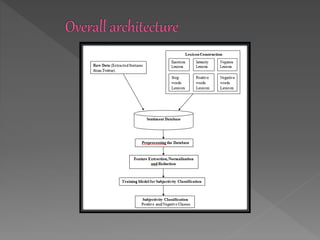
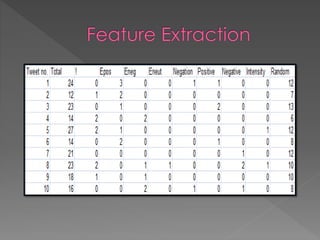
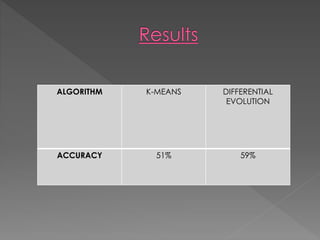
The document describes a research project on sentiment analysis of tweets. It involves collecting twitter data, preprocessing the data by removing stopwords and replacing emoticons/sentiment words with tags. Features are then extracted and normalized, followed by feature reduction. The data is clustered into positive and negative classes using K-means clustering and Differential Evolution algorithm, and their accuracies are compared, with Differential Evolution found to perform better. Future work proposed includes applying additional clustering techniques and comparing with supervised learning methods.








![ To obtain training material, use
emoticons as indicators of a mood within
a message.
Split the tweets into 2 sets:
positive - ;) :} :] ...
negative - :{ :’( ...
We get a positive word list and a
negative word list.
If a word present more frequently in
positive set, then it is positive and vice
versa.](https://image.slidesharecdn.com/major-presentation-150604033100-lva1-app6892/85/Major-presentation-9-320.jpg)














![ The aspect-based sentiment classifier makes use of a POS
tagger, a sentiment lexicon and a few gazetteer lists to produce
results of the form [aspect, sentiment words, polarity]. This
process consists of three main steps:
1. Aspect-sentiment extraction: Given a tweet, this step
determines a list of possible aspect candidates along with their
associated sentiments and polarity.
2. Aspect ranking and selection: A tweet can express many
different opinions. Only important aspects should be selected.
For example, when classifying tweets on a telecommunication
company, some of the aspects of interest include customer
service, 3G connectivity, speed, etc. In this step the aspect
candidates are then ranked and the set of most significant
aspects are selected as the expected aspects.
3. Aspect classification: Using the set of expected aspects and
results from the aspect-sentiment extraction step, we obtain the
final list of aspects along with their polarity for each tweet.](https://image.slidesharecdn.com/major-presentation-150604033100-lva1-app6892/85/Major-presentation-24-320.jpg)








































































![[IJET V2I4P9] Authors: Praveen Jayasankar , Prashanth Jayaraman ,Rachel Hannah](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v2i4p9-160810102259-thumbnail.jpg?width=640&height=640&fit=bounds)


























