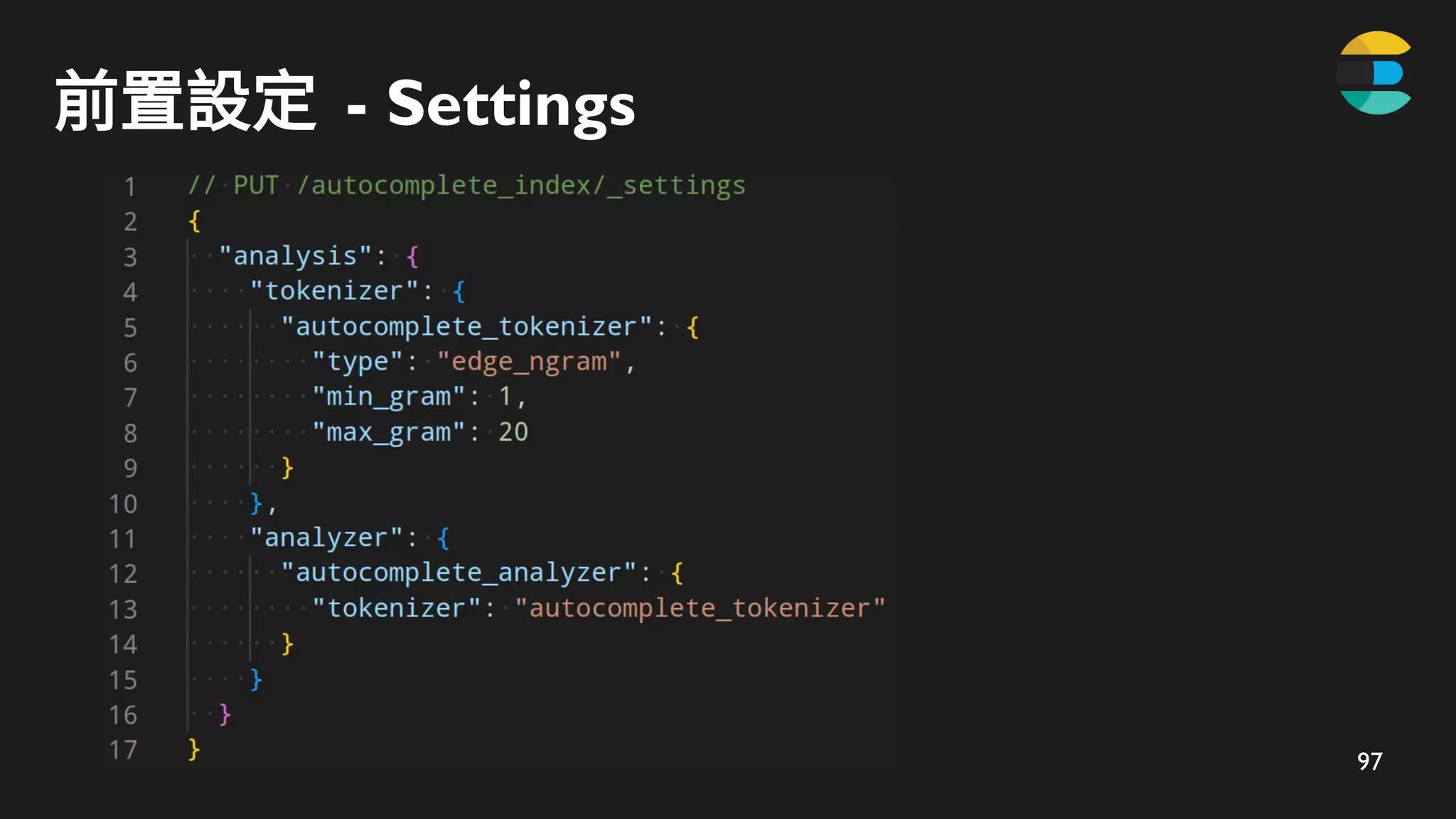
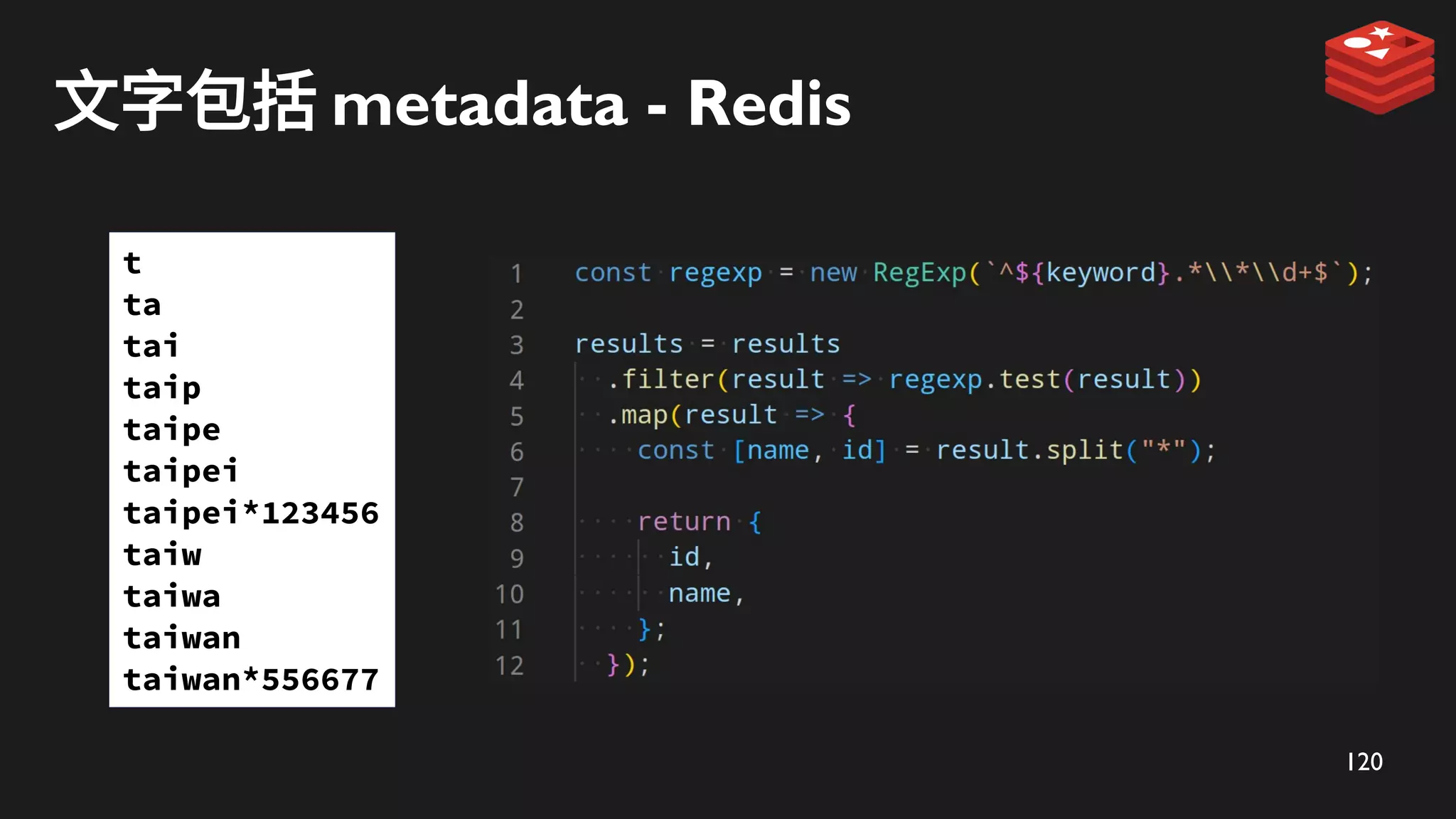
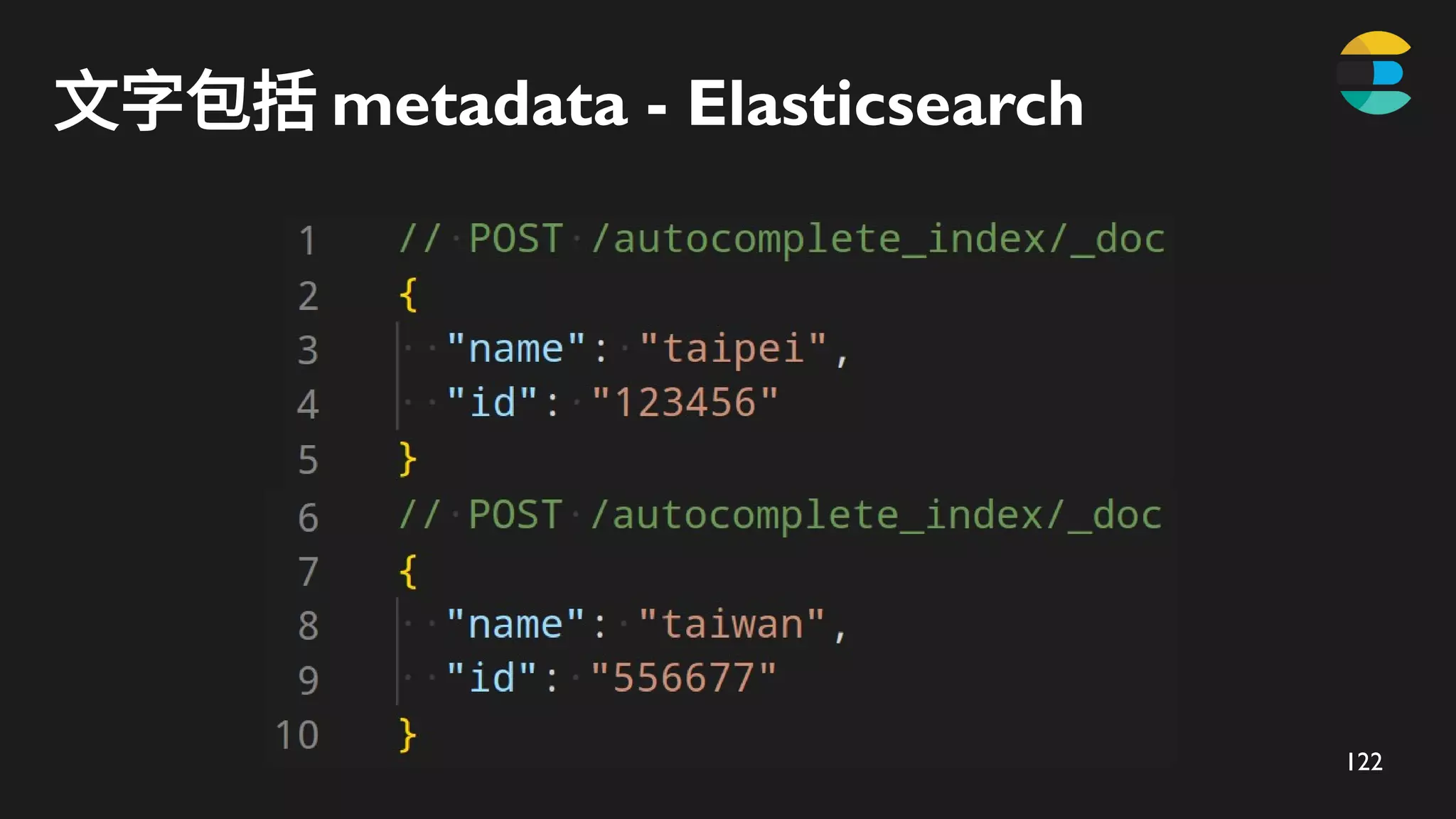
索引階段 - 使用ZADD 儲存
t
ta
tai
taip
taipe
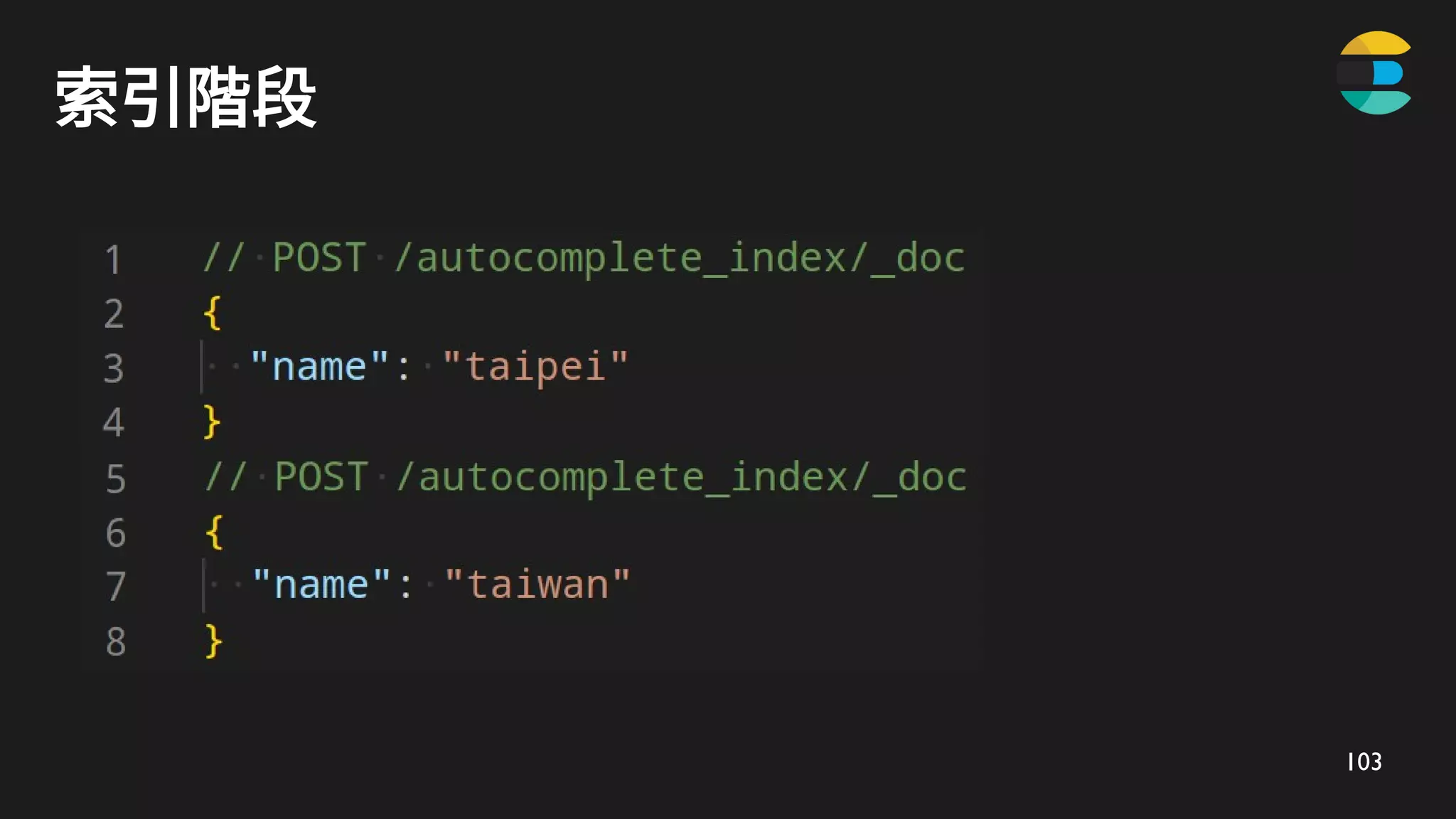
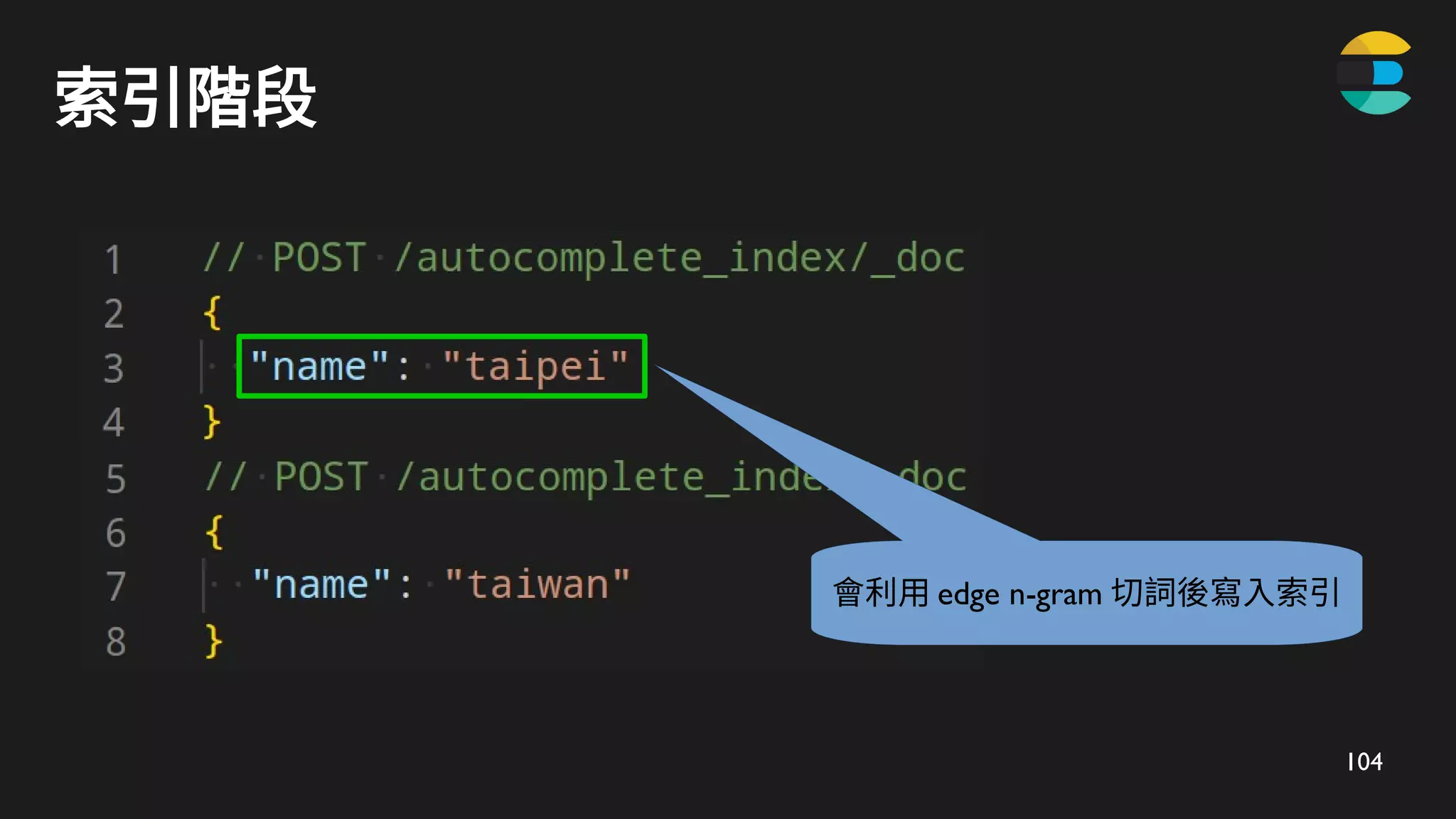
taipei
taipei*
52.
