Download as PDF, PPTX
















![//load Labeled Faces in the Wild dataset
from sklearn.datasets import fetch_lfw_people
people = fetch_lfw_people(min_faces_per_person=20,resize=0.7)
//display 10 faces
image_shape = people.images[0].shape
import matplotlib.pyplot as plt
fix,axes = plt.subplots(2,5, figsize=(15,8),subplot_kw={‘xticks’:(),’yticks':()})
for target,image,ax in zip(people.target,people.images,axes.ravel()):
ax.imshow(image)
ax.set_title(people.target_names[target])
plt.show()
//use plt.ion() if plot isn't displayed or create .matplotlibrc in ./.matplotlib/ with text
‘backend: TkAgg'](https://image.slidesharecdn.com/machinelearning-intro-170214120340/75/Machine-Learning-Introduction-23-2048.jpg)




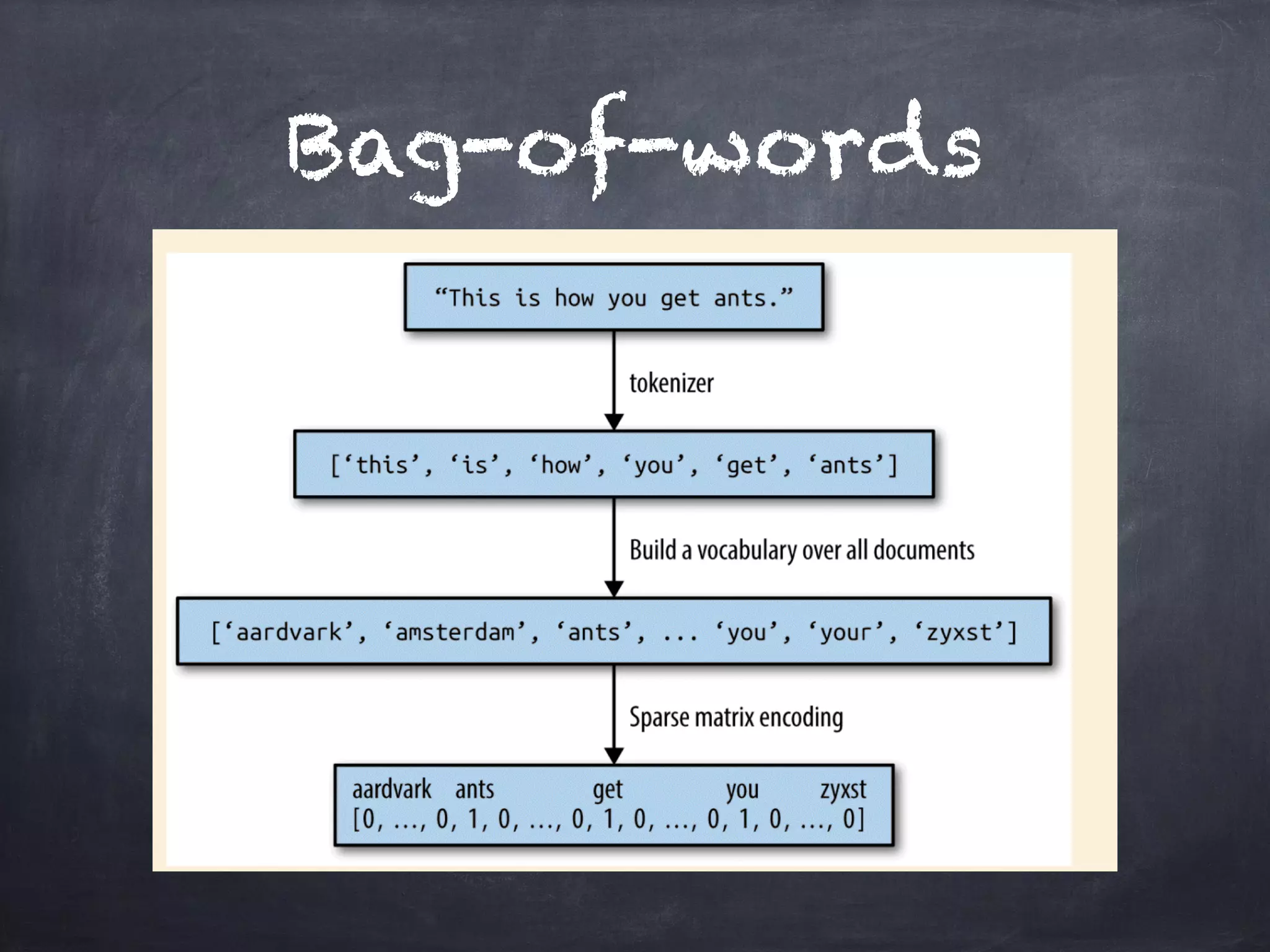
![Bag-of-words
//vectorize
sentence = ["Hello world"]
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
