Download as PDF, PPTX





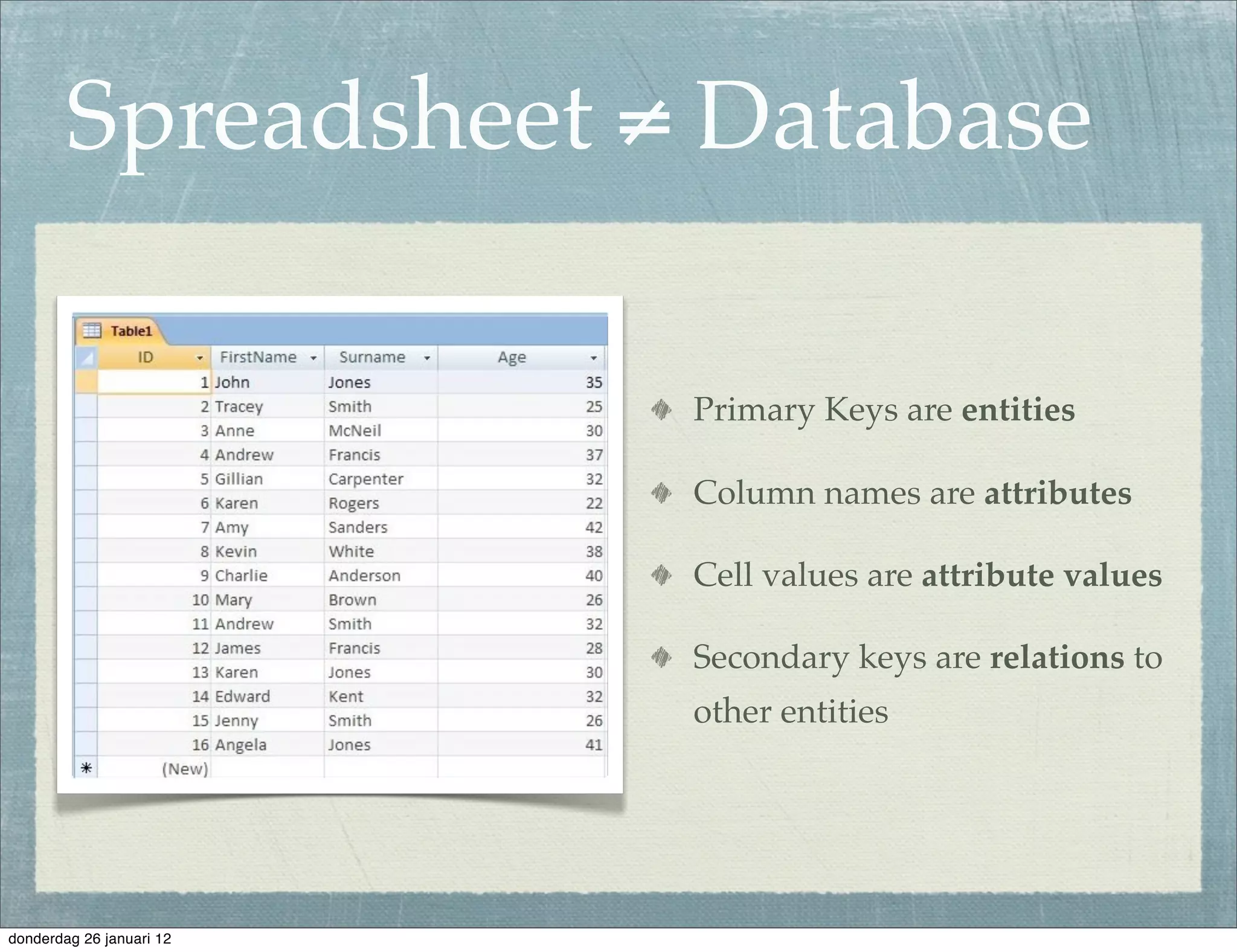