52
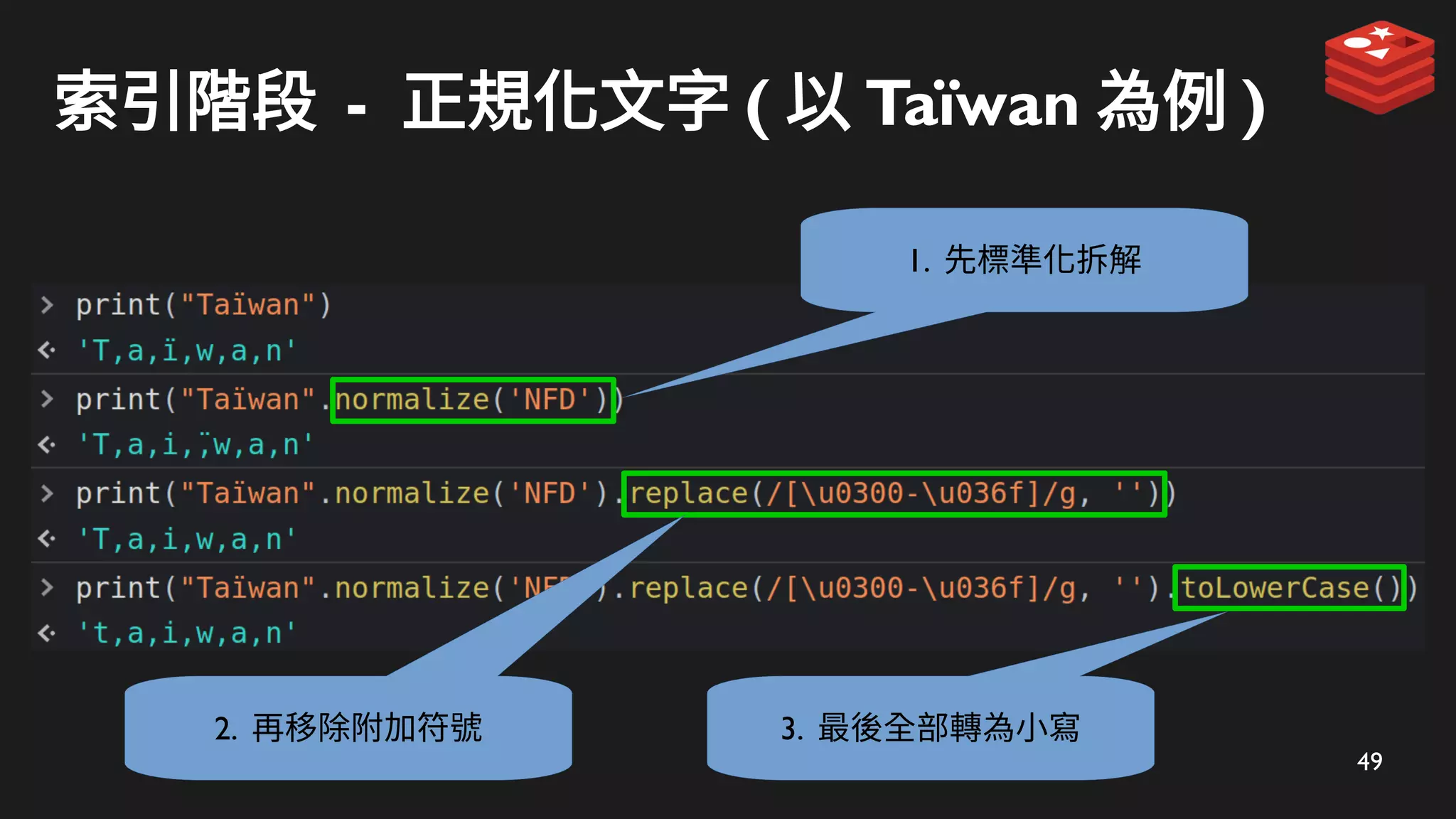
索引階段 - 使用ZADD 儲存
表示為完整的 candidate
t
ta
tai
taip
taipe
taipei
taipei*
53.
53
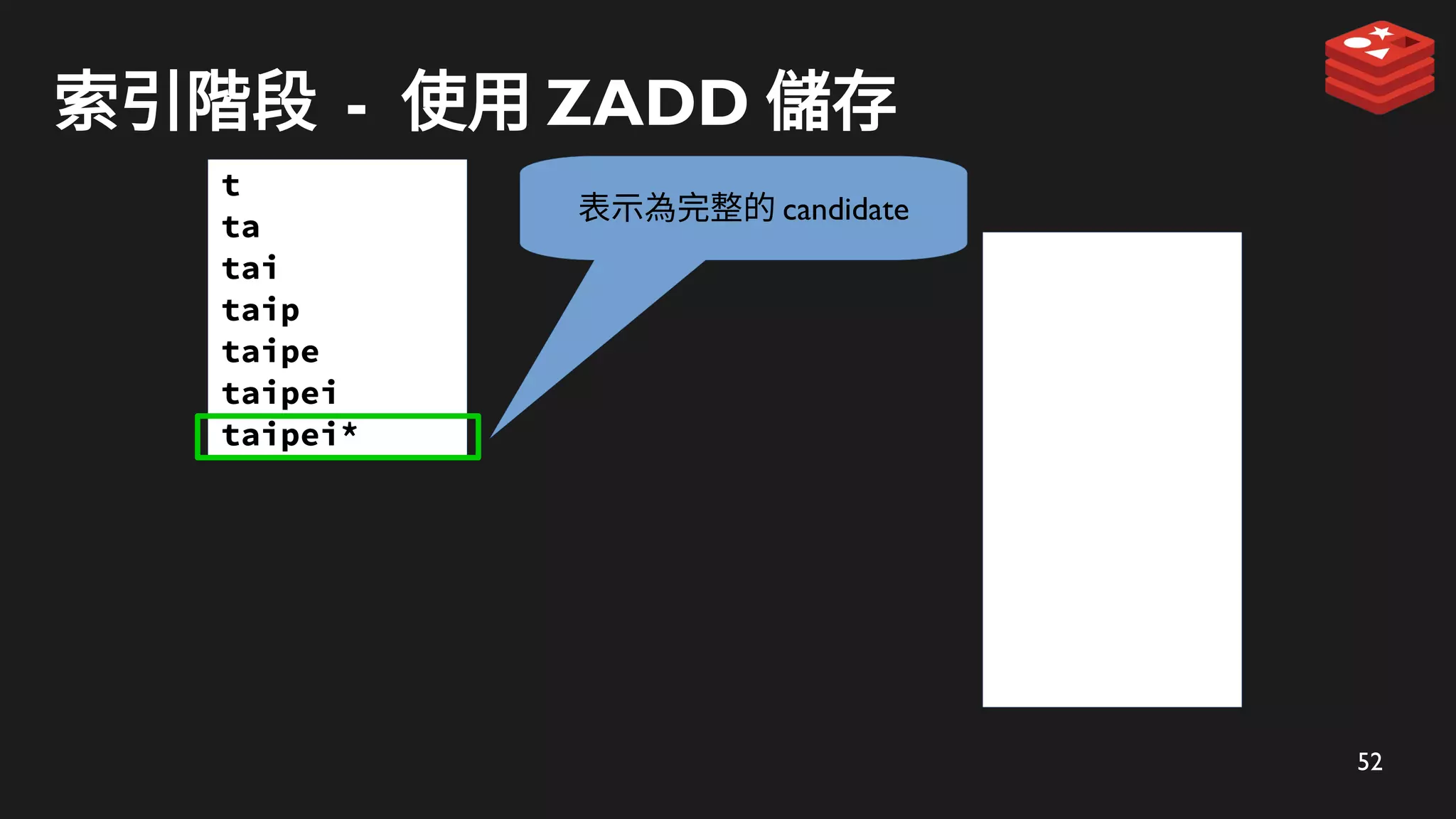
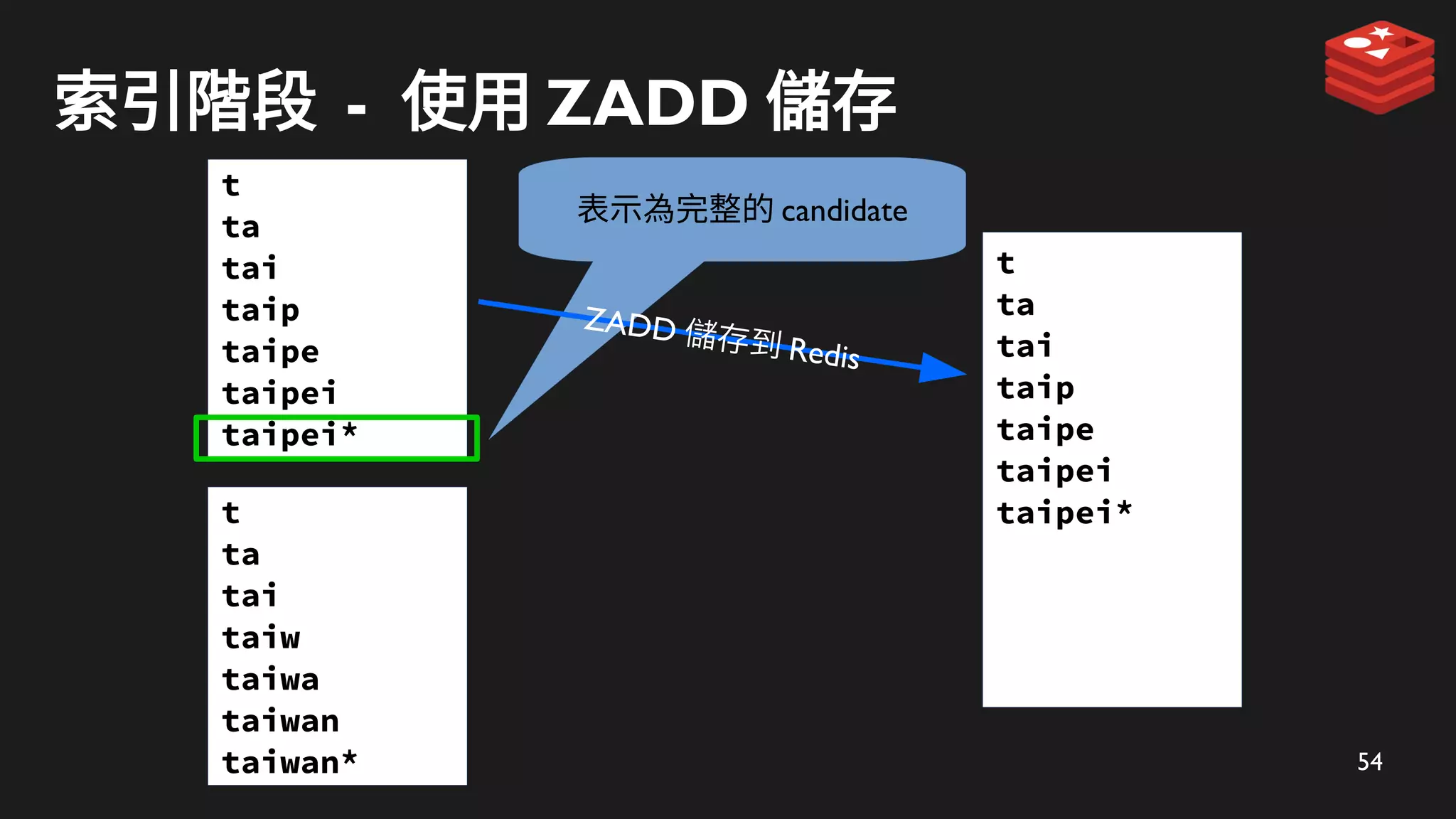
索引階段 - 使用ZADD 儲存
t
ta
