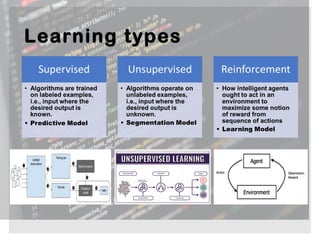
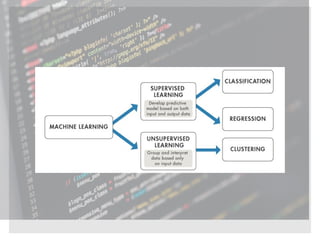
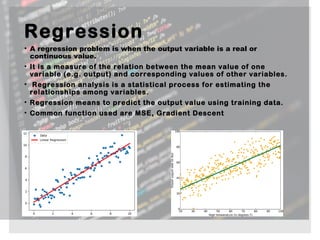
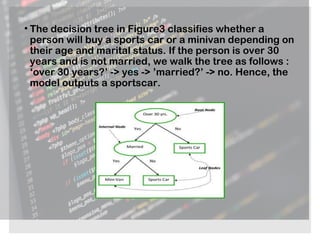
The document provides an overview of machine learning, its types (regression, classification, clustering), and various methodologies including decision trees and random forests. It highlights the differences between regression and classification, emphasizing the statistical processes involved and their practical applications in predictive modeling. Additionally, it discusses the future of machine learning as a significant competitive advantage for companies as automation continues to grow.









































































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)











