Downloaded 12 times





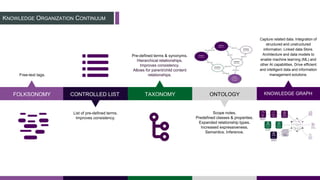

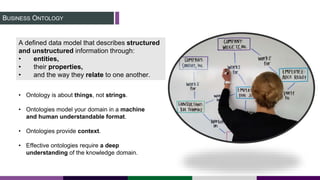
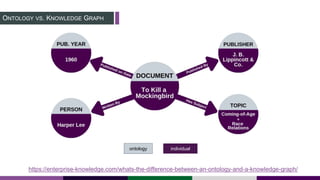
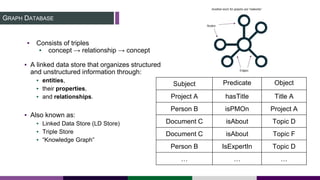
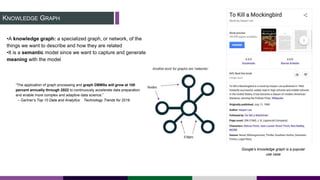
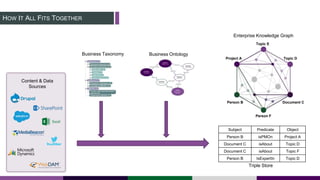

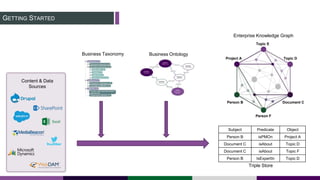
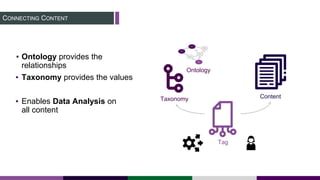
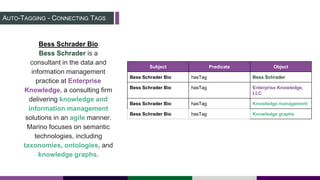
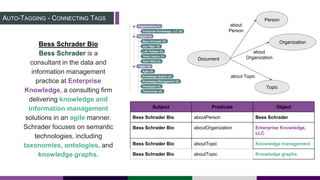



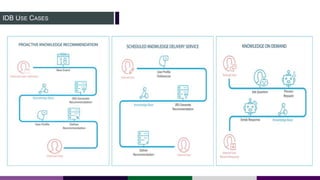
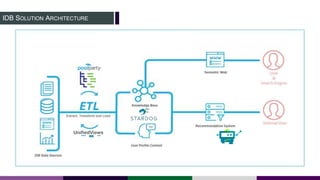
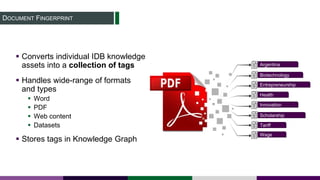


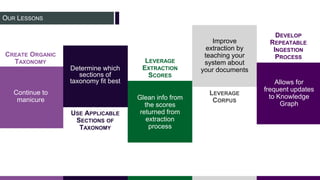




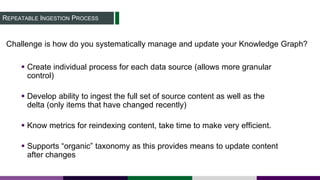


This document provides an overview of building a knowledge graph at the Inter-American Development Bank. It discusses how the Bank implemented a knowledge graph to automatically extract entities and concepts from content to create semantic data and recommendations. The solution involved developing taxonomies and ontologies, ingesting content, and using an extractor like PoolParty to tag documents and connect them to concepts in the knowledge graph. Key lessons included creating an organic taxonomy, leveraging extraction scores, using applicable sections of taxonomies, and developing a repeatable ingestion process to continually update the knowledge graph.























































