tai
taip
taipe
taipei
taipei*
表示為完整的 candidate
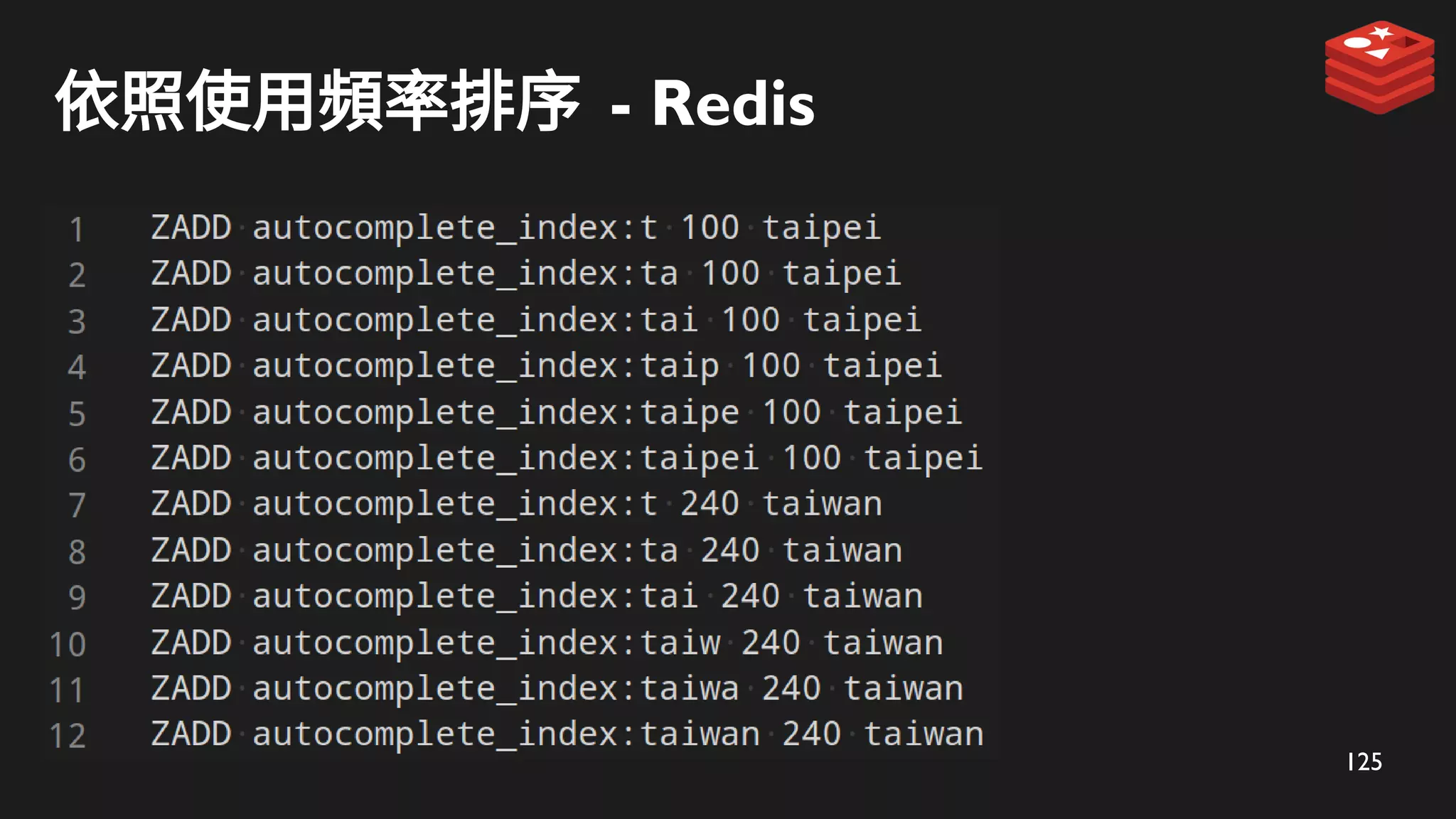
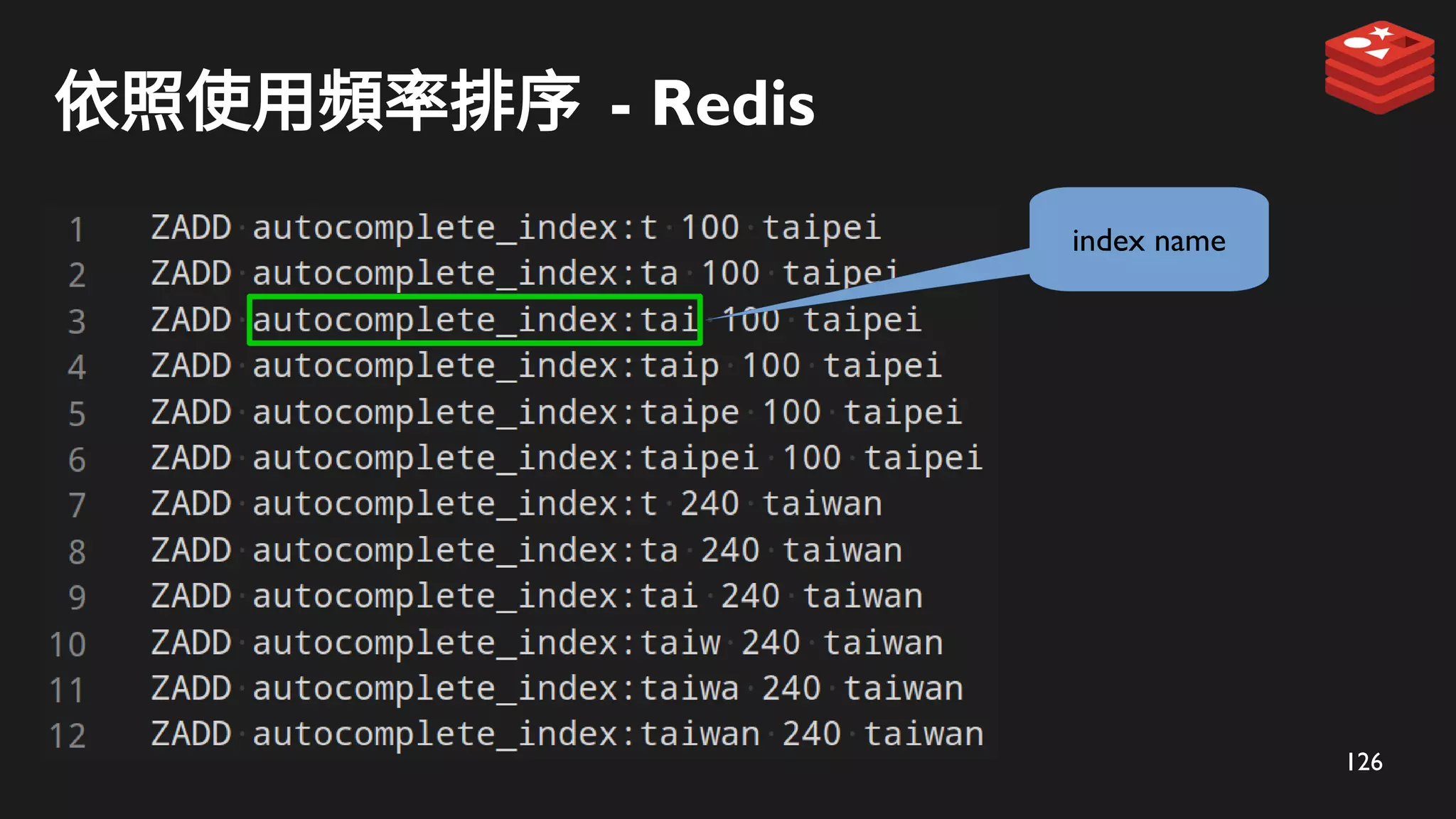
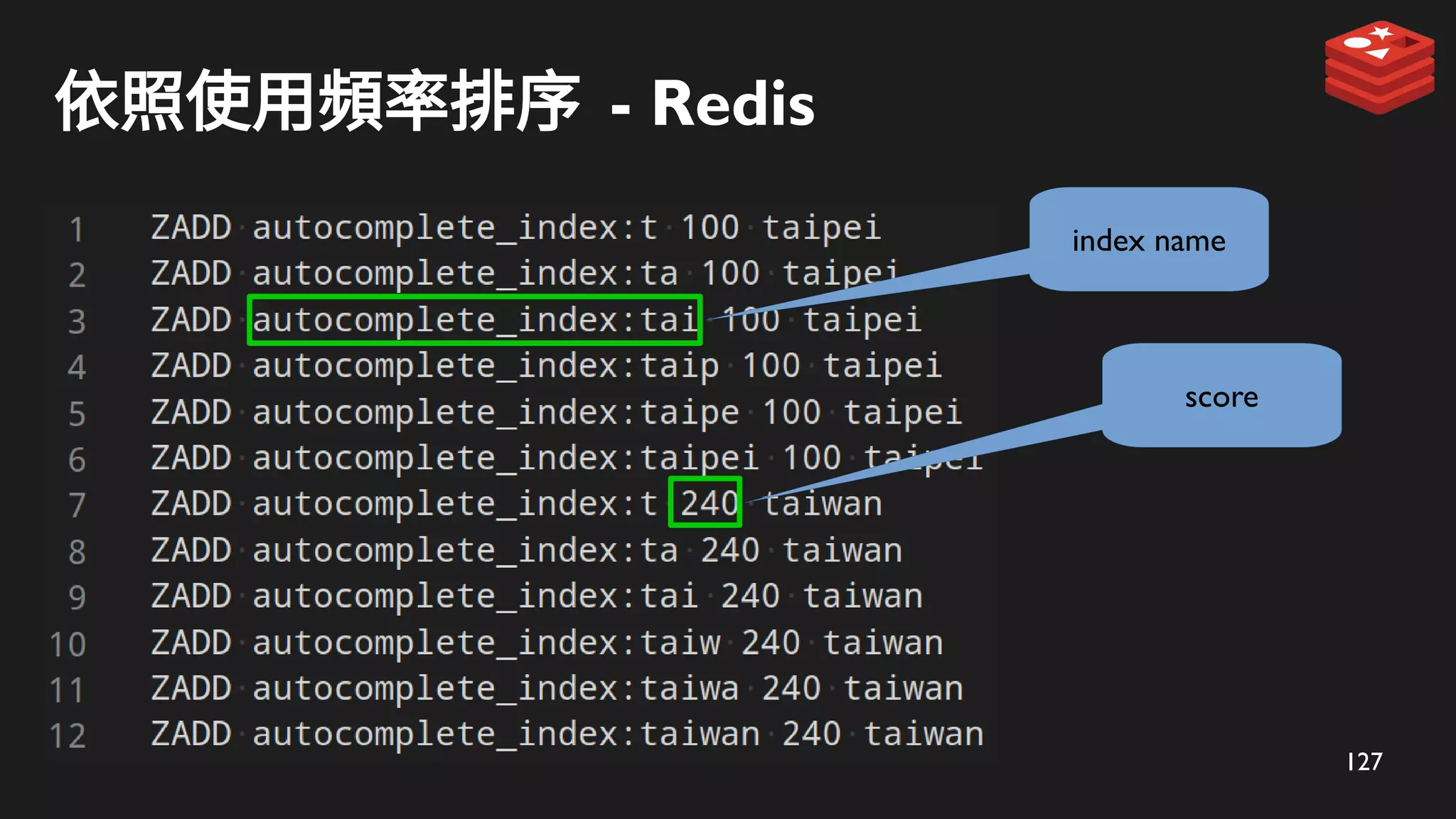
ZADD 儲存到 Redis
t
ta
tai
taip
taipe
taipei
taipei*
54.
