Download as PDF, PPTX


![Определение
• GlusterFS = GNU + Cluster
– масштабируемая
– сетевая файловая система
– ориентированная на интенсивный
обмен данными типа:
●
облачное хранилище
●
потоковое мультимедиа,
– использующая типовое [commodity]
оборудование](https://image.slidesharecdn.com/glusterfs-export-150731122613-lva1-app6891/85/GlusterFS-2-320.jpg)

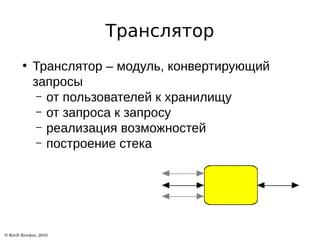
![Типы [уровни] трансляторов
● Storage
● Debug
● Cluster
● Encryption
● Protocol
● Performance
● Binding
● System
● Scheduler
● Реализация
дополнительных
возможностей
[квоты, фильтры,
блокировки]](https://image.slidesharecdn.com/glusterfs-export-150731122613-lva1-app6891/85/GlusterFS-5-320.jpg)
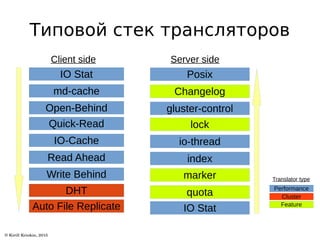

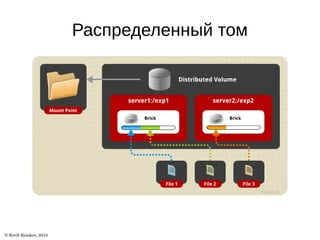
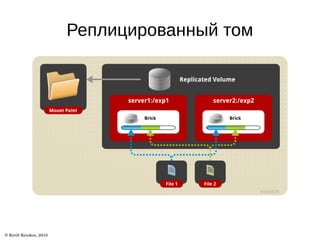
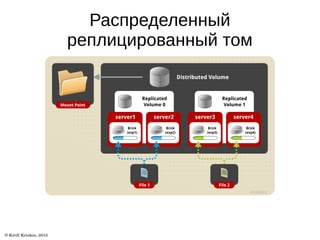
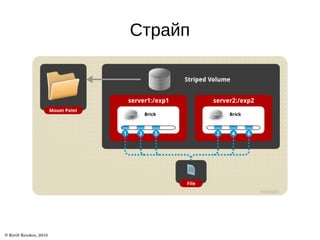
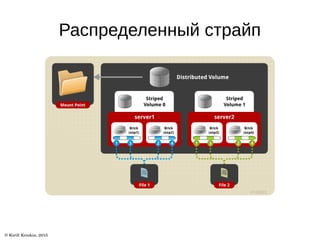



Документ описывает архитектуру и возможности файловой системы GlusterFS, которая является масштабируемой сетевой файловой системой для облачного хранения и мультимедиа. В нем представлены ключевые термины, типы томов и уровни трансляторов, а также описаны дополнительные возможности, такие как репликация и гео-репликация. Также указаны ссылки на ресурсы для получения дополнительной информации.

![Обзор архитектуры [файловой] системы Ceph](https://cdn.slidesharecdn.com/ss_thumbnails/ceph-150618110935-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[MDBCI] Mariadb continuous integration tool](https://cdn.slidesharecdn.com/ss_thumbnails/cee-secr-2015-mariadb-151028083632-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
