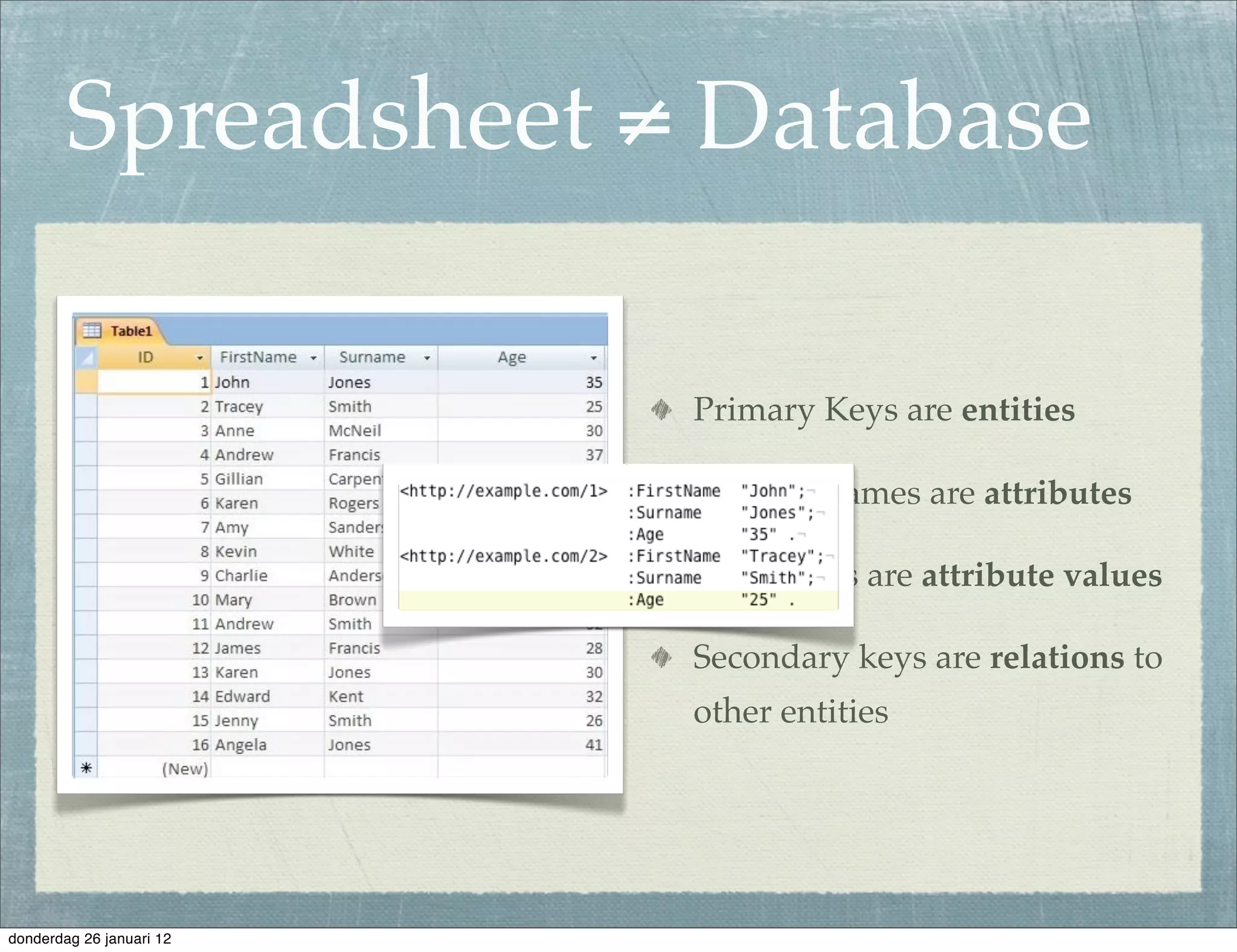