54
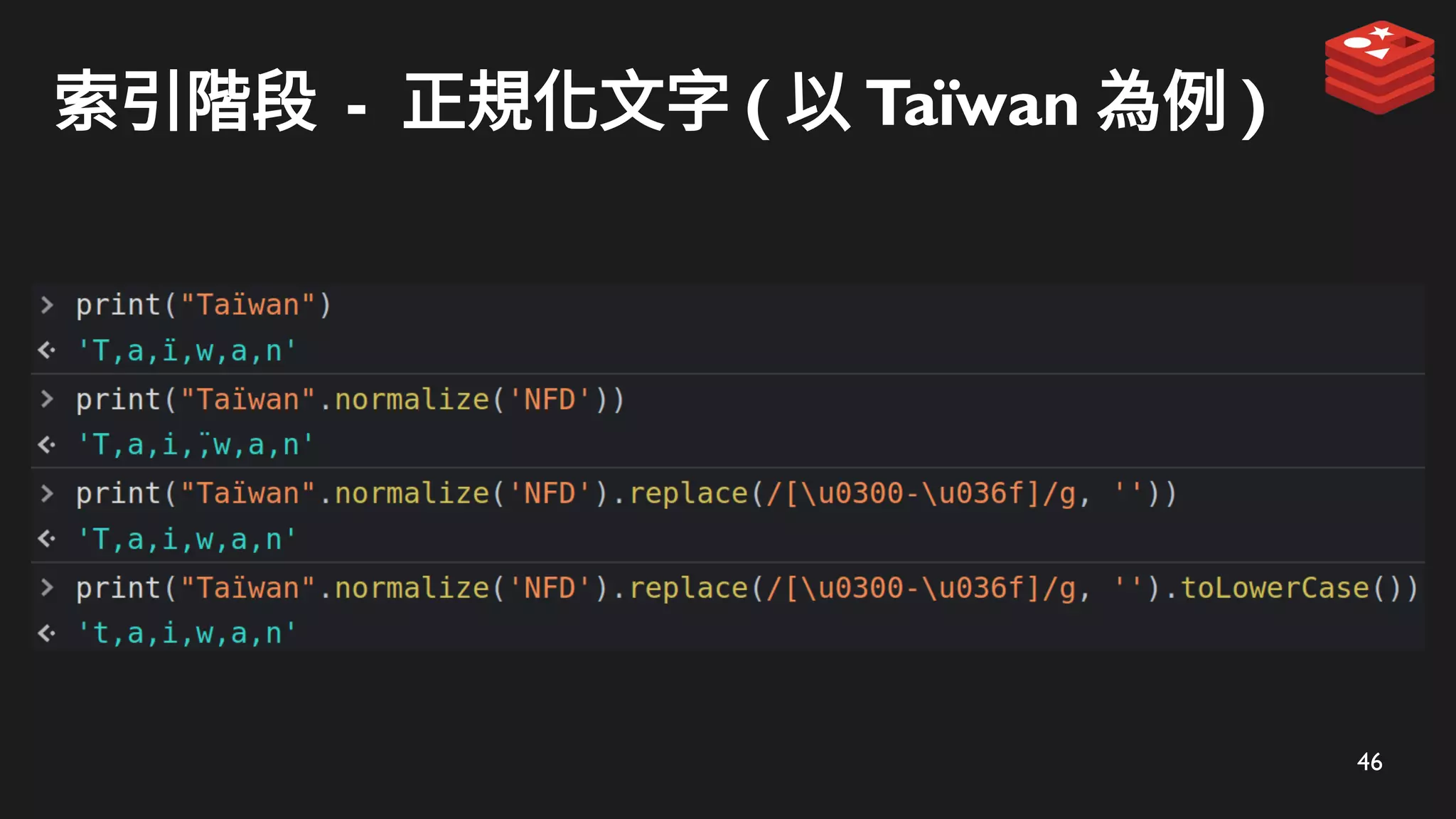
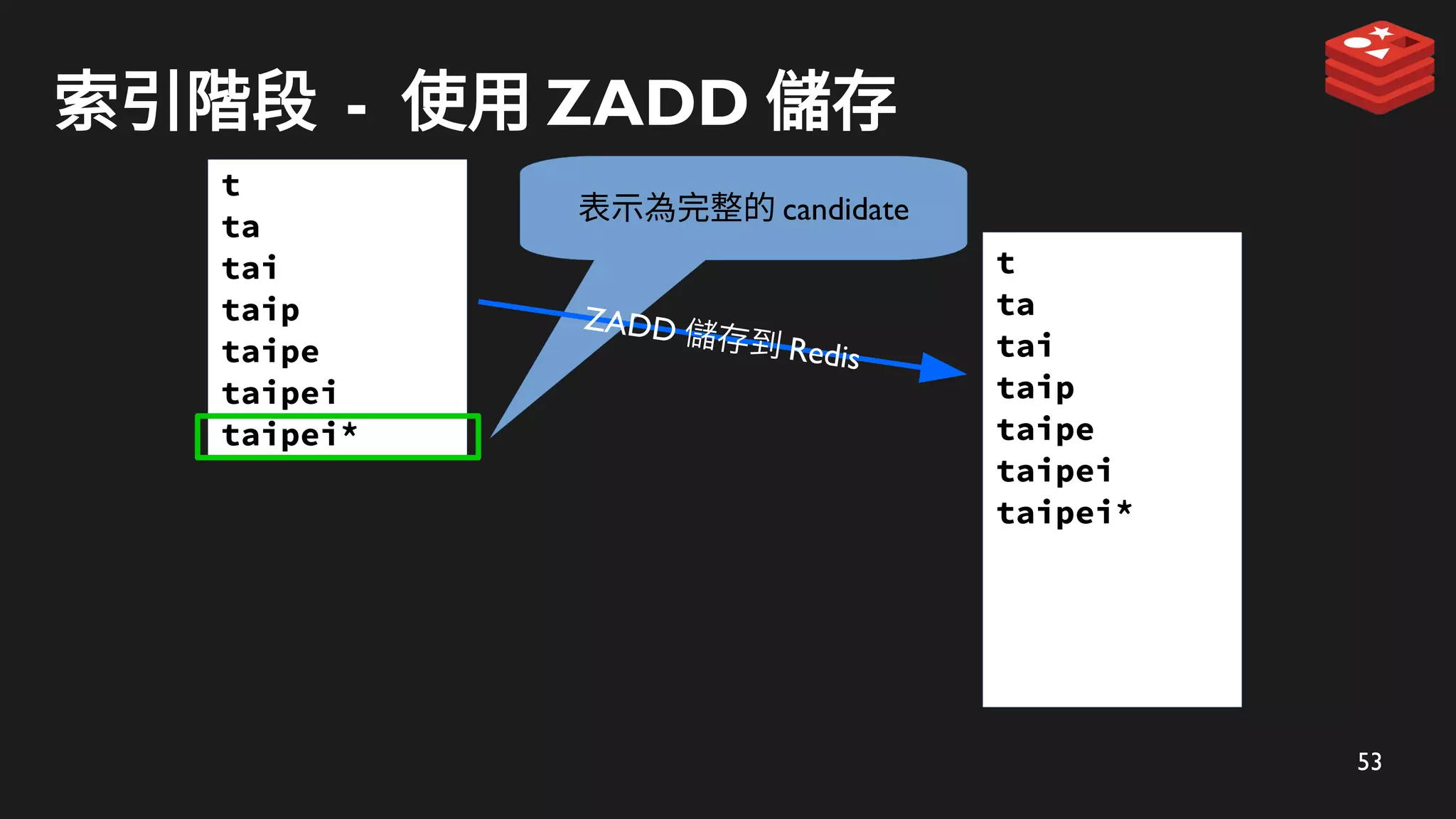
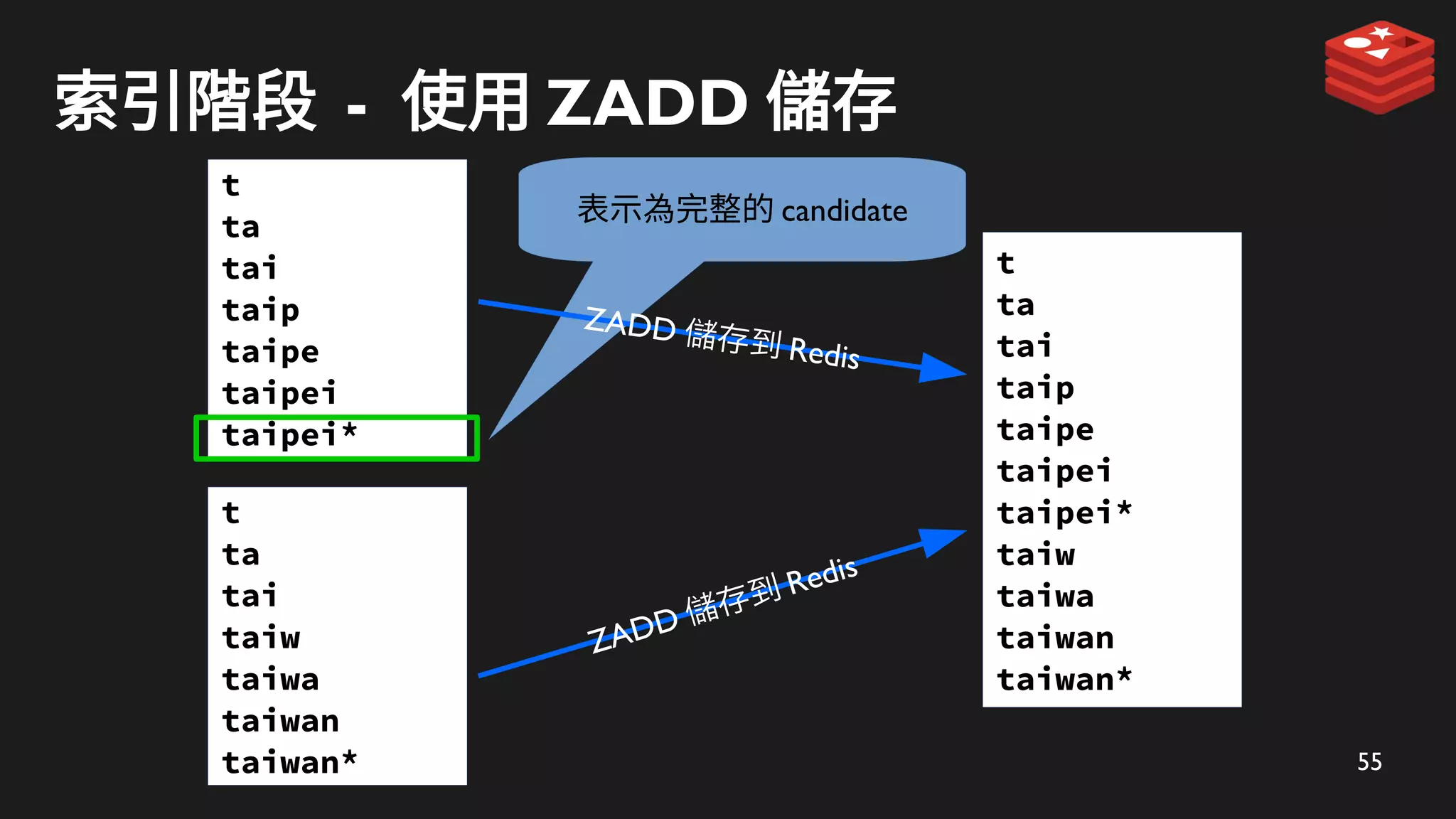
索引階段 - 使用ZADD 儲存
t
ta
tai
taip
taipe
taipei
taipei*
表示為完整的 candidate
ZADD 儲存到 Redis
t
ta
tai
taip
taipe
taipei
taipei*
t
ta
tai
taiw
taiwa
taiwan
taiwan*
55.
55
索引階段 - 使用ZADD 儲存
t
ta
tai
taip