vect.fit(sentence)
//print vocabulary
vect.vocabulary_
//apply bag-of-words to sentence
bag_of_words = vect.transform(sentence)
bag_of_words.toarray()](https://image.slidesharecdn.com/machinelearning-intro-170214120340/75/Machine-Learning-Introduction-29-2048.jpg)




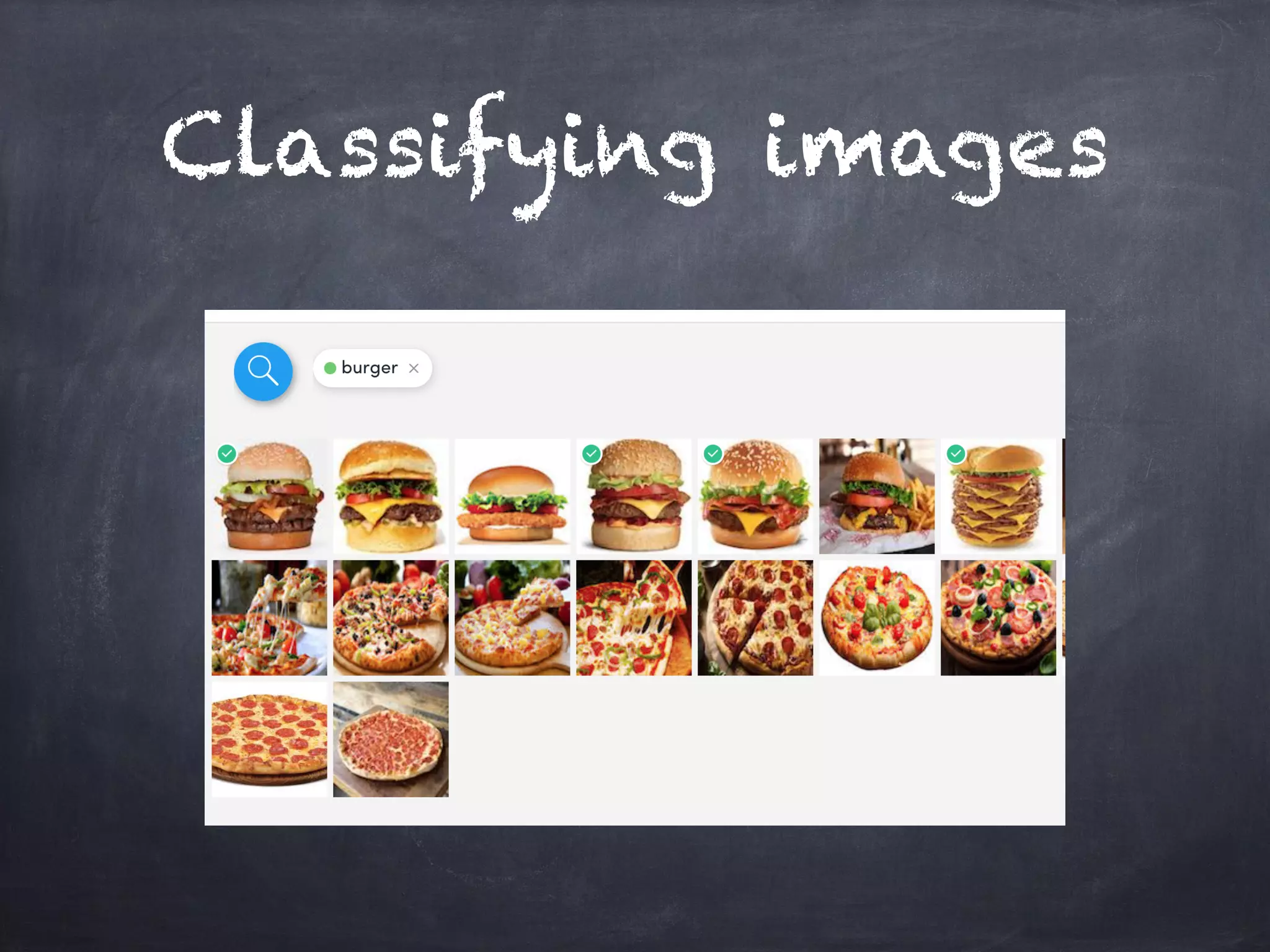
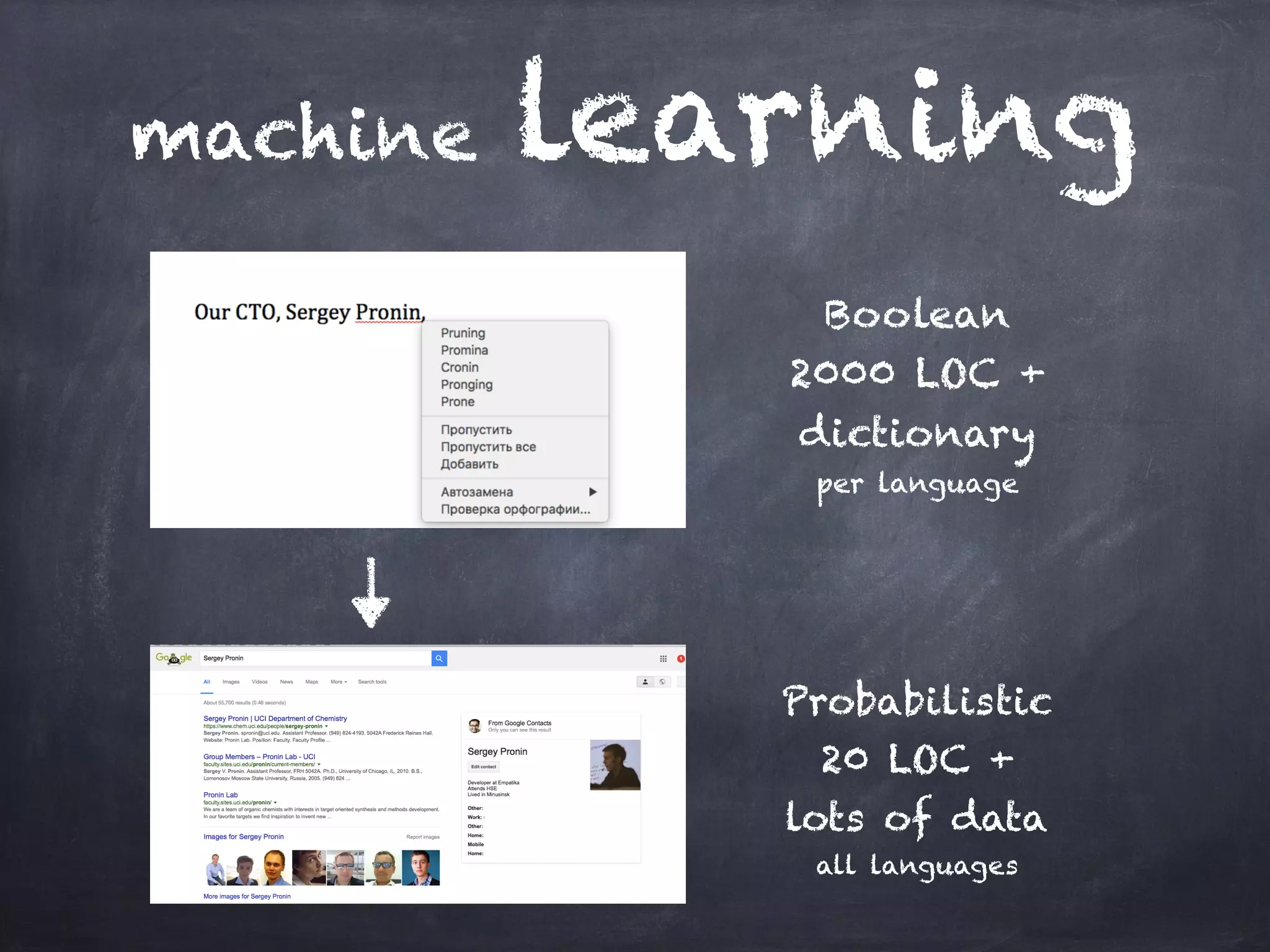
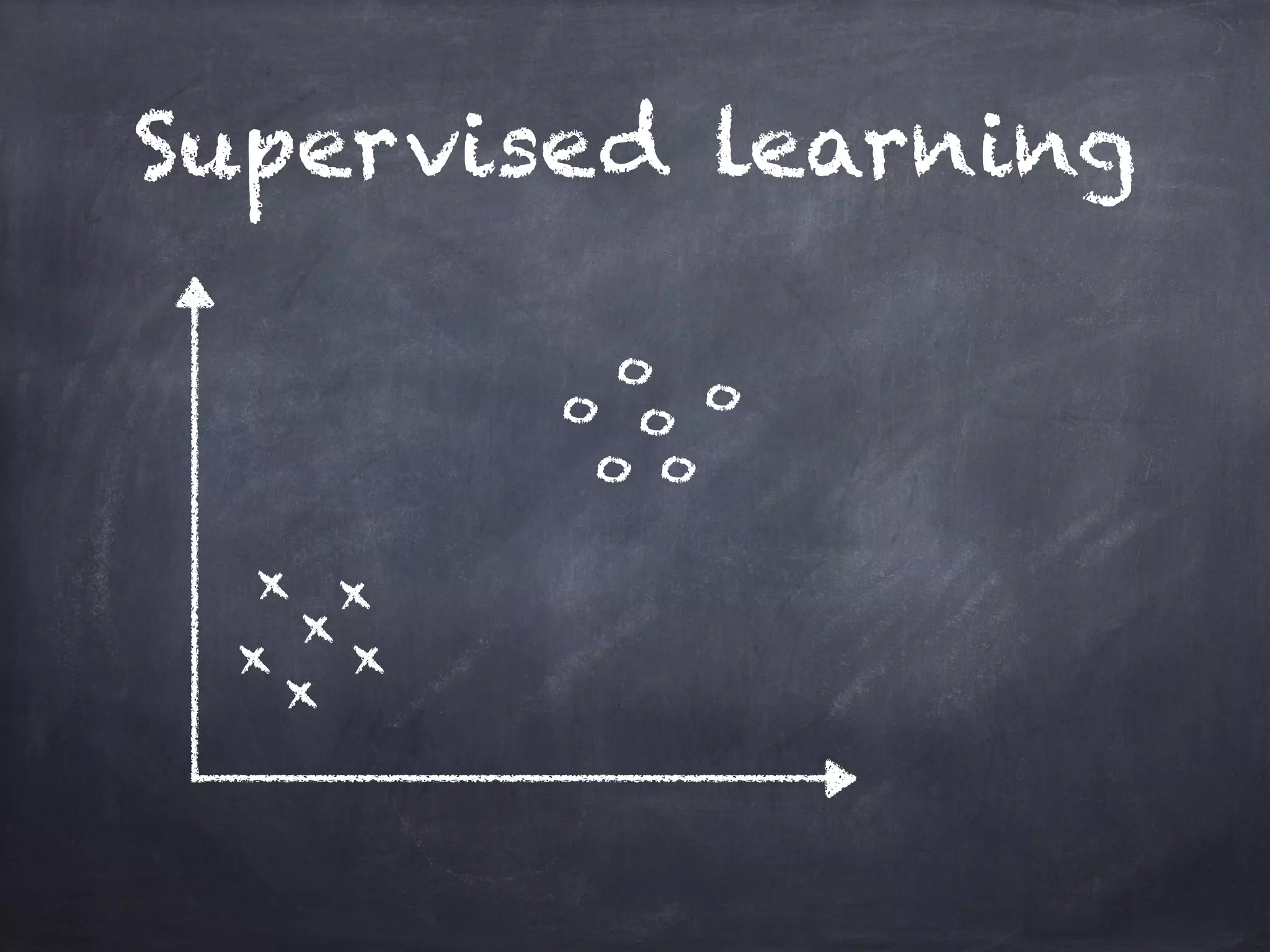
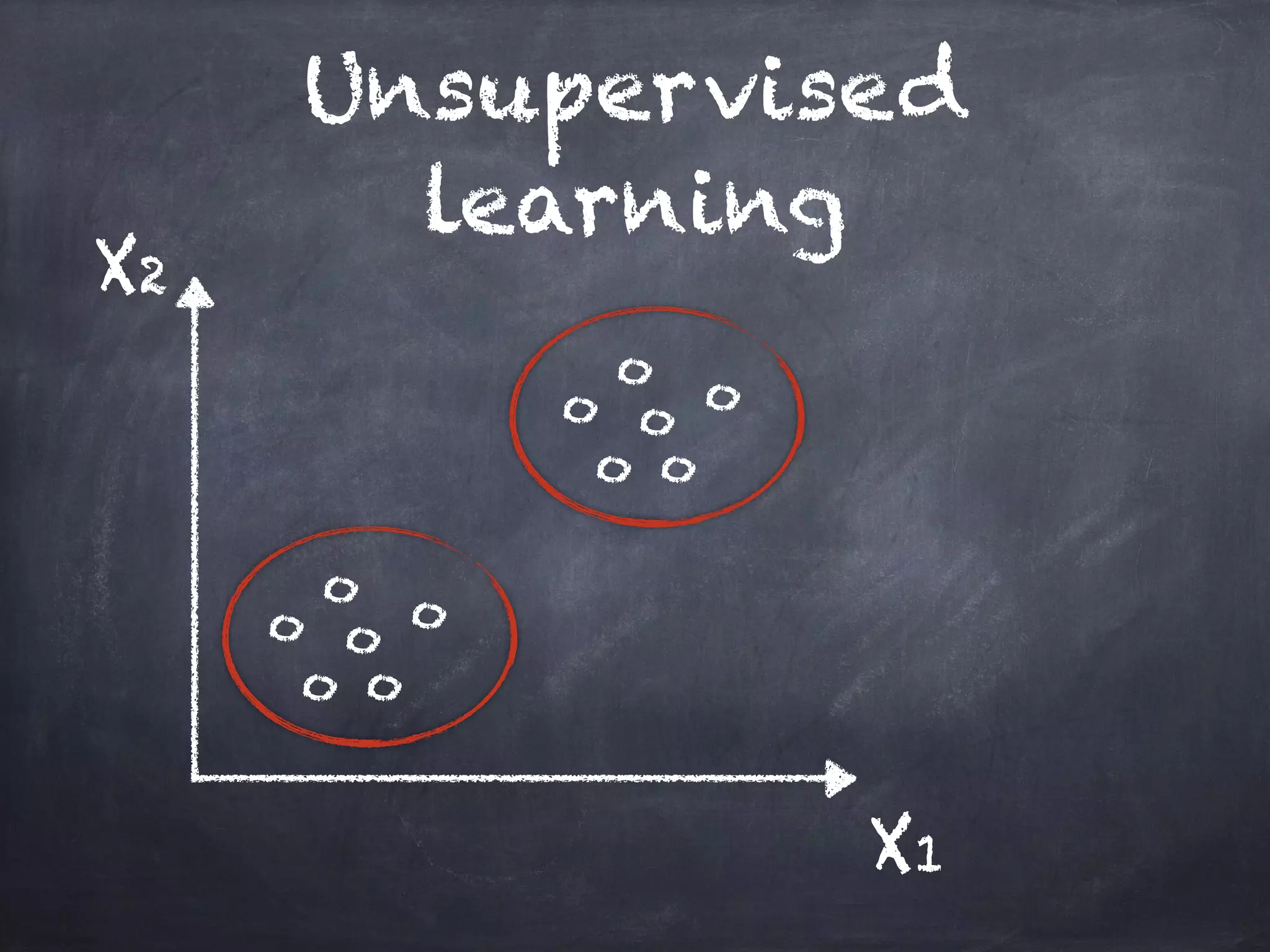
This document introduces machine learning concepts including supervised and unsupervised learning. It discusses preparing data for machine learning by techniques like one-hot encoding, scaling, principal component analysis (PCA), and bag-of-words representations. Code examples are provided to classify cancer data using k-nearest neighbors, cluster data with k-means, reduce dimensions with PCA, and vectorize text with bag-of-words. Finally, potential machine learning exercises are outlined like predicting user purchases, finding user clusters, and regression problems.

![[AI07] Revolutionizing Image Processing with Cognitive Toolkit](https://cdn.slidesharecdn.com/ss_thumbnails/ai07-170602095346-thumbnail.jpg?width=640&height=640&fit=bounds)




























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)