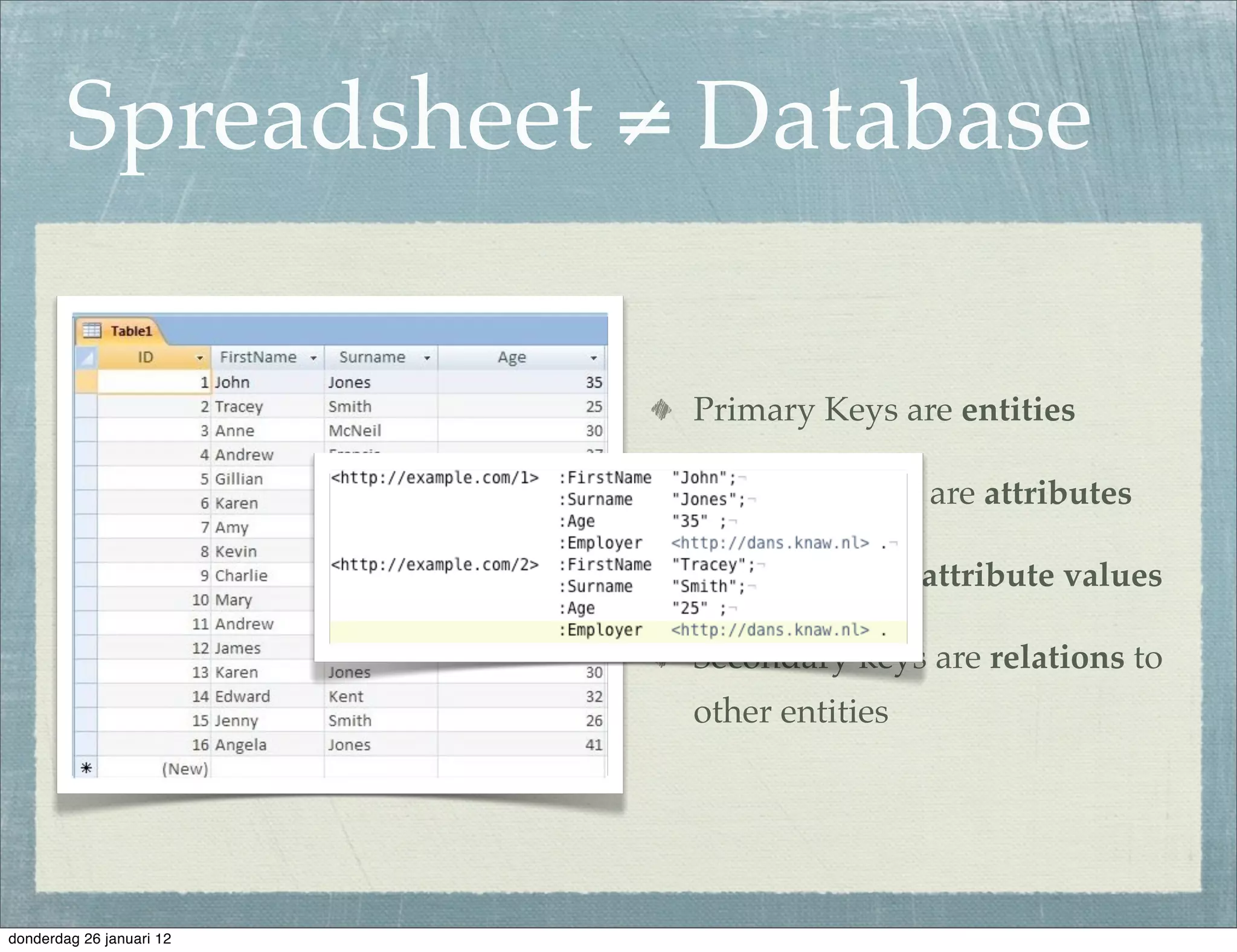