taipe
taipei
taipei*
taiw
taiwa
taiwan
taiwan*
表示為完整的 candidate
ZADD 儲存到 Redis
t
ta
tai
taip
taipe
taipei
taipei*
t
ta
tai
taiw
taiwa
taiwan
taiwan*
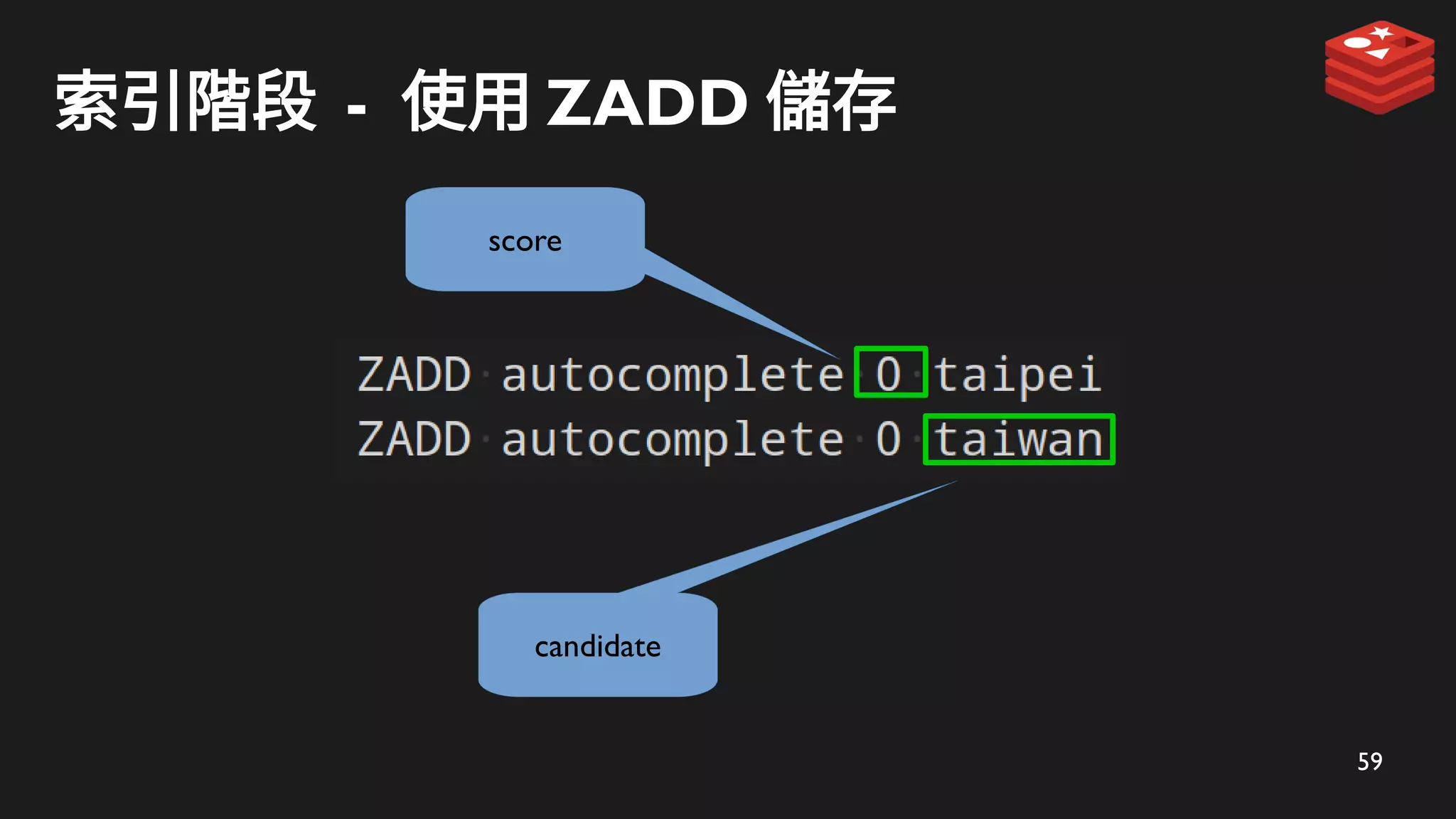
ZADD 儲存到 Redis
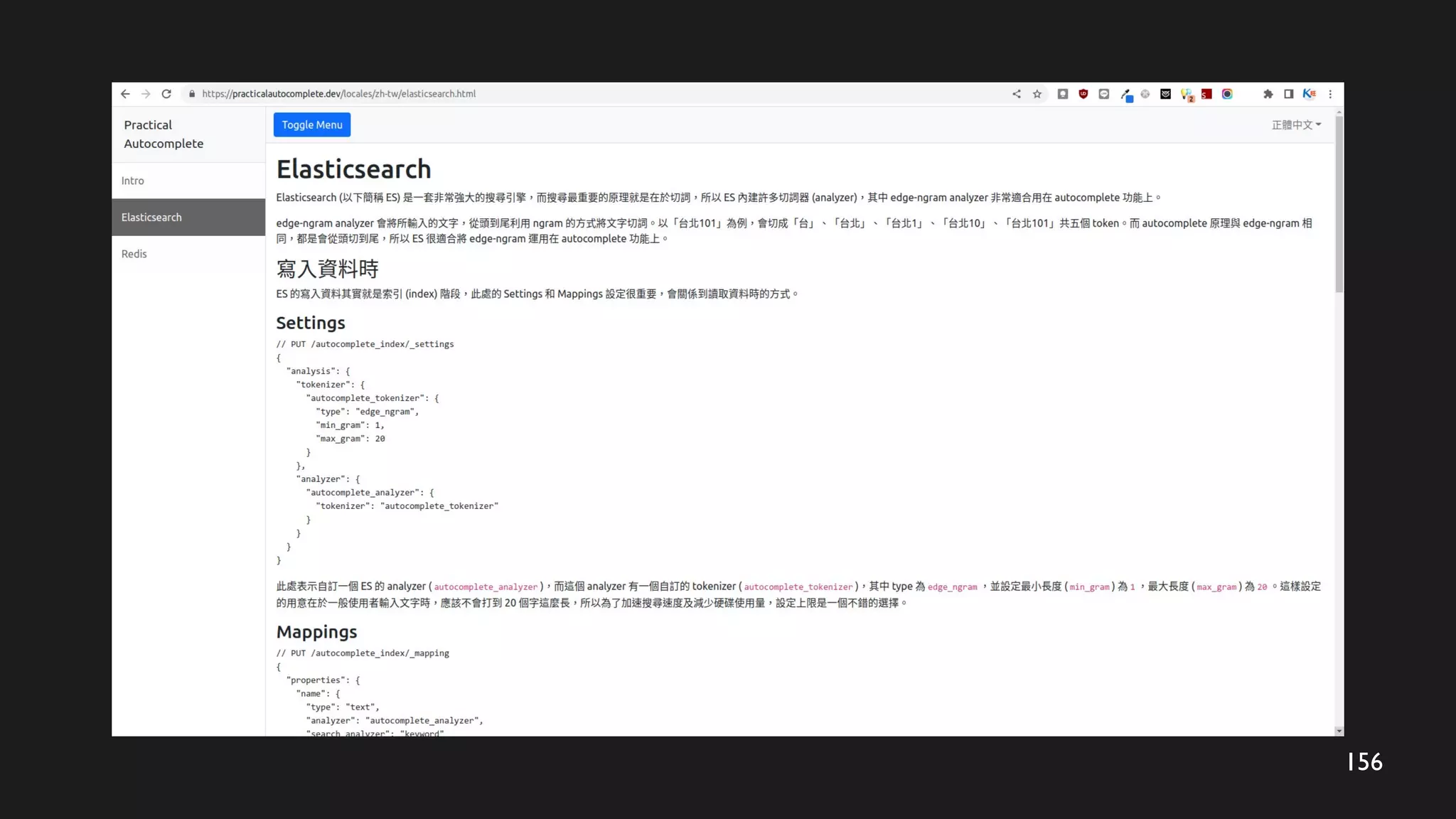
64
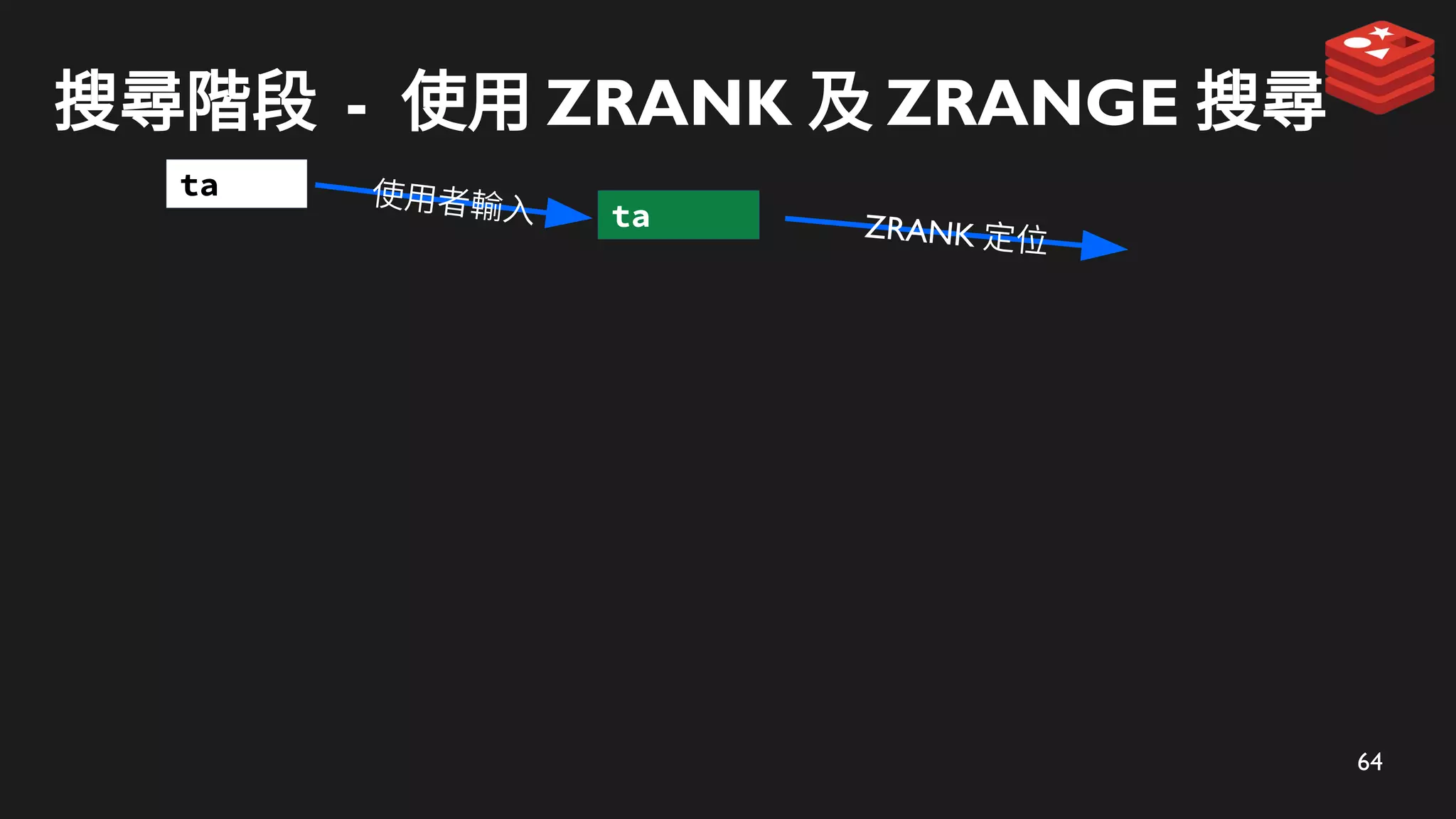
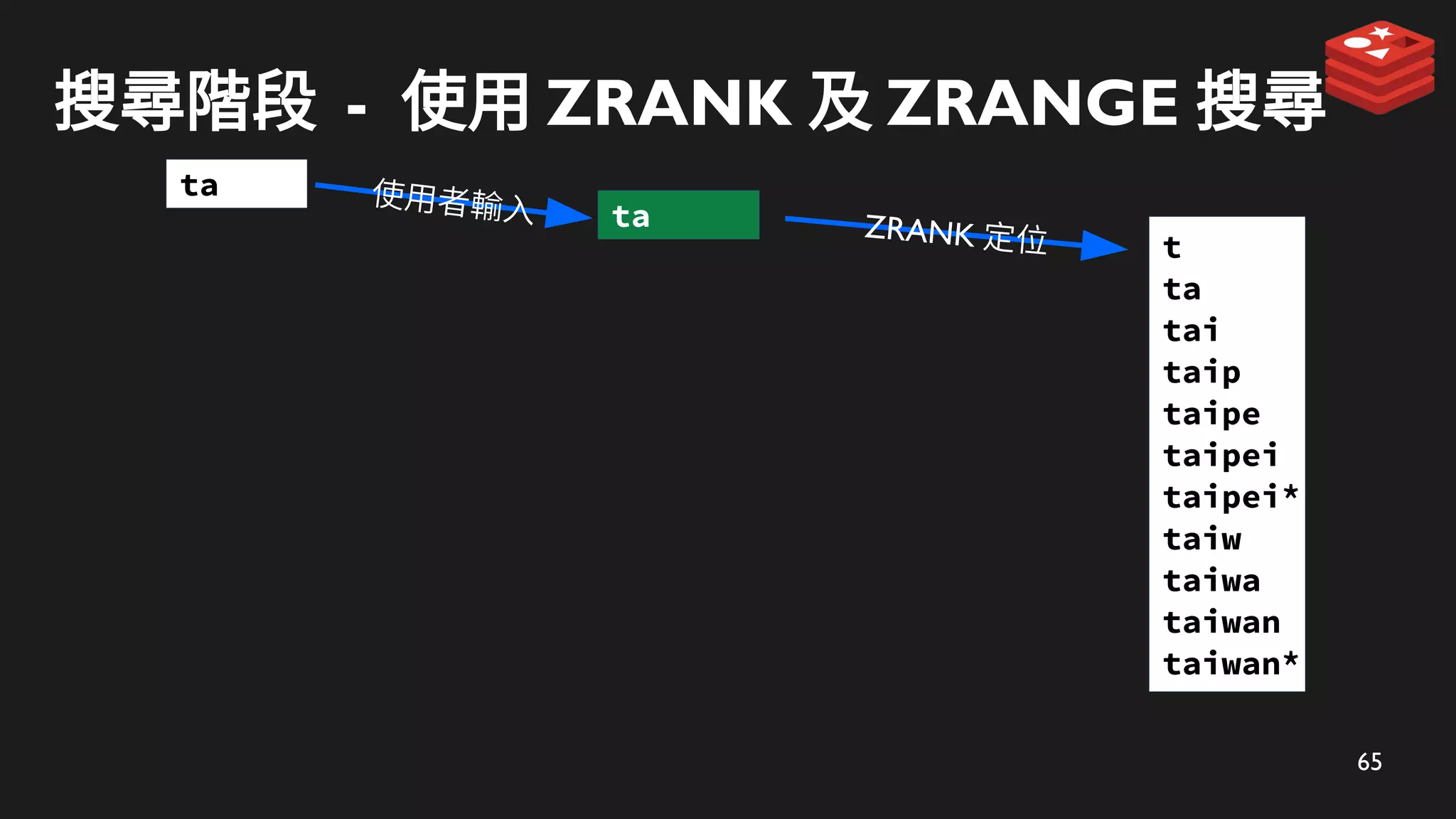
