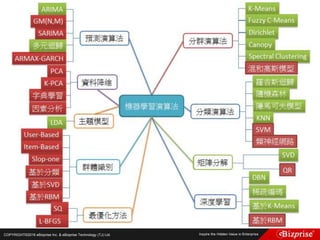
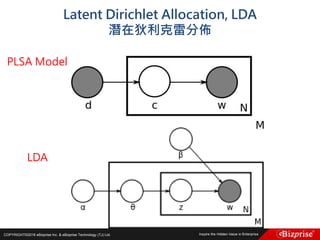
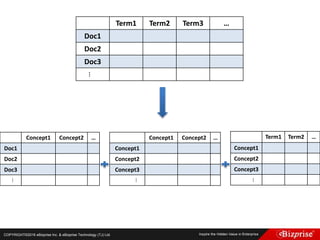
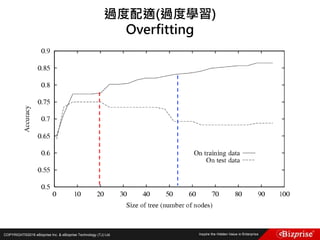
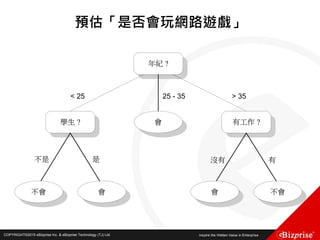
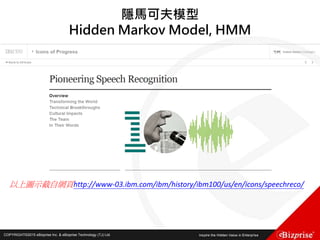
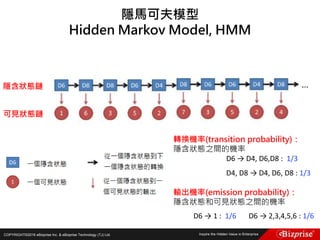
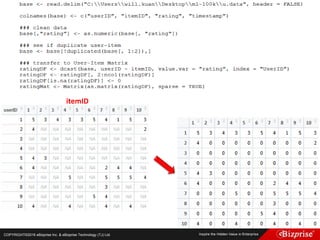
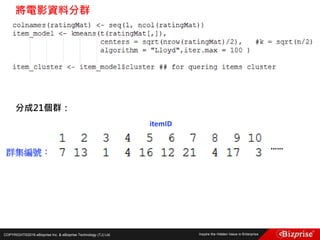
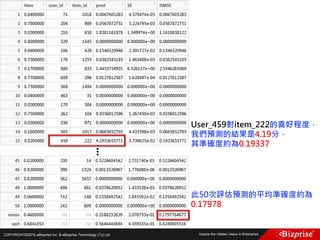
本文讨论了机器学习的概念和算法,包括定性和定量预测、监督学习、非监督学习、半监督学习以及强化学习等类型。重点介绍了群集分析的步骤及K均值算法的优缺点,此外还提到模糊C均值分群法的应用。旨在帮助读者理解机器学习在数据分析中的应用及效率提升。

















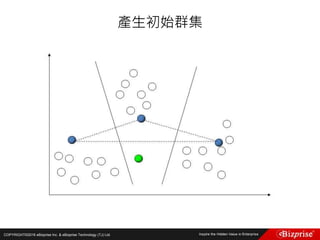
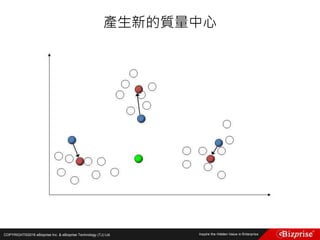
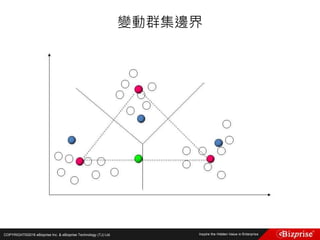
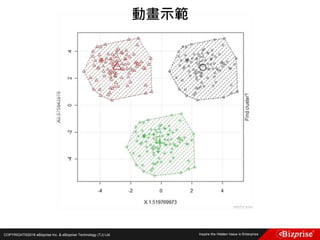






