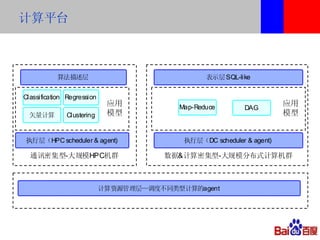
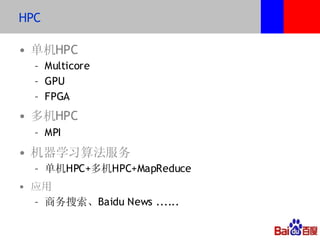
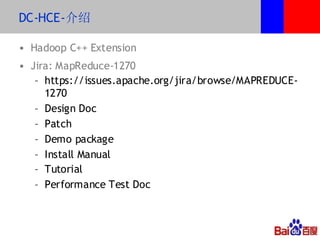
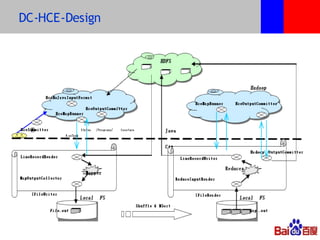
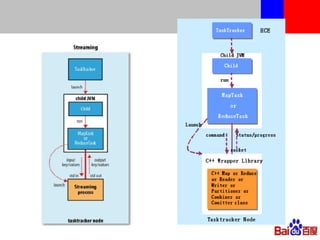
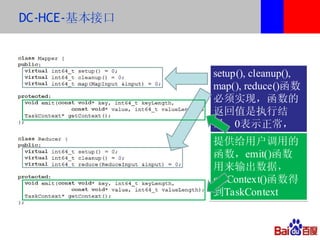
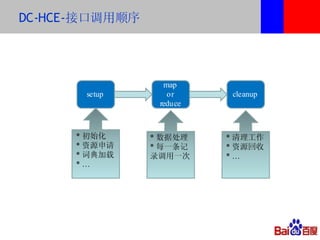
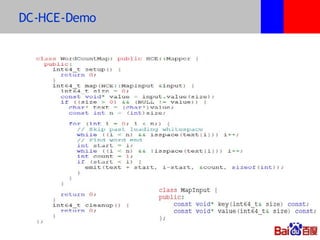
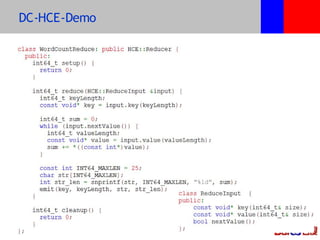
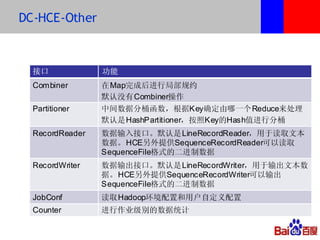
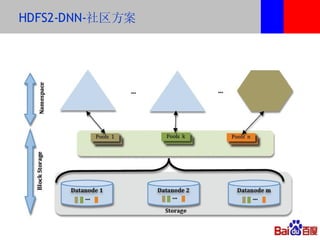
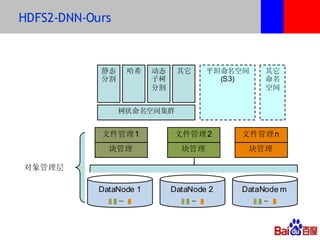
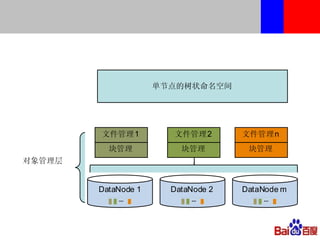
本文介绍了百度的分布式系统,包括高性能计算(HPC)、MapReduce计算和分布式存储。文中详细讨论了计算平台、调度与执行层的结构,以及如何通过Hadoop扩展C++接口来提升复杂任务的处理效率。此外,还有关于分布式存储系统HDFS2的设计与管理策略的讨论,强调了可扩展性和降低请求负载的重要性。