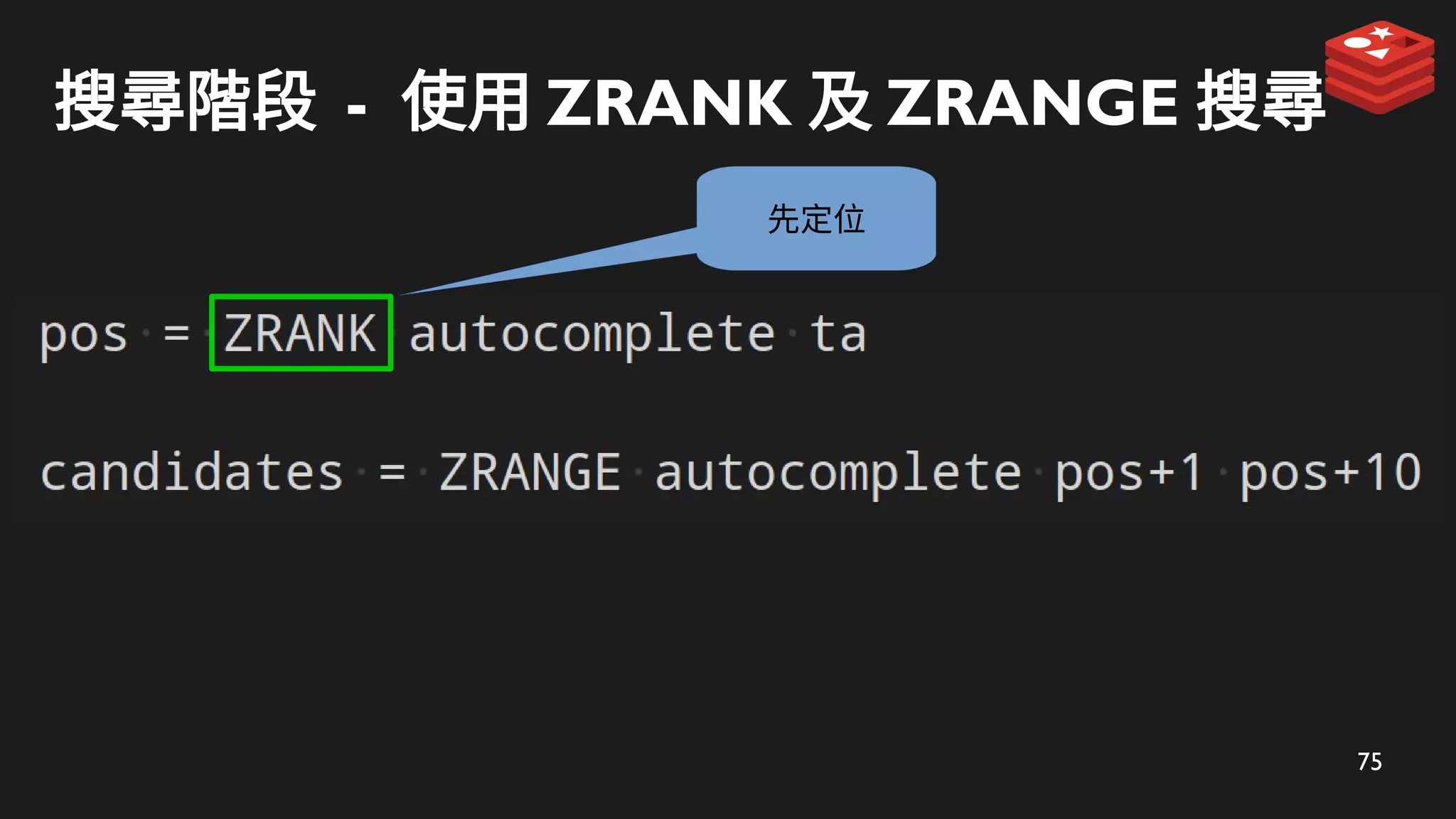
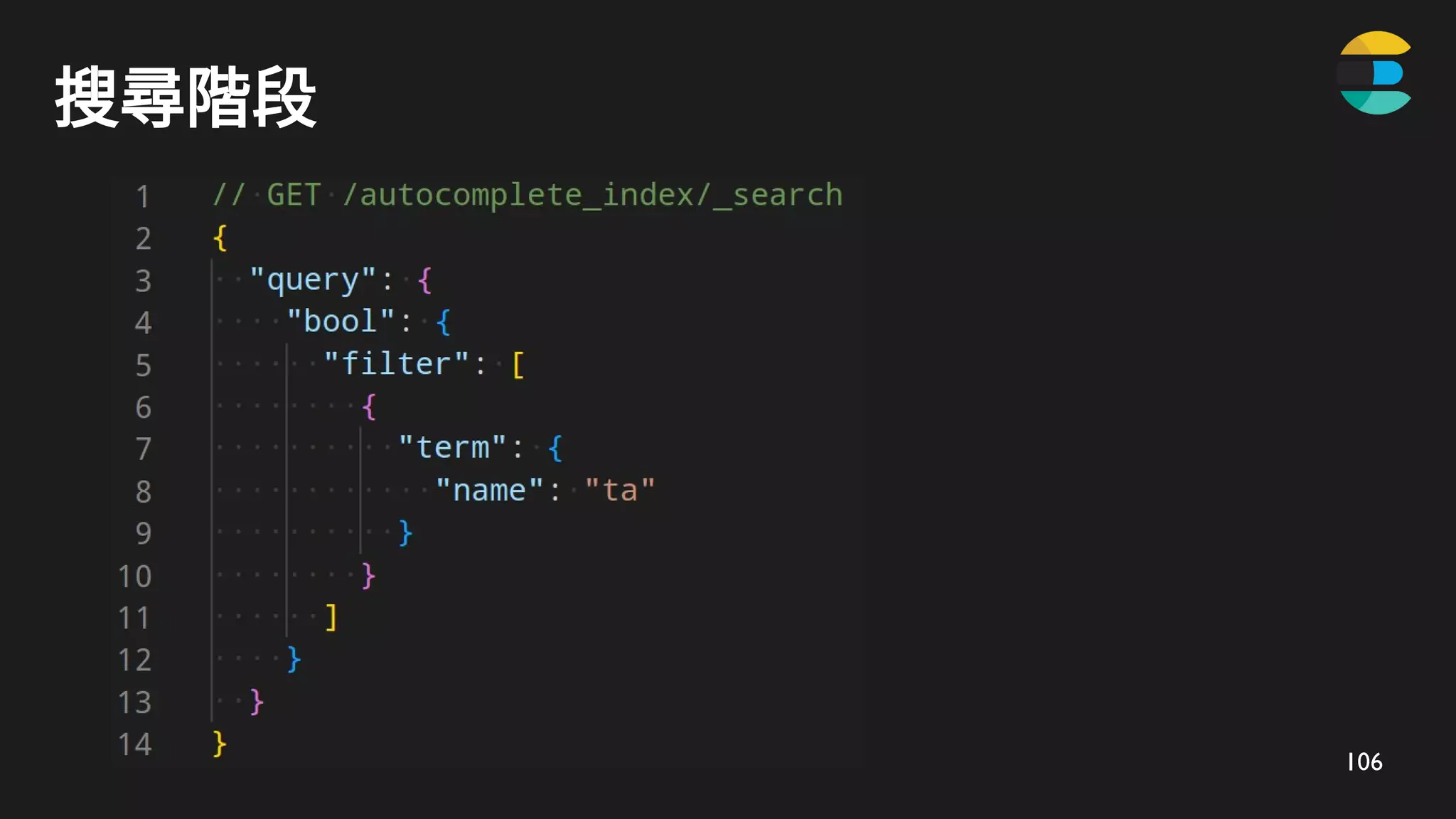
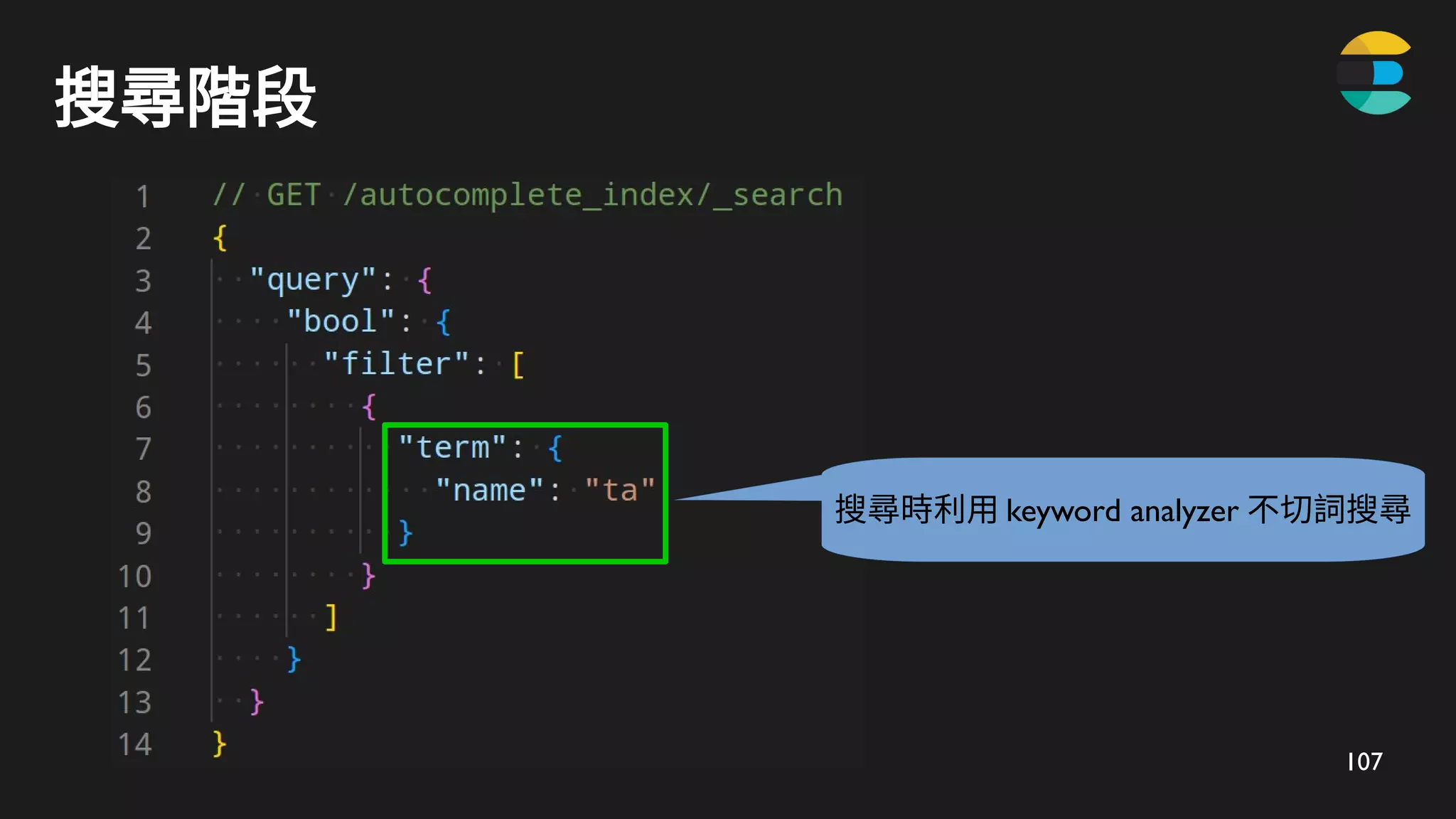
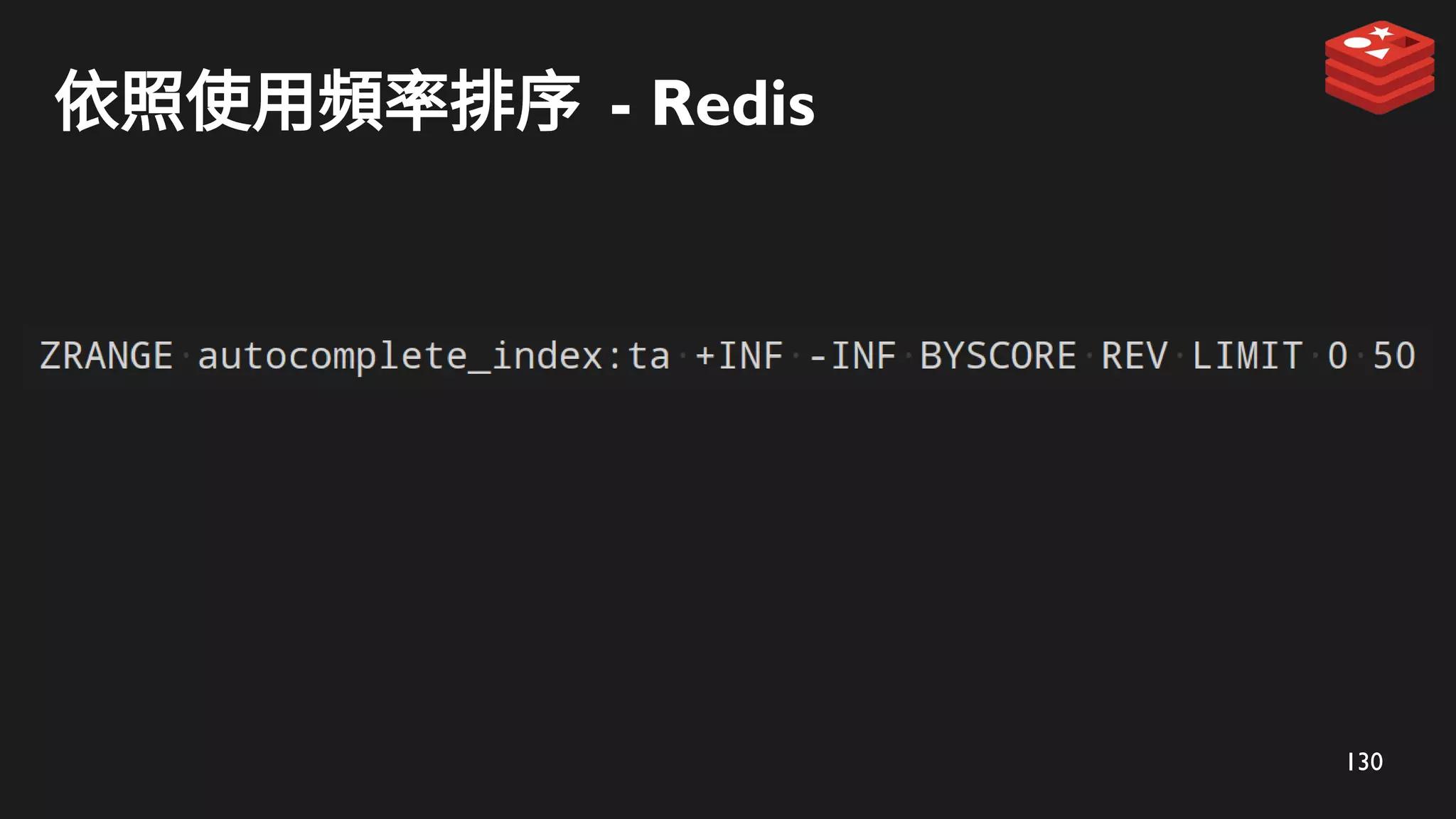
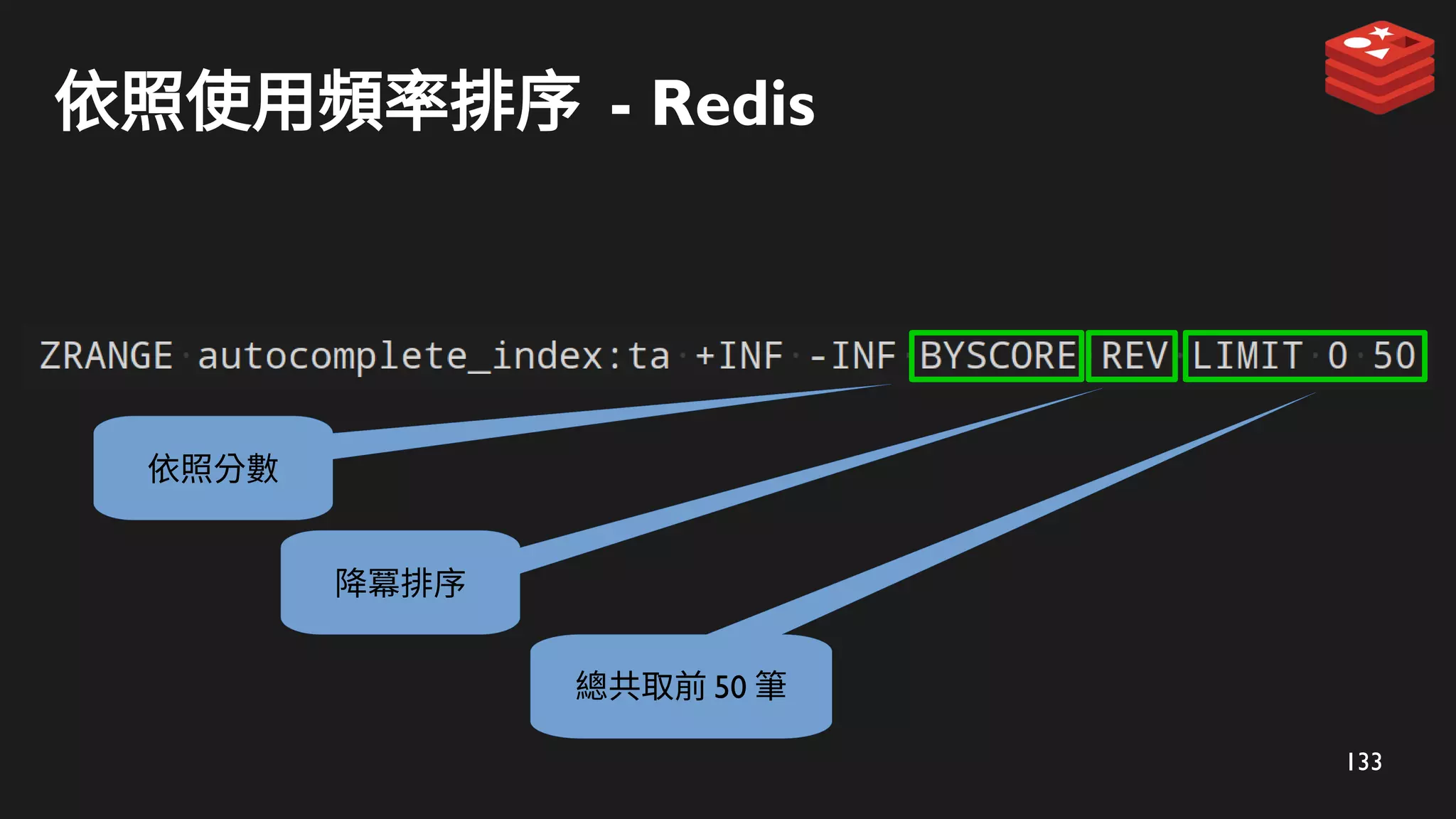
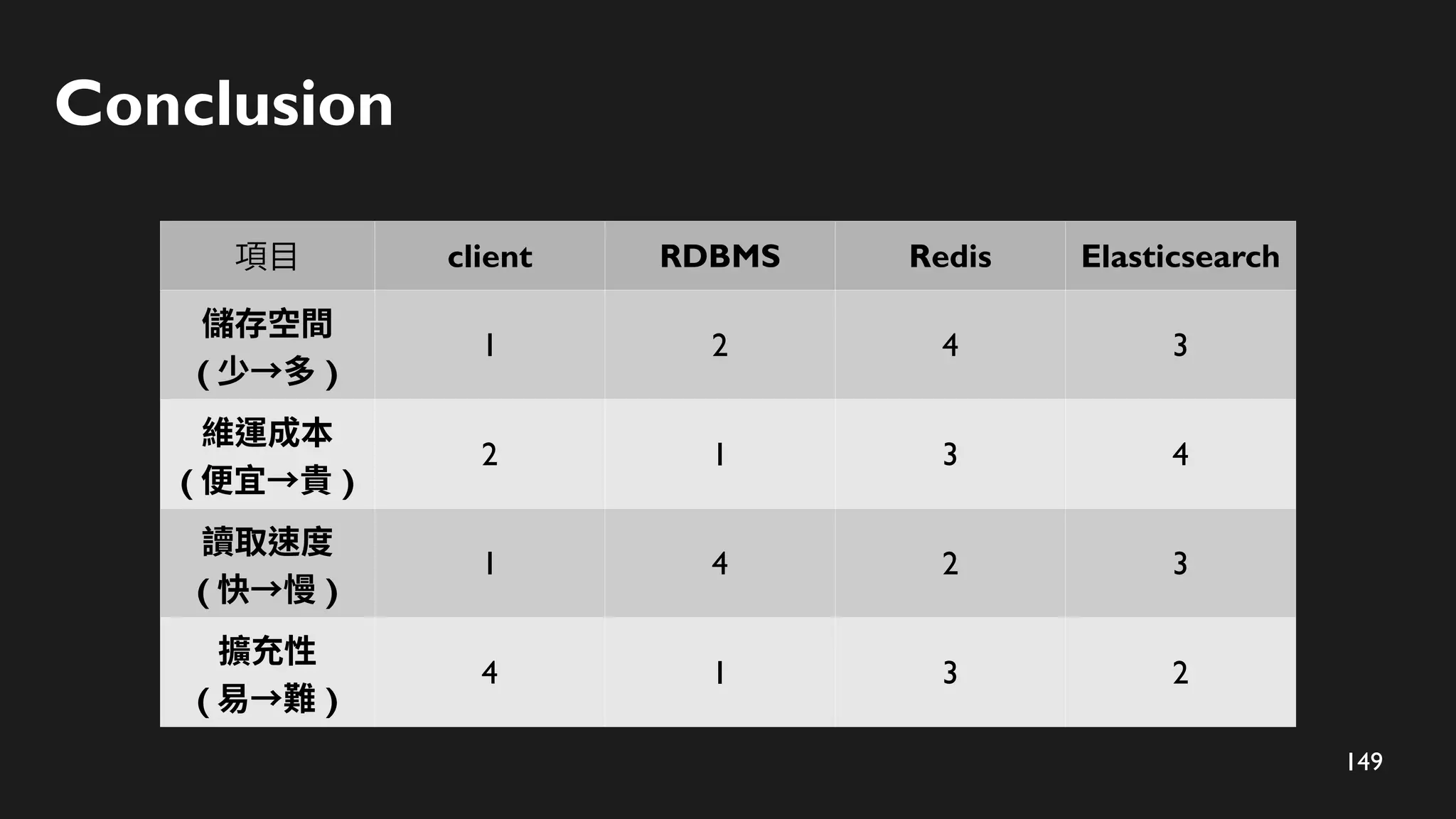
搜尋階段 - 使用ZRANK 及 ZRANGE 搜尋
ZRANK 定位
ta
使用者輸入
ta
65.