![COPYRIGHT©2016 eBizprise Inc. & eBizprise Technology (TJ) Ltd.
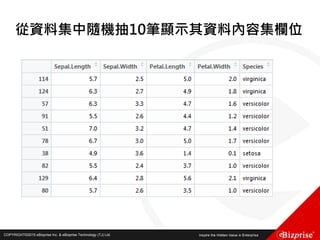
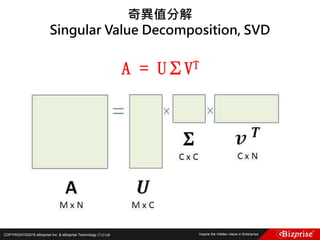
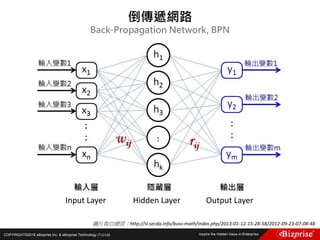
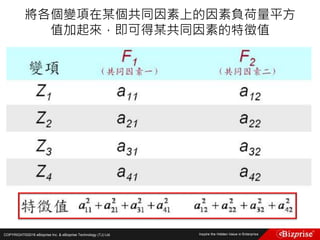
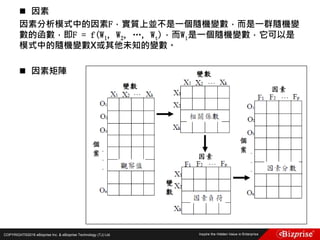
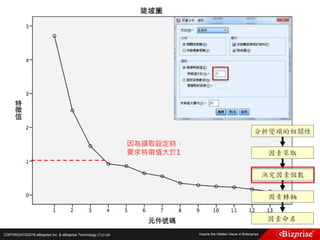
Fuzzy c-means clustering with 3 clusters
Cluster centers:
[,1] [,2] [,3]
1 5.003653 3.412805 1.484776
2 5.874036 2.760273 4.382523
3 6.793625 3.054511 5.644350
Closest hard clustering:
[1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[43] 1 1 1 1 1 1 1 1 3 2 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 3 3 2 2 2 2 2 2
[85] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 3 2 3 3 3 3 2 3 3 3 3 3 3 2 2 3 3 3 3 2 3 2 3 2 3 3
[127] 2 2 3 3 3 3 3 3 3 3 3 3 2 3 3 3 2 3 3 3 2 3 3 2
分群結果](https://image.slidesharecdn.com/random-160703173124/85/Machine-Learning-33-320.jpg)















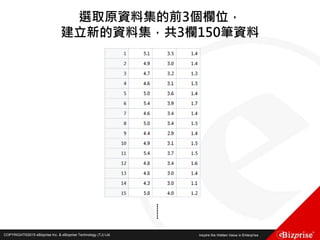
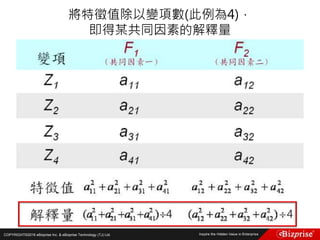
![COPYRIGHT©2016 eBizprise Inc. & eBizprise Technology (TJ) Ltd.
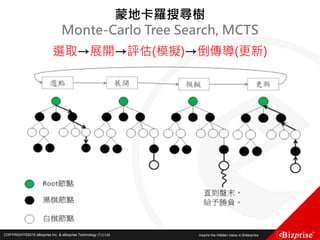
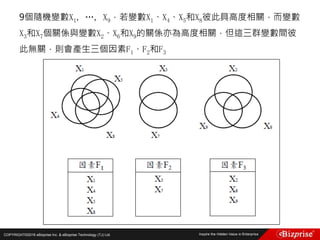
第六個點P6(1, 1)距離Canopy1的距離為14>T1,距離Canopy2的距
離為3<T2,所以第六個點屬於Canopy2,並從list中移除此點
第七個點P7(0, 0)距離Canopy1的距離為16>T1,距離Canopy2的距
離為5=T2,所以將第七個點記為屬於Canopy2的弱標籤,但不將此
點從list中移除
第八個點P8(3, 3)距離Canopy1的距離10>T1,距離Canopy2的距離
為1<T2,所以第八個點屬於Canopy2,並從list中移除此點
此時所有Canopy的狀態為:
Canopy1 (8, 8) : [(8, 8), (7, 7), (6, 6), (7, 7)]
Canopy2 (2, 3) : [(2, 3), (1, 1), (0, 0), (3, 3)]
List中剩下的元素為(0, 0),將此點作為新的Canopy,Canopy3(0, 0)](https://image.slidesharecdn.com/random-160703173124/85/Machine-Learning-53-320.jpg)
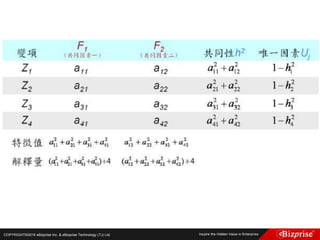
![COPYRIGHT©2016 eBizprise Inc. & eBizprise Technology (TJ) Ltd.
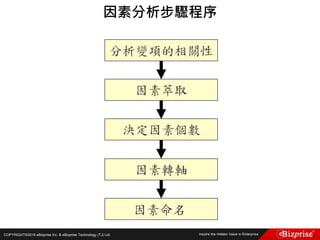
Canopy的最後狀態為:
Canopy1 (8, 8) : [(8, 8), (7, 7), (6, 6), (7, 7)]
Canopy2 (2, 3) : [(2, 3), (1, 1), (0, 0), (3, 3)]
Canopy3 (0, 0) : [(0, 0)]
最終的Canopy群集中心為(7, 7),(1.5, 1.75),(0, 0)
接著,就可以用此三點作為K-Means的初始群集中心了。](https://image.slidesharecdn.com/random-160703173124/85/Machine-Learning-54-320.jpg)











