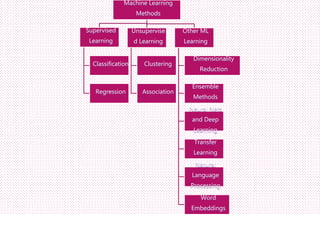
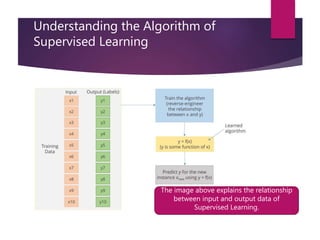
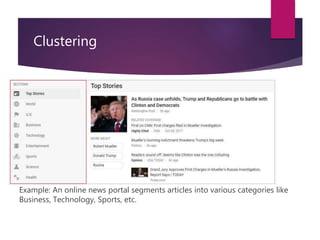
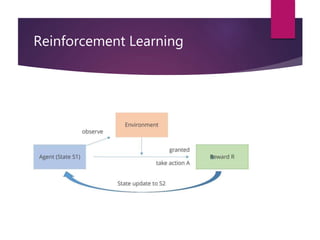
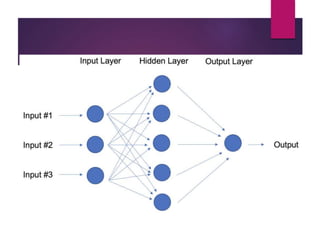
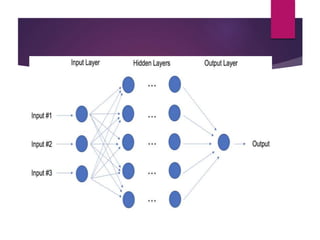
The document outlines various machine learning methodologies including supervised, unsupervised, semi-supervised, and reinforcement learning, detailing their definitions, examples, and classifications. Supervised learning is emphasized, explaining its process, types (classification and regression), and algorithms used, while unsupervised learning focuses on clustering and anomaly detection. Additional machine learning concepts such as dimensionality reduction, ensemble methods, neural networks, deep learning, transfer learning, and natural language processing are also described.













































































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)













