Downloaded 27 times




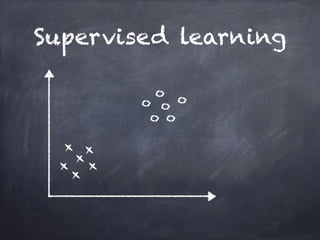
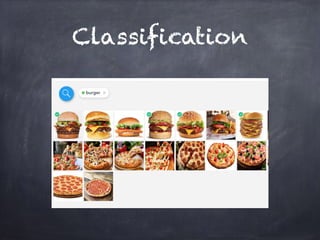

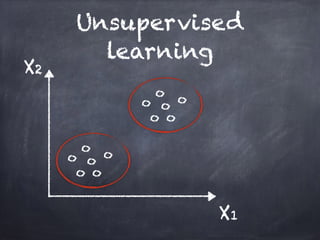






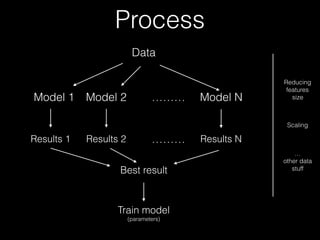





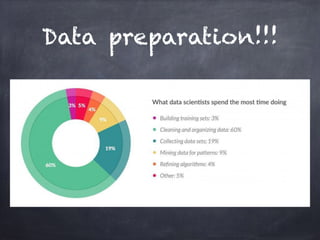












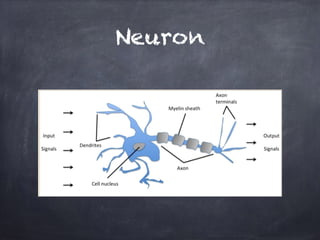
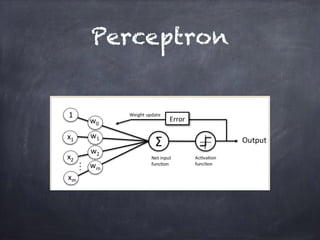
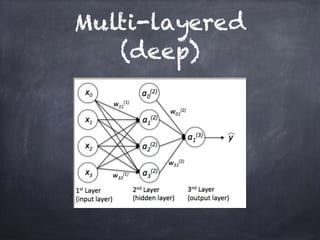

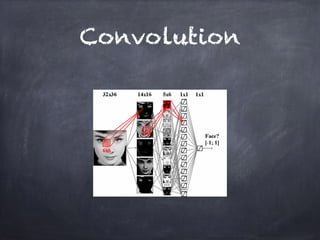
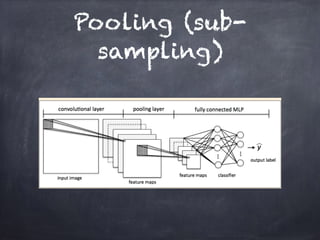
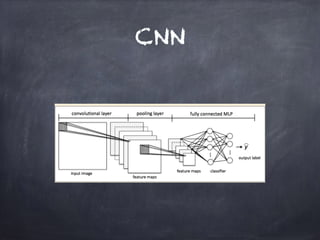







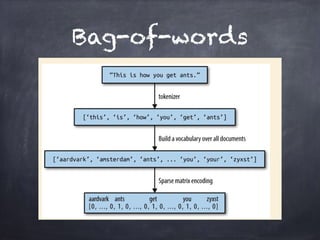



















This document provides an overview of machine learning concepts and processes. It discusses types of machine learning including supervised learning (classification and regression), unsupervised learning (clustering), and reinforcement learning. It also outlines the typical machine learning process of data collection/preparation, modeling, training models, evaluating results, and improving models. Specific examples discussed include using machine learning for email marketing conversion prediction, rhythmic gymnastics image classification, and recommendation systems.











































