![COPYRIGHT©2016 eBizprise Inc. & eBizprise Technology (TJ) Ltd.COPYRIGHT©2015 eBizprise Inc. & eBizprise Technology (TJ) Ltd.
羅吉斯迴歸→二元羅吉斯迴歸 (簡稱羅吉斯迴歸)
多項式羅吉斯迴歸/多元羅吉斯迴歸 (沒人簡稱它)
Example:
1. 用父母的身高(X1 , X2 ) 小孩的身高Y (幾公分)
2. 用父母的身高(X1 , X2 ) 小孩的身高是否170公分以上
3. 用父母的身高(X1 , X2 ) 小孩的身高在哪個區間
150↓、(150, 160]、(160, 170]、170↑
Answer:
1. 複迴歸
2. 羅吉斯迴歸
3. 多項式羅吉斯迴歸
羅吉斯迴歸
Logistic Regression/ Logit Regression
預測/解釋](https://image.slidesharecdn.com/random-160703173124/85/Machine-Learning-73-320.jpg)




























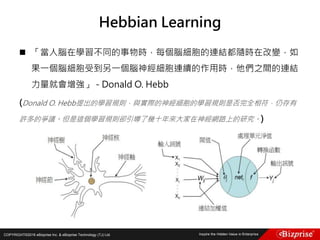



























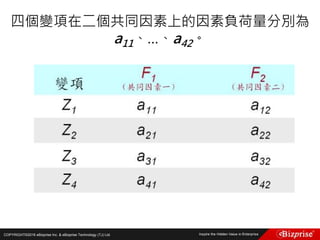





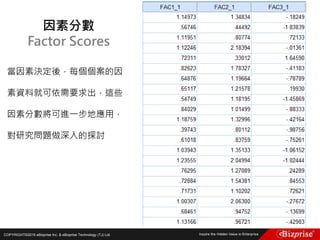








![COPYRIGHT©2016 eBizprise Inc. & eBizprise Technology (TJ) Ltd.
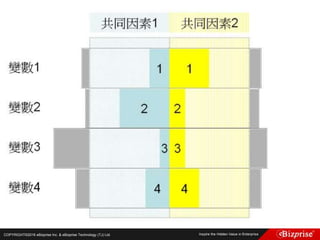
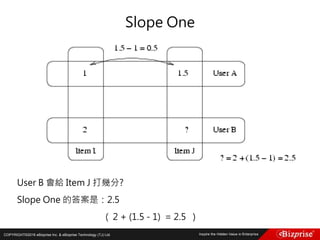
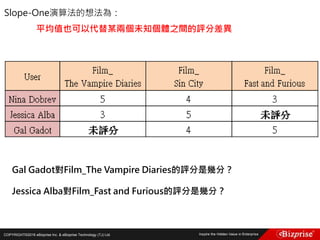
Gal Gadot對Film_The Vampire Diaries的評分是幾分? 3.5
[(5 – 4) + (3 - 5)]/2 = -0.5
(人們對The Vampire Diaries的評分一般比Sin City的評分高-0.5分)
4 + (-0.5) = 3.5
Jessica Alba對Film_Fast and Furious的評分是幾分?4.5
[(4 - 3) + (4 - 5)]/2 = 0.5
(人們對Sin City的評分一般比Fast and Furious的評分高0.5分)
5 – 0.5 = 4.5](https://image.slidesharecdn.com/random-160703173124/85/Machine-Learning-175-320.jpg)






























![[DL輪読会]1次近似系MAMLとその理論的背景](https://cdn.slidesharecdn.com/ss_thumbnails/20190412kondo-190412002418-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [TS3] 機械学習のアノテーションにおける データ収集 〜 精度向上のための仕組み・倫理や社会性バイアス 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts3-01-210607043121-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC 2016] 系列活動:許懷中 / R 語言資料探勘實務](https://cdn.slidesharecdn.com/ss_thumbnails/rdatamining-161030010840-thumbnail.jpg?width=640&height=640&fit=bounds)

















