Download as PDF, PPTX



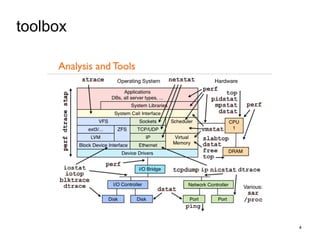
























![Программа tcpdump - это швейцарский нож, который покажет все
проблемы с сетью.
Синтаксис:
tcpdump -i <interface> [options] <expression>
expression - выражение, фильтрующее пакеты
29
Швейцарский нож - tcpdump](https://image.slidesharecdn.com/troubleshooting-141128082421-conversion-gate02/85/Troubleshooting-29-320.jpg)























Документ посвящен устранению неполадок для системных администраторов и включает важные аспекты мониторинга систем и сетей. Он подчеркивает необходимость знаний в области работы операционных систем, командных утилит и принципов работы сервисов для успешного выполнения задач. Также описываются инструменты мониторинга и процесс их использования для обнаружения и анализа проблем.























































