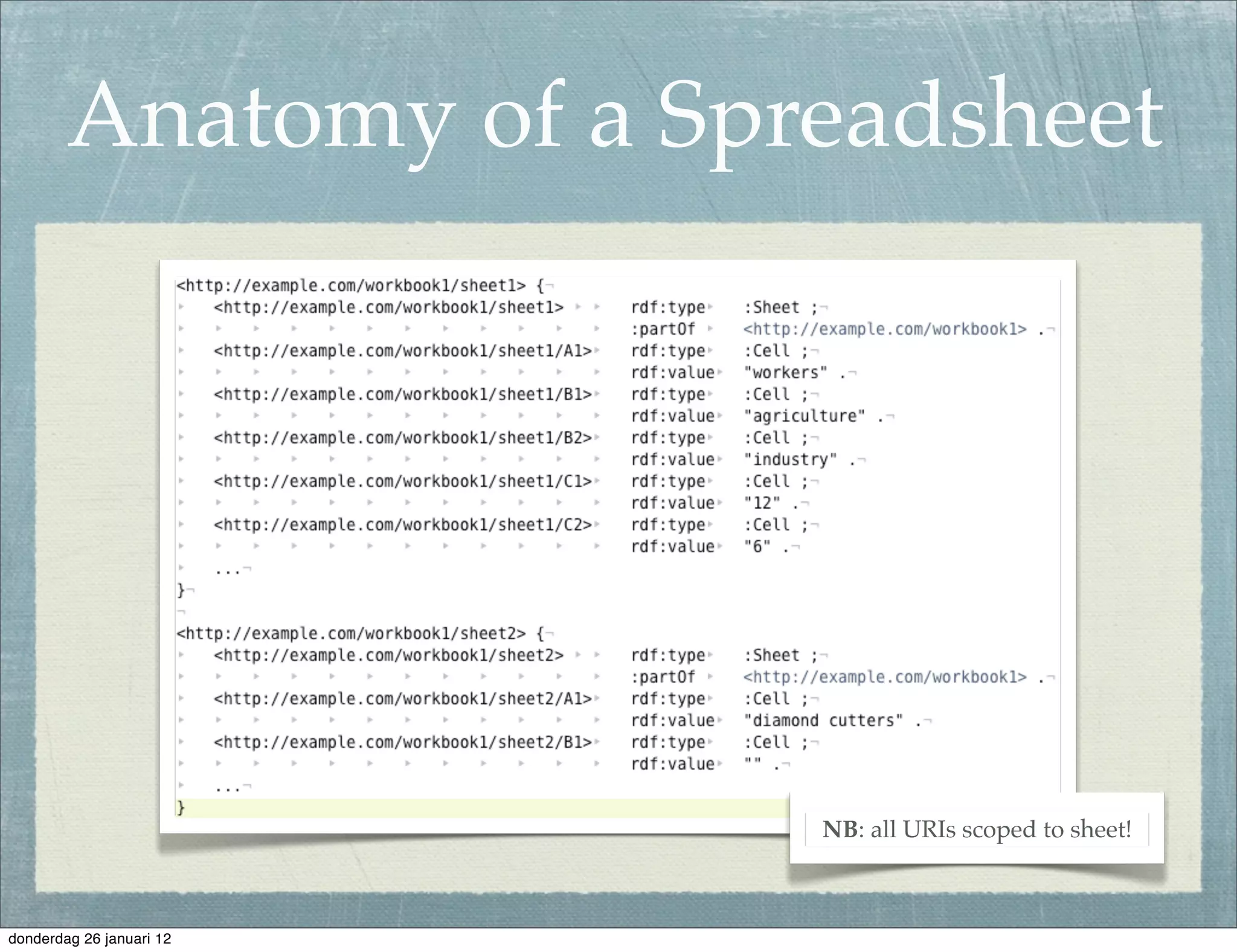







