Downloaded 26 times


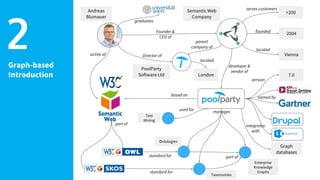




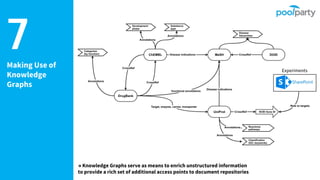



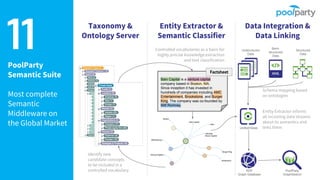

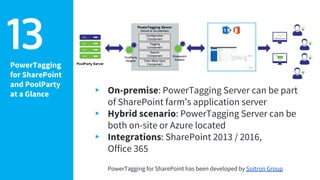
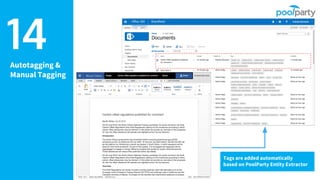
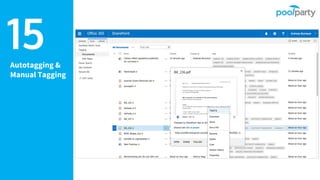
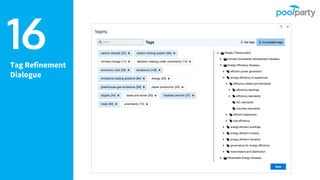
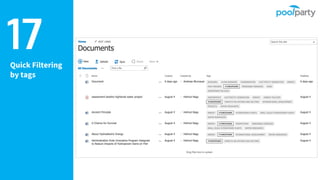
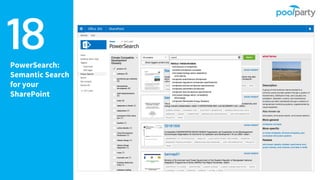


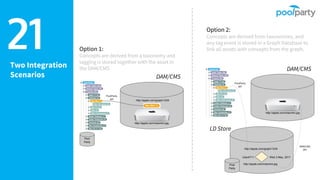

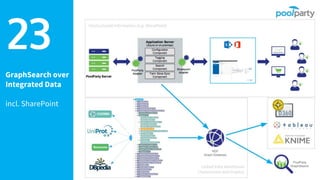
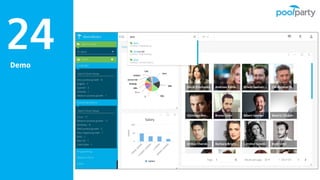
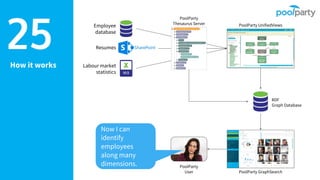


Andreas Blumauer, director of Poolparty Ltd, discusses the importance of linking SharePoint documents with structured data to enhance the usability and findability of enterprise information through knowledge graphs. He highlights various applications of knowledge graphs, including HR analytics and life sciences research, which allow for more efficient data querying and analysis. Additionally, the document outlines features like automatic tagging and semantic searching to improve data governance and enterprise knowledge management.
















































































