Download as PDF, PPTX































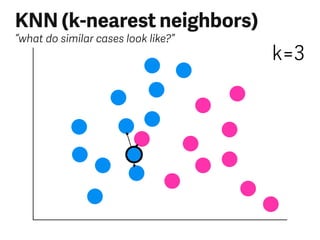










The document provides an overview of various classification algorithms in machine learning, including examples like spam filters and the sorting hat. It discusses techniques such as linear discriminants, logistic regression, support vector machines (SVMs), k-nearest neighbors (KNN), decision trees, and ensemble models, highlighting their advantages and disadvantages. Each method is described with a focus on its operational principles and use cases, emphasizing the importance of labeled data for training.














































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)



