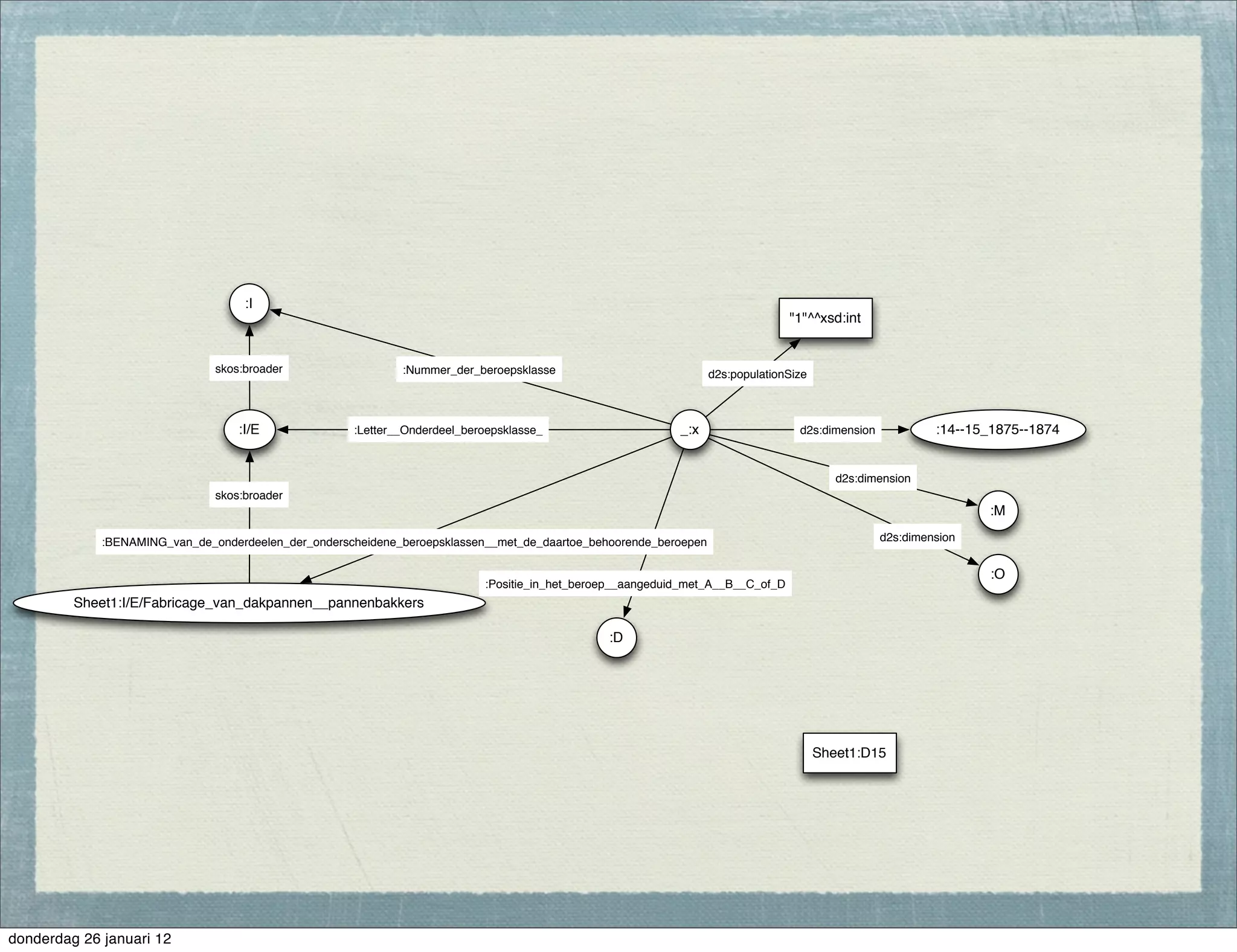
