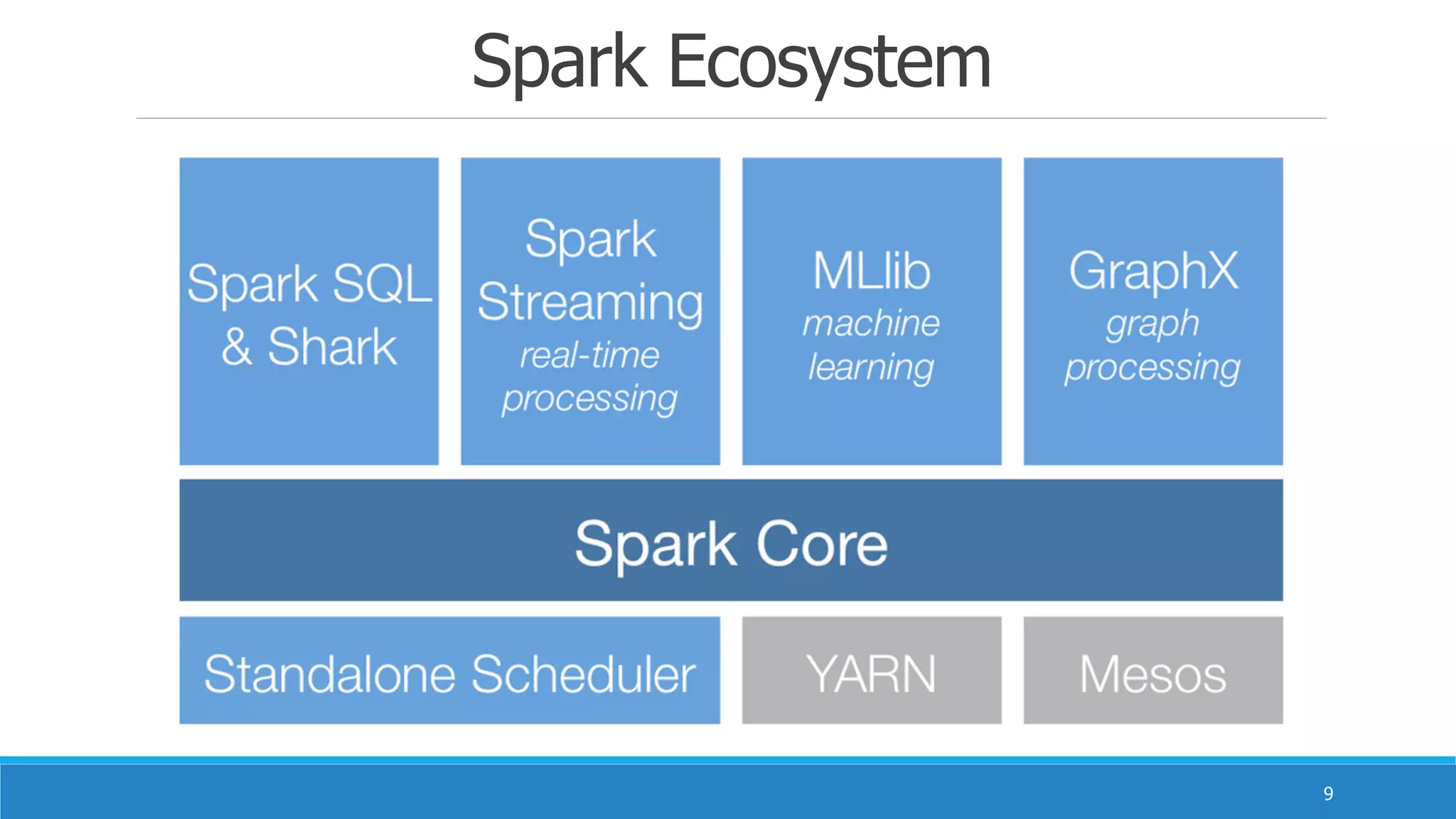
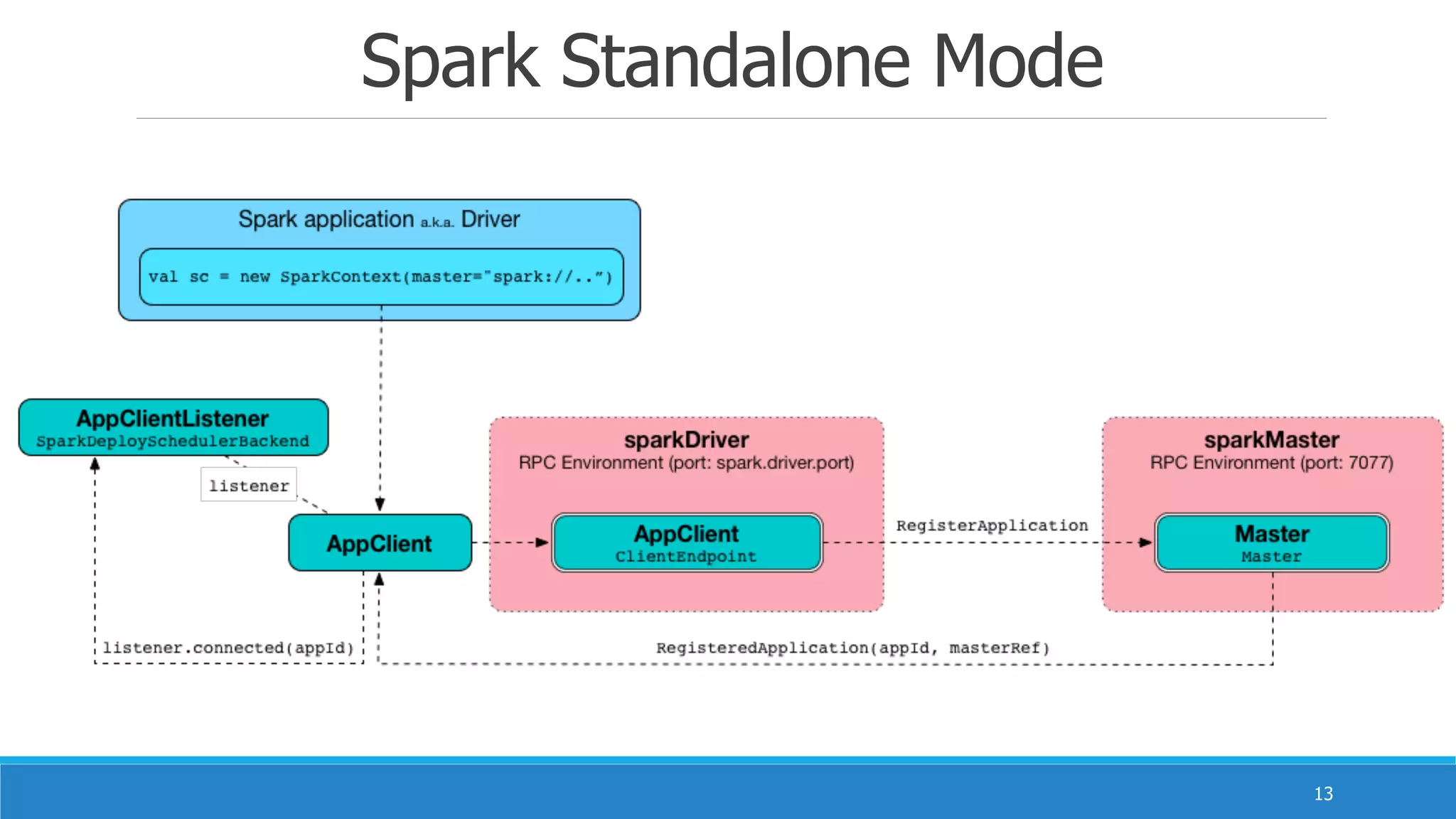
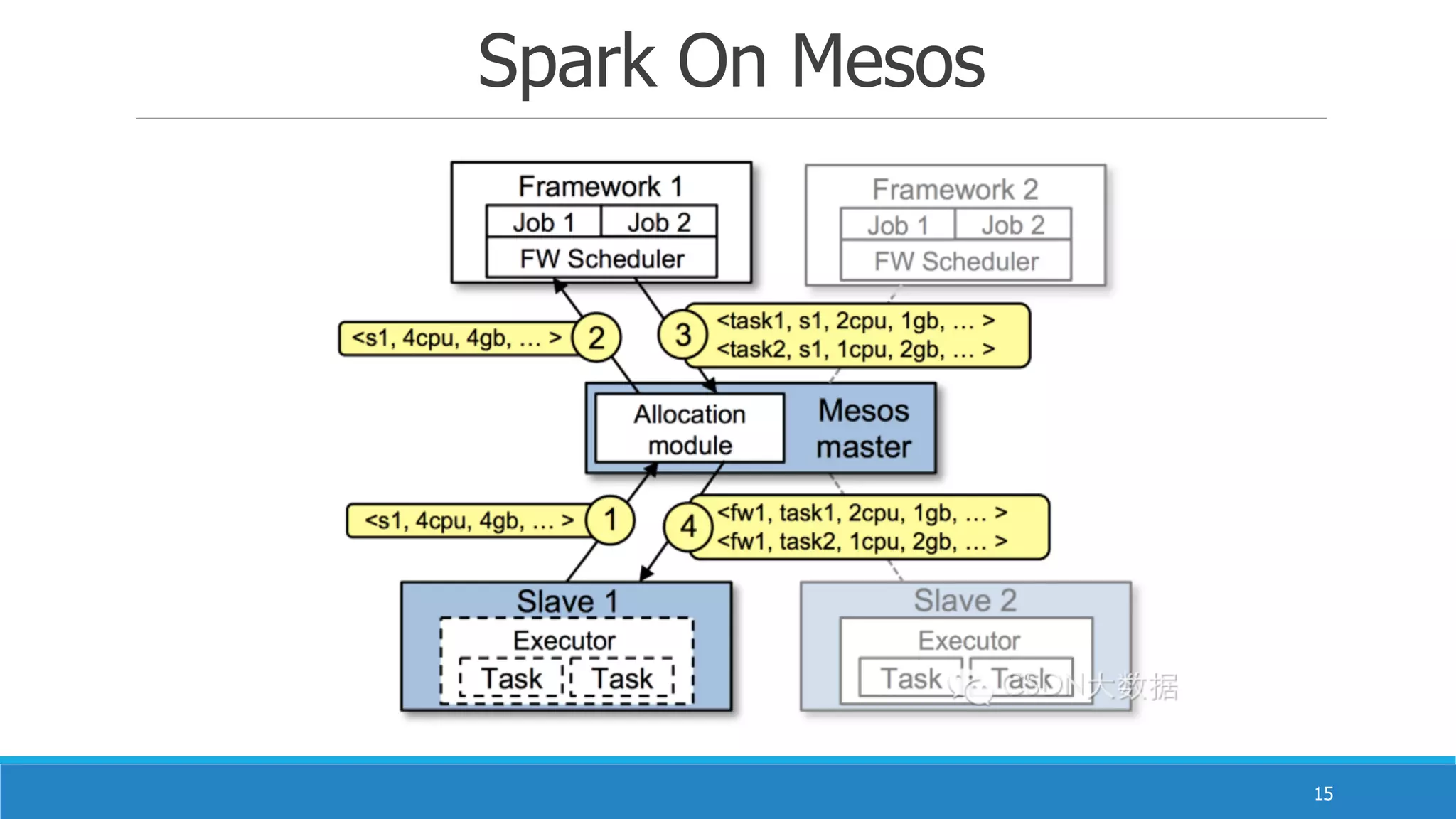
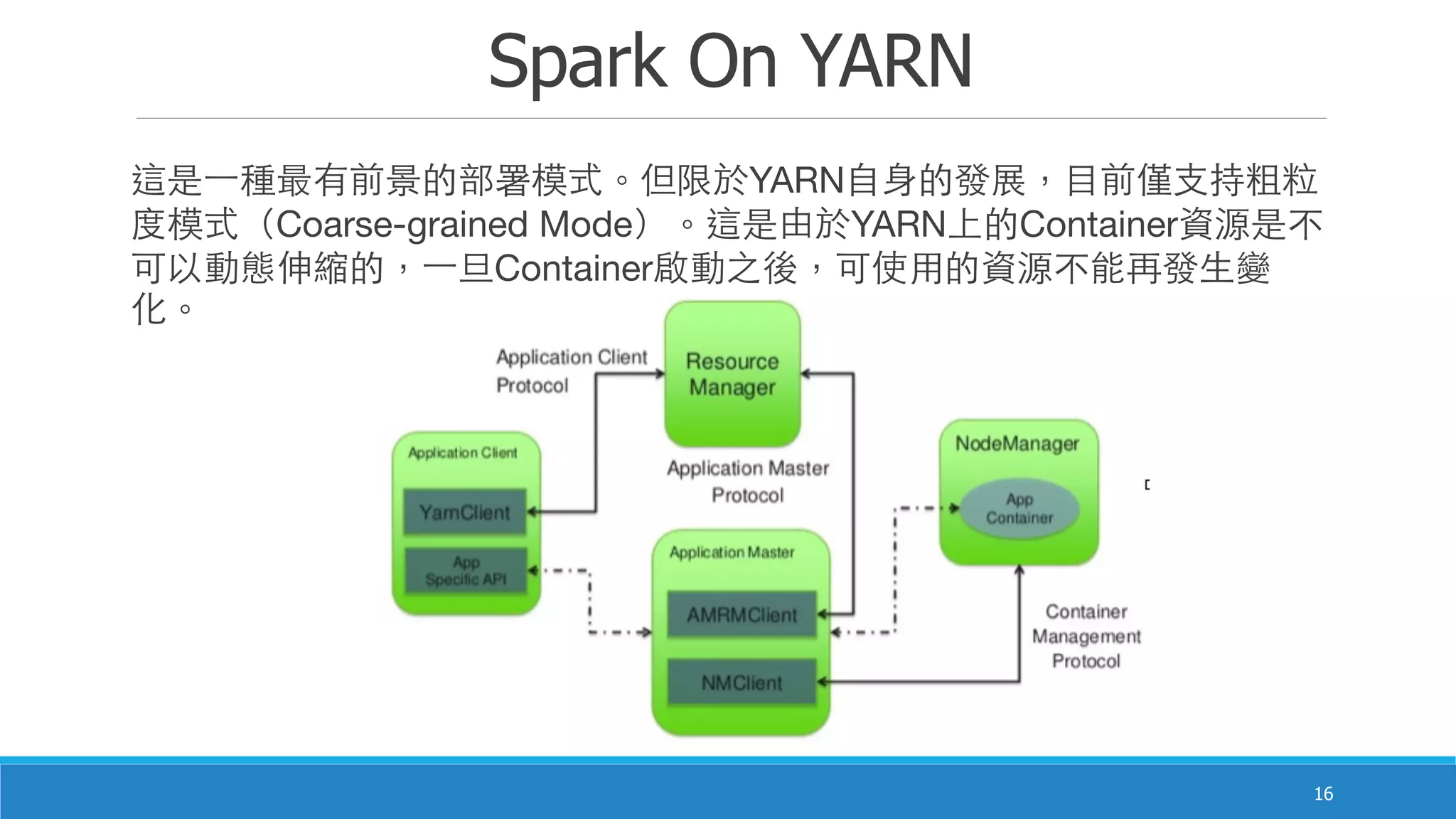
Apache Spark 是一款由加州大学伯克利分校开发的开源集群计算框架,提供比 Hadoop 更高效的内存计算能力。它支持混合批处理、交互式查询和流处理,通过弹性分布式数据集(RDD)实现高效的运算和容错机制,同时也解决了多个专有系统的重重复问题。Spark 的生态系统包含多个组件,如 Spark SQL、Spark Streaming 和 MLlib,旨在提供强大的数据处理和分析功能。

















![執⾏行指令
22
$ spark-submit --class <package> --master local[2] <jar path>
<input path> <output path>](https://image.slidesharecdn.com/spark-160513022708/75/Spark-22-2048.jpg)














![groupBy 練習
37
找出測試資料中⼤大於500的資料,若無法辨識分
到”None”,並存⾄至/spark/homework/groupBy。結果如
下:
(None,[a, b, c, d, e, f])
(⼩小於 500,[123, 456, 123, 124, 123, 123, 123, 123,
456, 113, 143, 123, 446, 14, 113, 123, 446, 14, 323])
(⼤大於 500,[789, 11344, 2142, 1234, 1234, 4123, 5435,
1231, 5345, 789, 2142, 789, 2142, 789, 2142, 1113])
….](https://image.slidesharecdn.com/spark-160513022708/75/Spark-37-2048.jpg)






































![[Effective Kotlin 讀書會] 第八章 Efficient collection processing 導讀](https://cdn.slidesharecdn.com/ss_thumbnails/effective-kotlin-chapter8-221208155318-f914a841-thumbnail.jpg?width=640&height=640&fit=bounds)