65
搜尋階段 - 使用ZRANK 及 ZRANGE 搜尋
t
ta
tai
taip
taipe
taipei
taipei*
taiw
taiwa
taiwan
taiwan*
ZRANK 定位
ta
使用者輸入
ta
66.
66
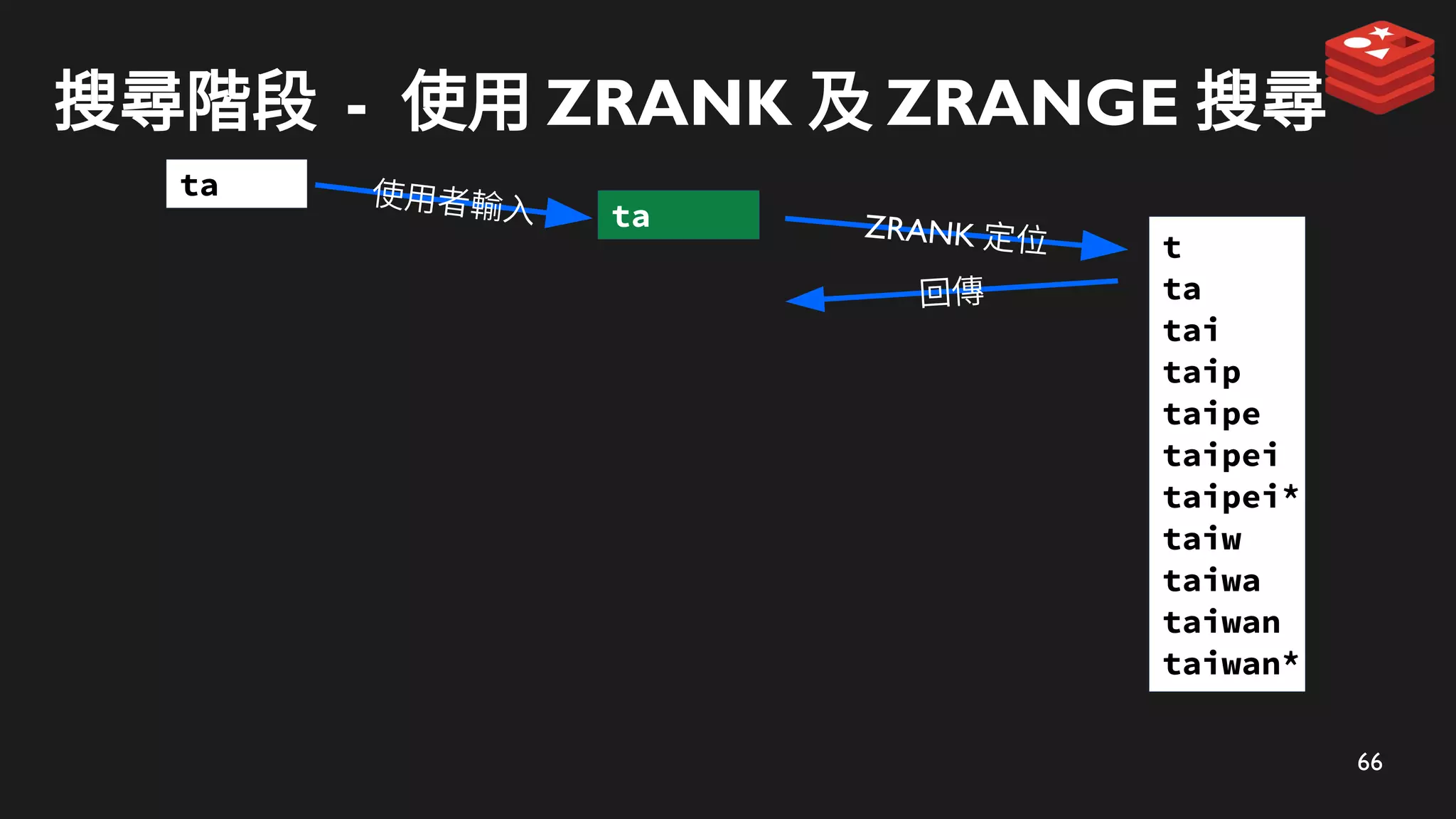
搜尋階段 - 使用ZRANK 及 ZRANGE 搜尋
t
ta
tai
taip
taipe
taipei
taipei*
taiw
taiwa
taiwan
taiwan*
ZRANK 定位
ta
回傳
使用者輸入
ta
67.
67
搜尋階段 - 使用ZRANK 及 ZRANGE 搜尋
t
ta
tai
taip
taipe
taipei
taipei*
taiw
taiwa
taiwan
taiwan*
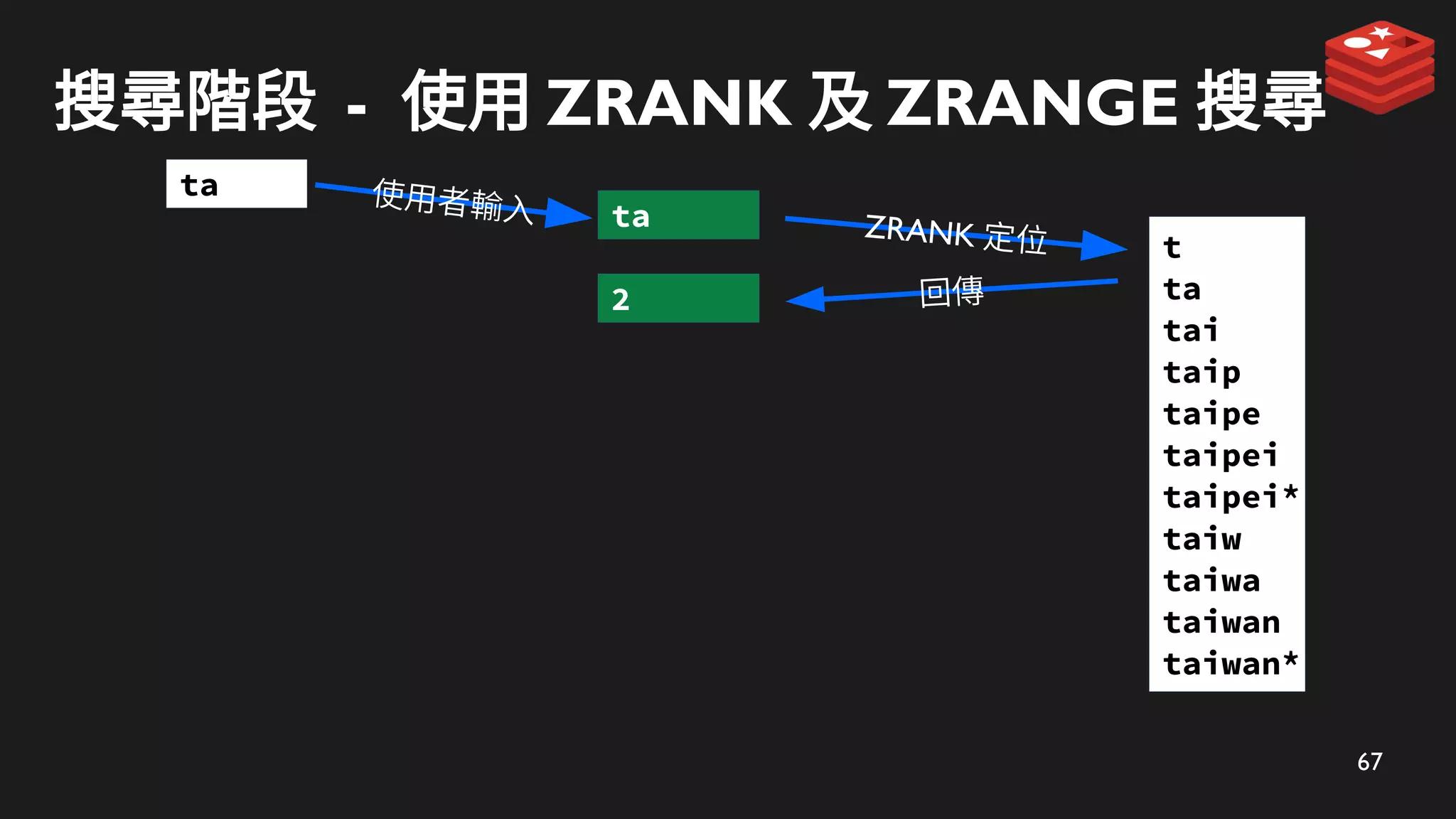
ZRANK 定位
ta
回傳
2
使用者輸入
ta
68.
68
搜尋階段 - 使用ZRANK 及 ZRANGE 搜尋
t
ta
tai
taip
taipe
taipei
taipei*
taiw
taiwa
taiwan
taiwan*
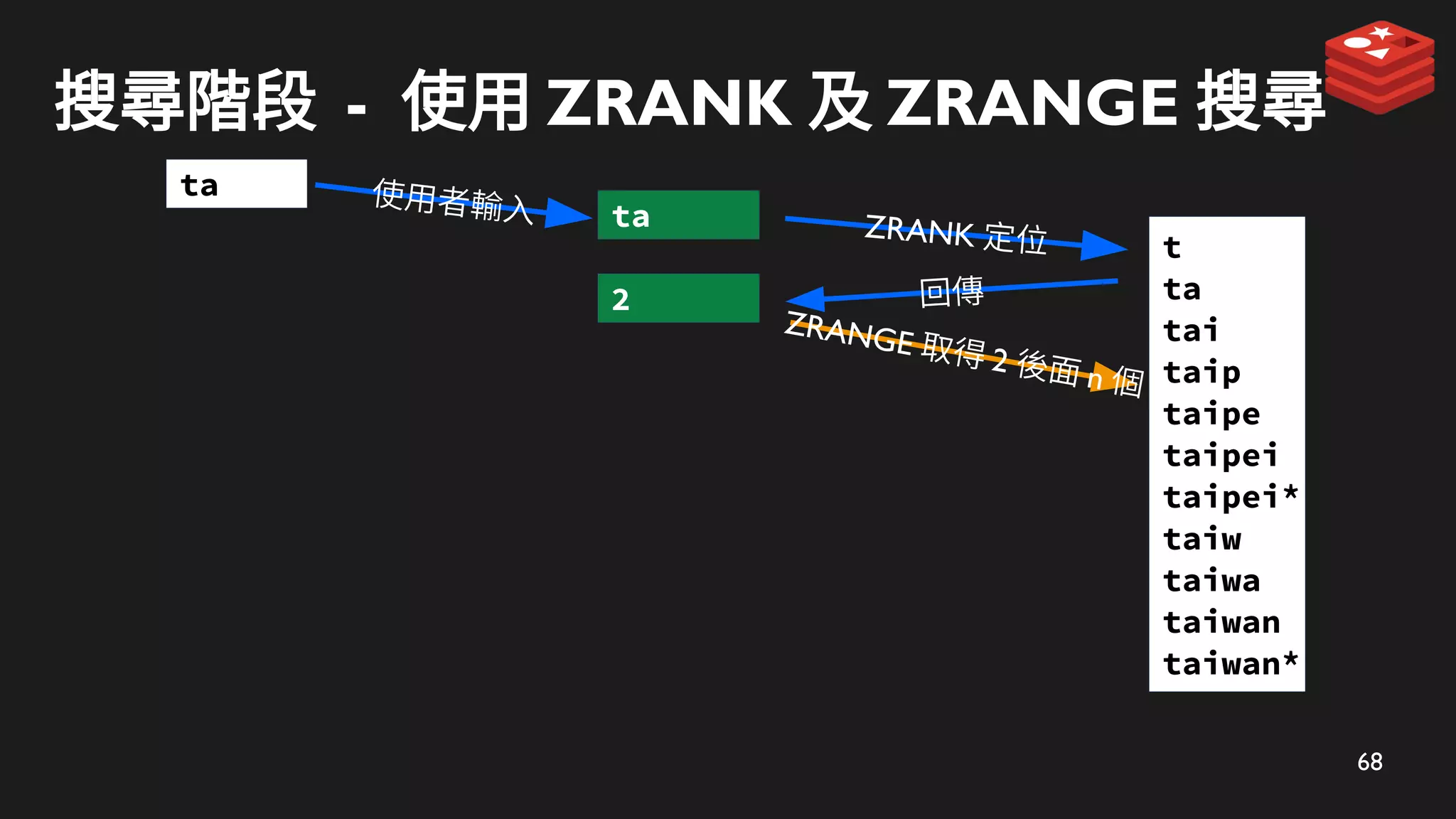
ZRANK 定位
ta
ZRANGE 取得 2 後面 n 個
回傳
2
使用者輸入
ta
69.
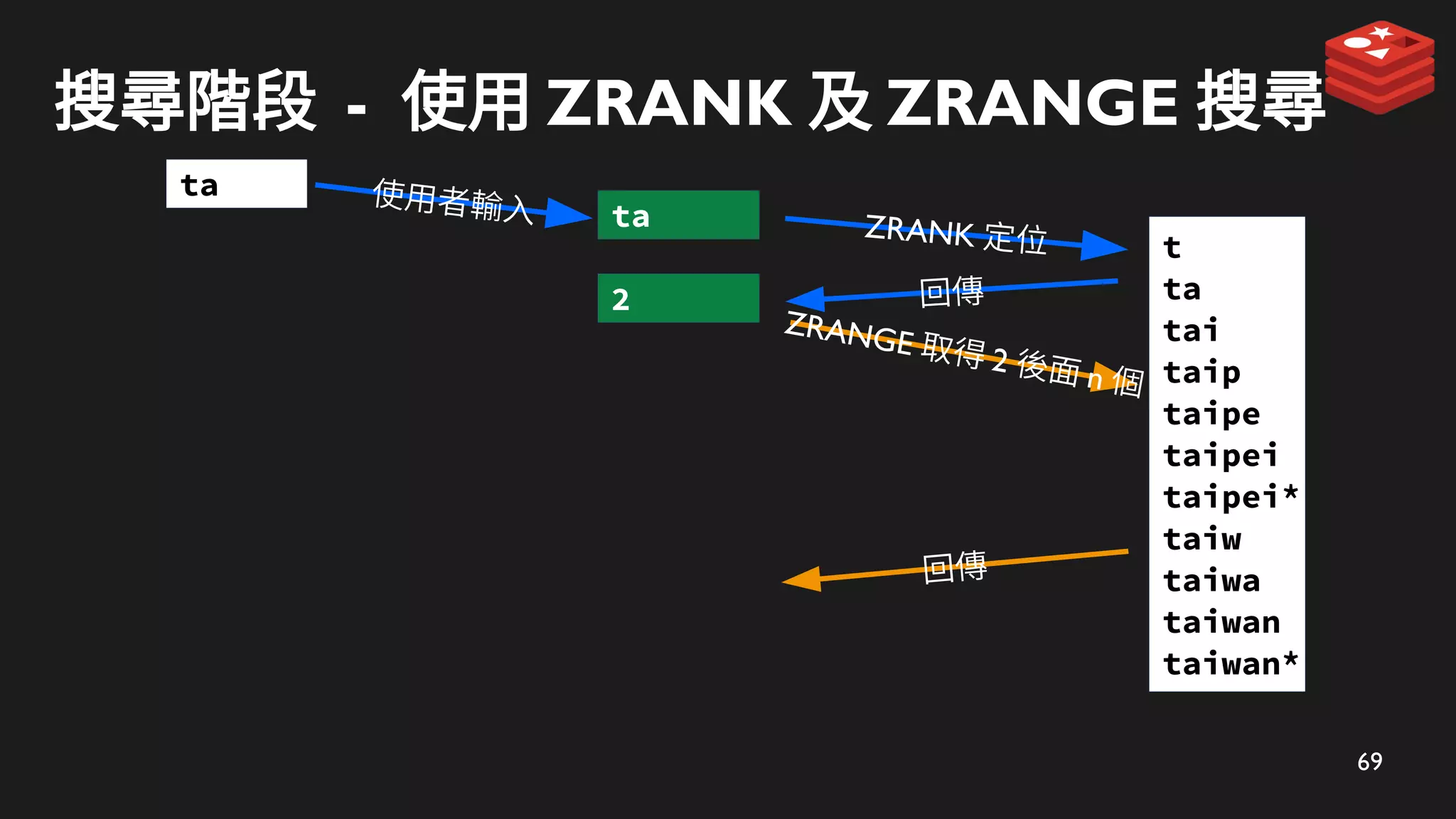
69
搜尋階段 - 使用ZRANK 及 ZRANGE 搜尋
t
ta
tai
taip
taipe
taipei
taipei*
taiw
taiwa
taiwan
taiwan*
ZRANK 定位
ta
ZRANGE 取得 2 後面 n 個
回傳
2
回傳
使用者輸入
ta
70.
