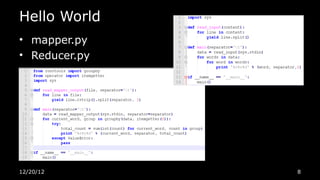
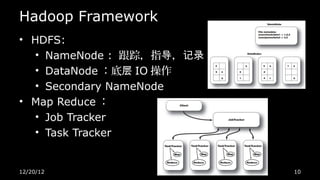
本文件介绍了 Hadoop 的背景、安装和基本操作,包括与 SQL 数据库的比较以及 Hadoop 的关键特性,如可扩展性和健壮性。它详细说明了如何实现一个简单的词频计算示例,以及 Hadoop 框架的组成部分和常用编程语言。文件还列出了相关工具和资源以供深入学习。