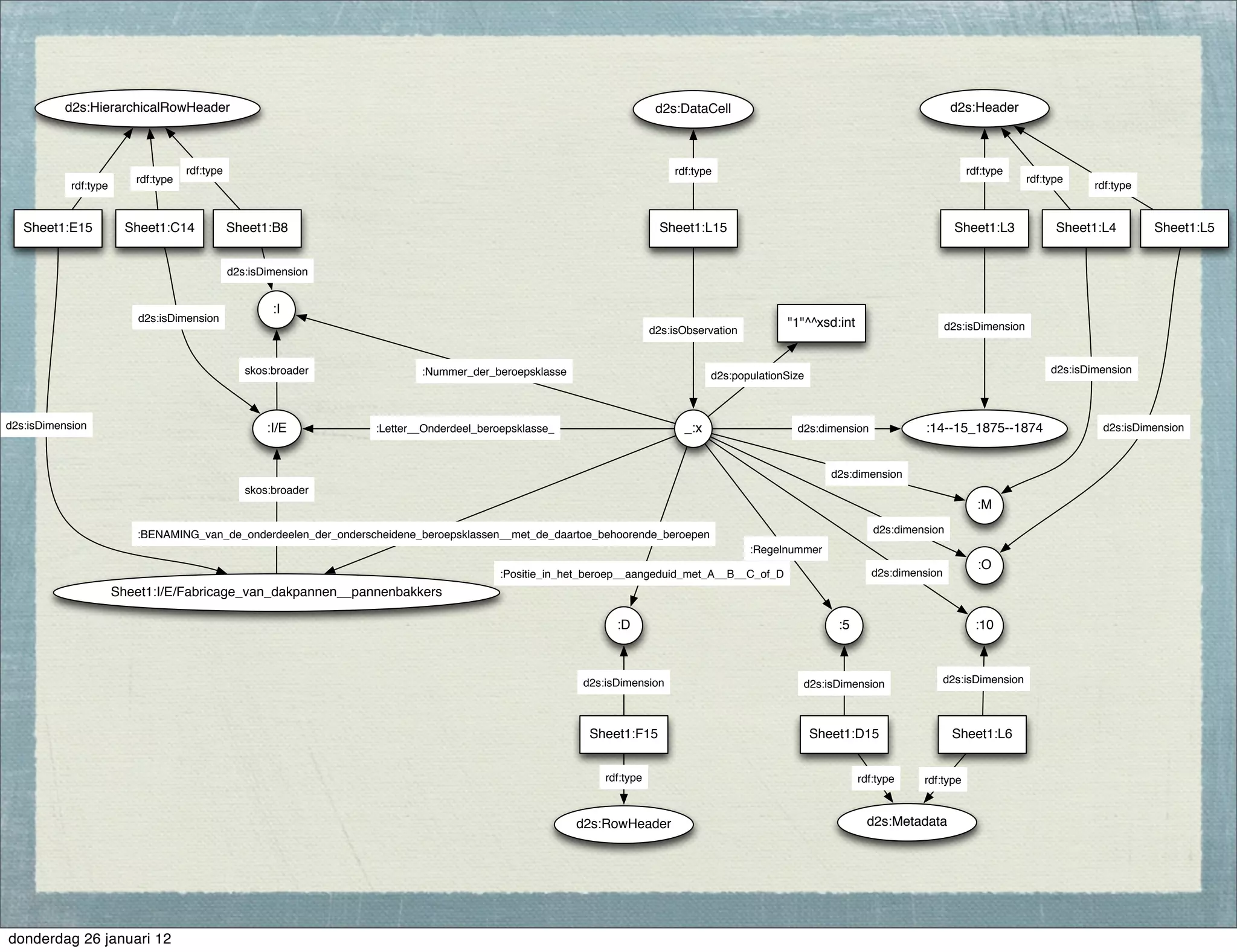


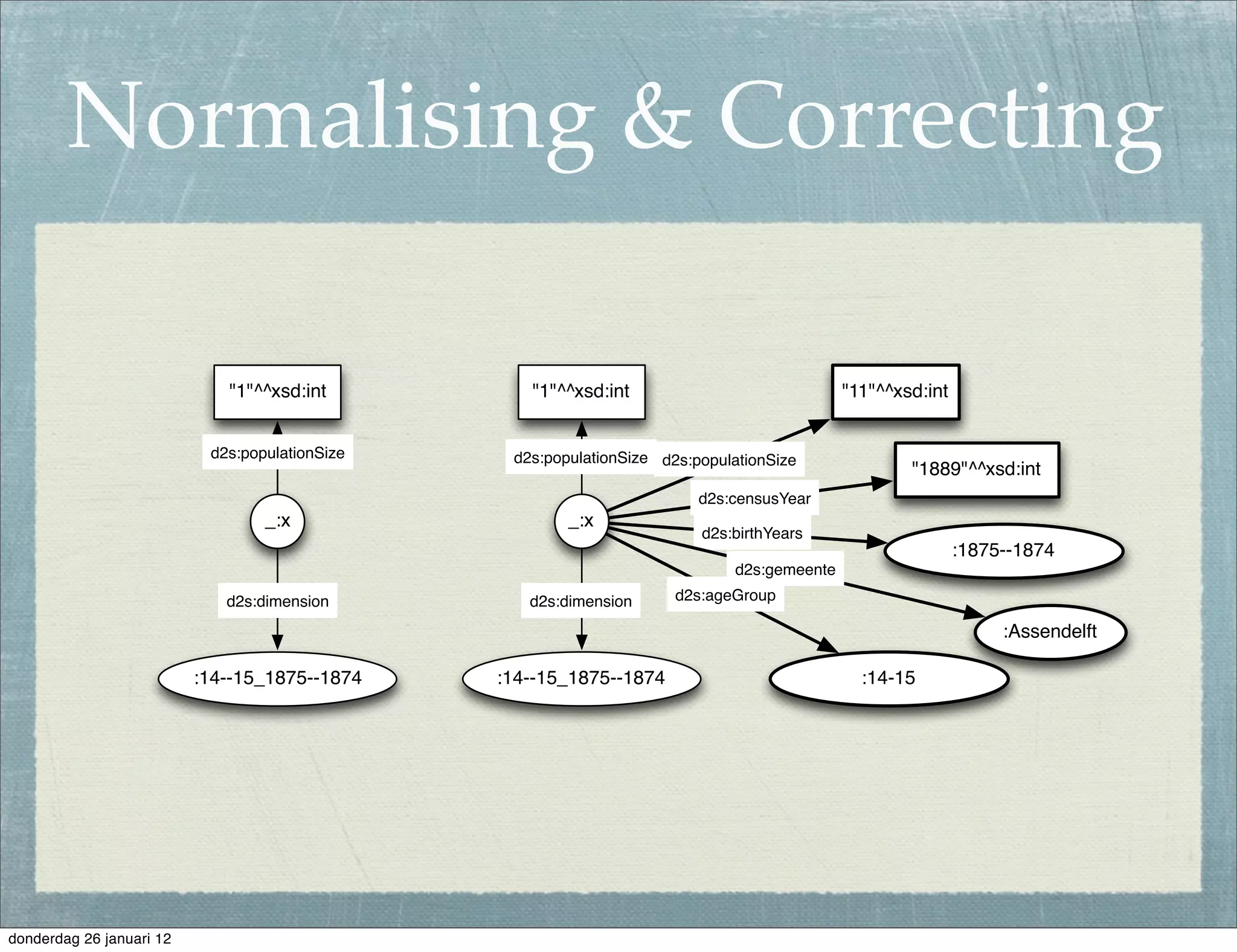