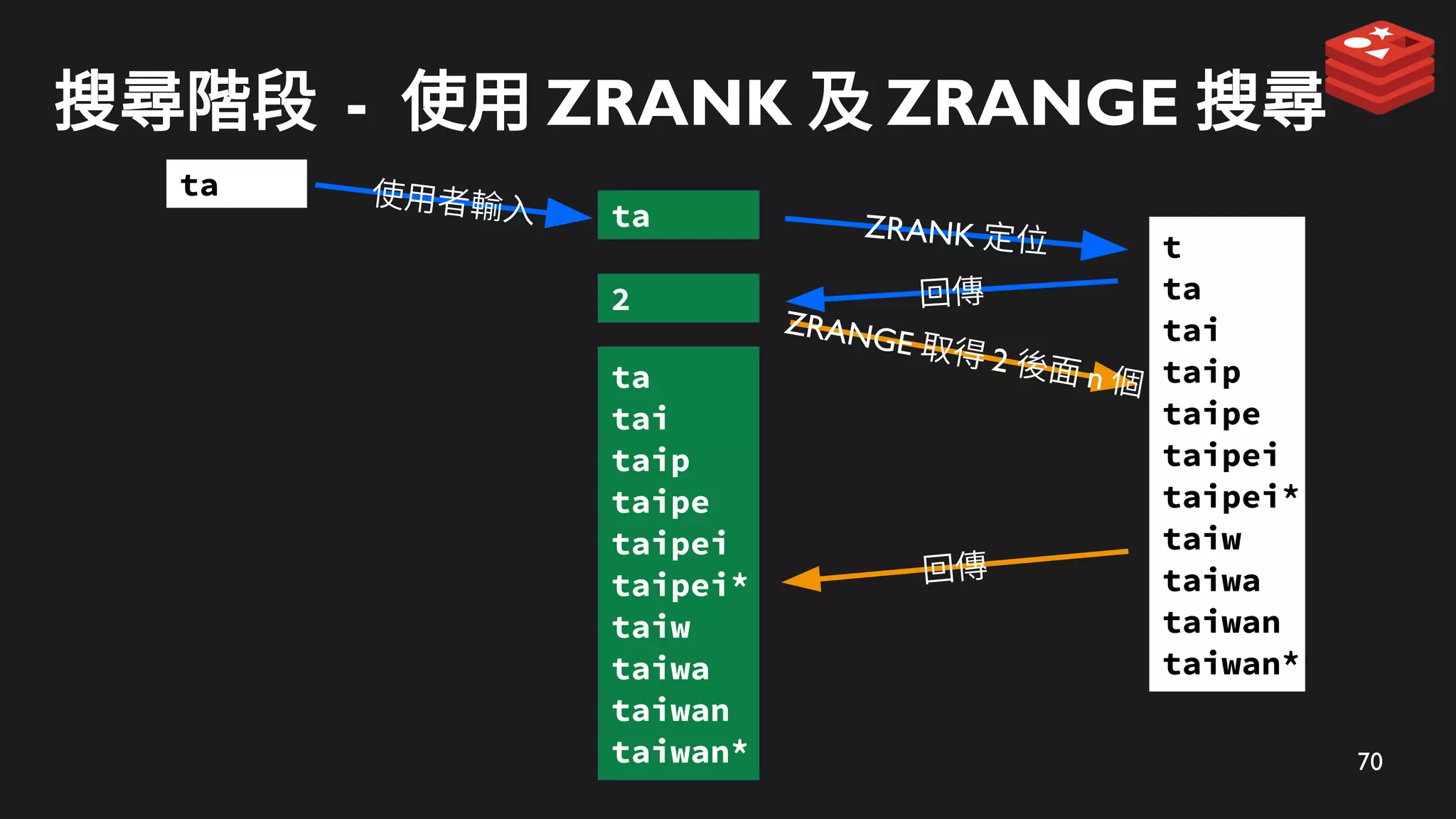
70
搜尋階段 - 使用ZRANK 及 ZRANGE 搜尋
t
ta
tai
taip
taipe
taipei
taipei*
taiw
taiwa
taiwan
taiwan*
ZRANK 定位
ta
ZRANGE 取得 2 後面 n 個
回傳
2
回傳
ta
tai
taip
taipe
taipei
taipei*
taiw
taiwa
taiwan
taiwan*
使用者輸入
ta
71.
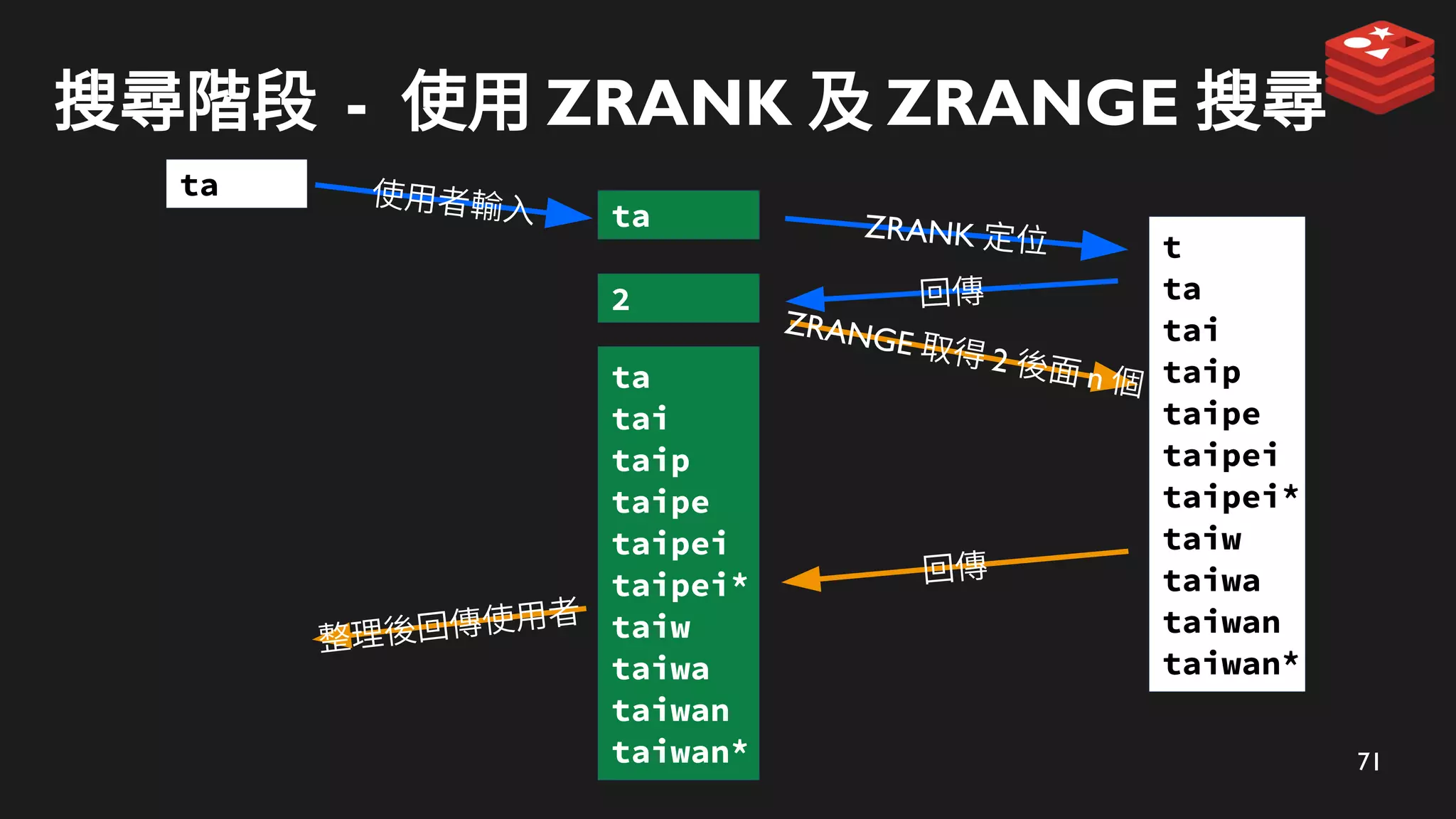
71
搜尋階段 - 使用ZRANK 及 ZRANGE 搜尋
t
ta
tai
taip
taipe
taipei
taipei*
taiw
taiwa
taiwan
taiwan*
ZRANK 定位
ta
ZRANGE 取得 2 後面 n 個
回傳
2
回傳
ta
tai
taip
taipe
taipei
taipei*
taiw
taiwa
taiwan
taiwan*
整理後回傳使用者
使用者輸入
ta
72.
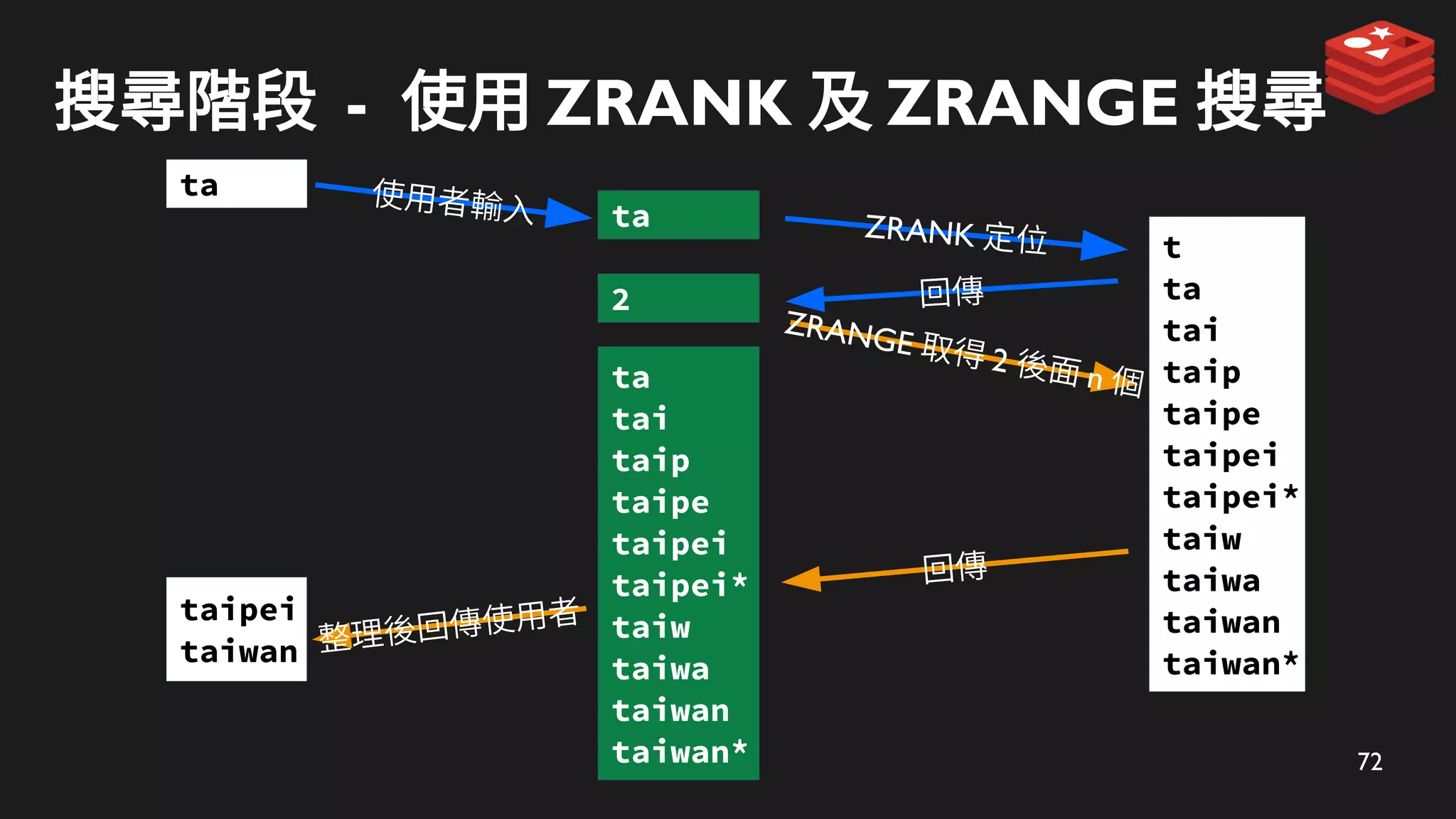
72
搜尋階段 - 使用ZRANK 及 ZRANGE 搜尋
t
ta
tai
taip
taipe
taipei
taipei*
taiw
taiwa
taiwan
taiwan*
ZRANK 定位
ta
ZRANGE 取得 2 後面 n 個
回傳
2
回傳
ta
tai
taip
taipe
taipei
taipei*
taiw
taiwa
taiwan
taiwan*
整理後回傳使用者
taipei
taiwan
使用者輸入
ta







































































































































![[CEDEC2017] LINEゲームのセキュリティ診断手法](https://cdn.slidesharecdn.com/ss_thumbnails/cedec2017game1web-170831030226-thumbnail.jpg?width=640&height=640&fit=bounds)





















































