Downloaded 12 times



![PATHso your compiler knows where to find the libraries
SET UP
THE
export PATH=/usr/local/cuda-5.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-5.0/lib:/usr/local/cuda-5.0/lib64:$LD_LIBRARY_PATH
[YourAccount@John ~]$ ls –a
[YourAccount@John ~]$ vi .bash_profile
1.Open the bash profile
2.Add these lines to the file](https://image.slidesharecdn.com/2013-200928-20programming-20by-20cuda-130927222419-phpapp02/85/2013-0928-programming-by-cuda-4-320.jpg)








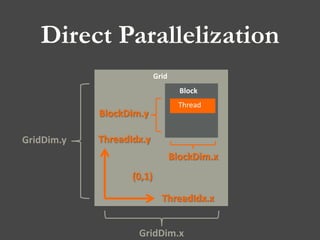



![Direct Parallelization
Declaration of Device Array
Allocation of Device Array
Declaration of Host Array
Copy Array : Host to Device
Copy Array : Device to Host
De-allocation of Device Array
Execution of Kernel
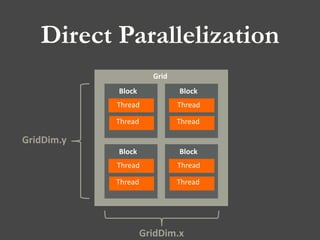
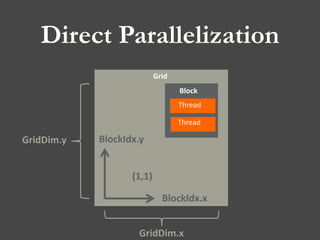
Determination of Size for Grid & Block
Assignment of CUDA Device
Allocation of Device Array
Copy Array : Host to Device
Determination of Size for Grid & Block
1.Memory assessment
2.Memory alignment
3.Data flow
Use as many threads as possible:
a[ i] m[11] … m[1n]
v[1]
…
v[ j]
…
v[n]
= *](https://image.slidesharecdn.com/2013-200928-20programming-20by-20cuda-130927222419-phpapp02/85/2013-0928-programming-by-cuda-22-320.jpg)

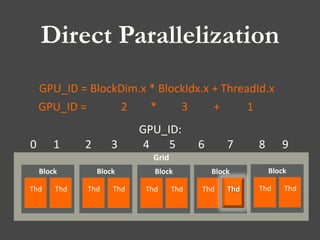
![Direct Parallelization
Declaration of Device Array
Allocation of Device Array
Declaration of Host Array
Copy Array : Host to Device
Copy Array : Device to Host
De-allocation of Device Array
Execution of Kernel
Determination of Size for Grid & Block
Assignment of CUDA Device
Allocation of Device Array
Copy Array : Host to Device
Determination of Size for Grid & Block
__global__ My_Dgemv( … ){
…
id=BlockIdx.x;
i=id;
a[i]=0;
For(j=0,j<n,j++){
a[i]=a[i]+m[ IJToIdx(i,j,n) ]*a[j];
}
}](https://image.slidesharecdn.com/2013-200928-20programming-20by-20cuda-130927222419-phpapp02/85/2013-0928-programming-by-cuda-24-320.jpg)




This document summarizes CUDA programming using CUBLAS and direct parallelization. It first introduces CUBLAS, which implements BLAS functions on GPUs using CUDA. It describes how to initialize CUBLAS, transfer data between host and device memory, execute CUBLAS functions, and clean up. It then discusses direct parallelization, where each thread is assigned a specific task. It explains how to determine grid and block sizes, allocate device memory, copy data to the device, execute kernels, and copy results back to host memory. The document provides examples of using CUBLAS and coding a direct parallelization kernel for a matrix-vector multiplication operation.




































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