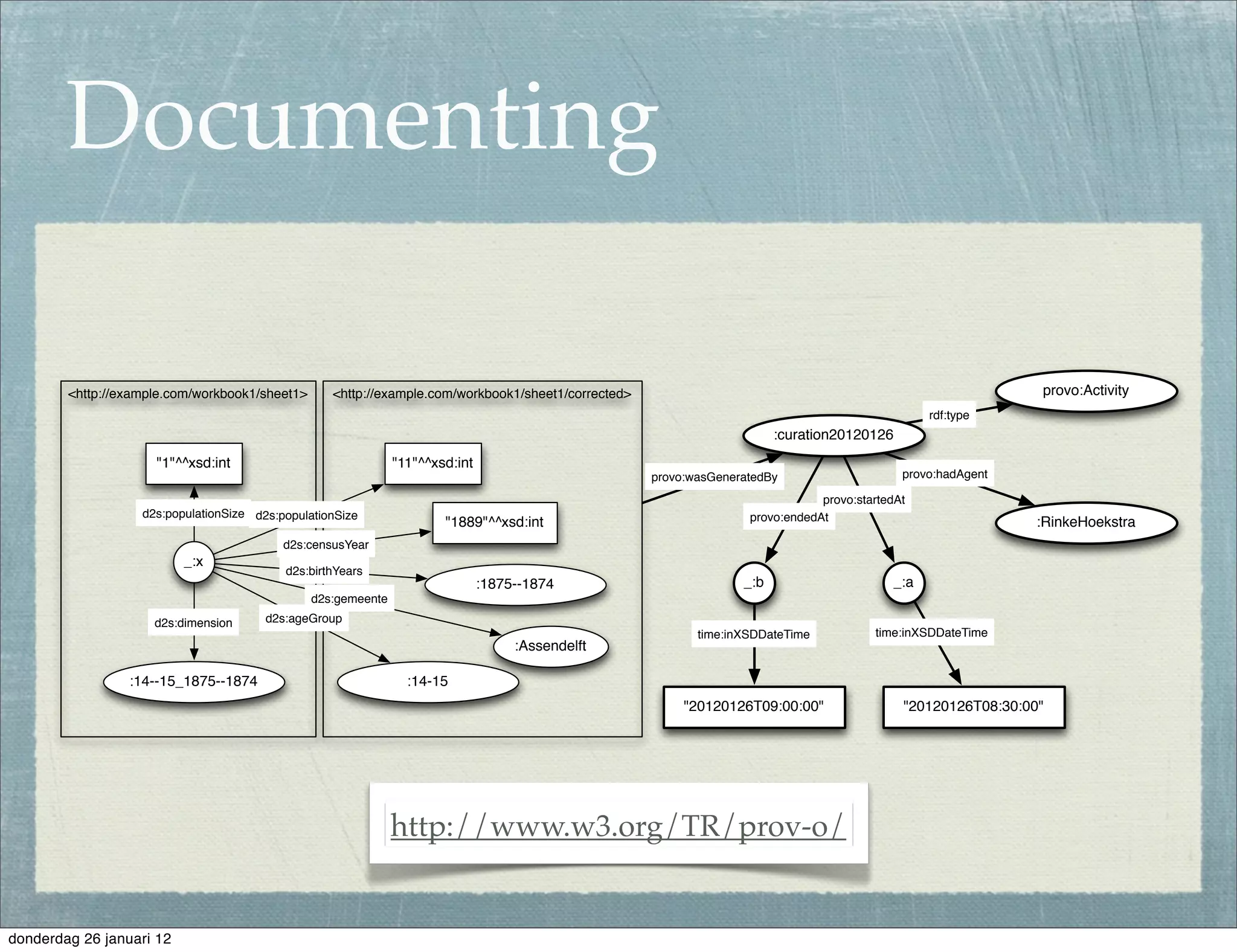
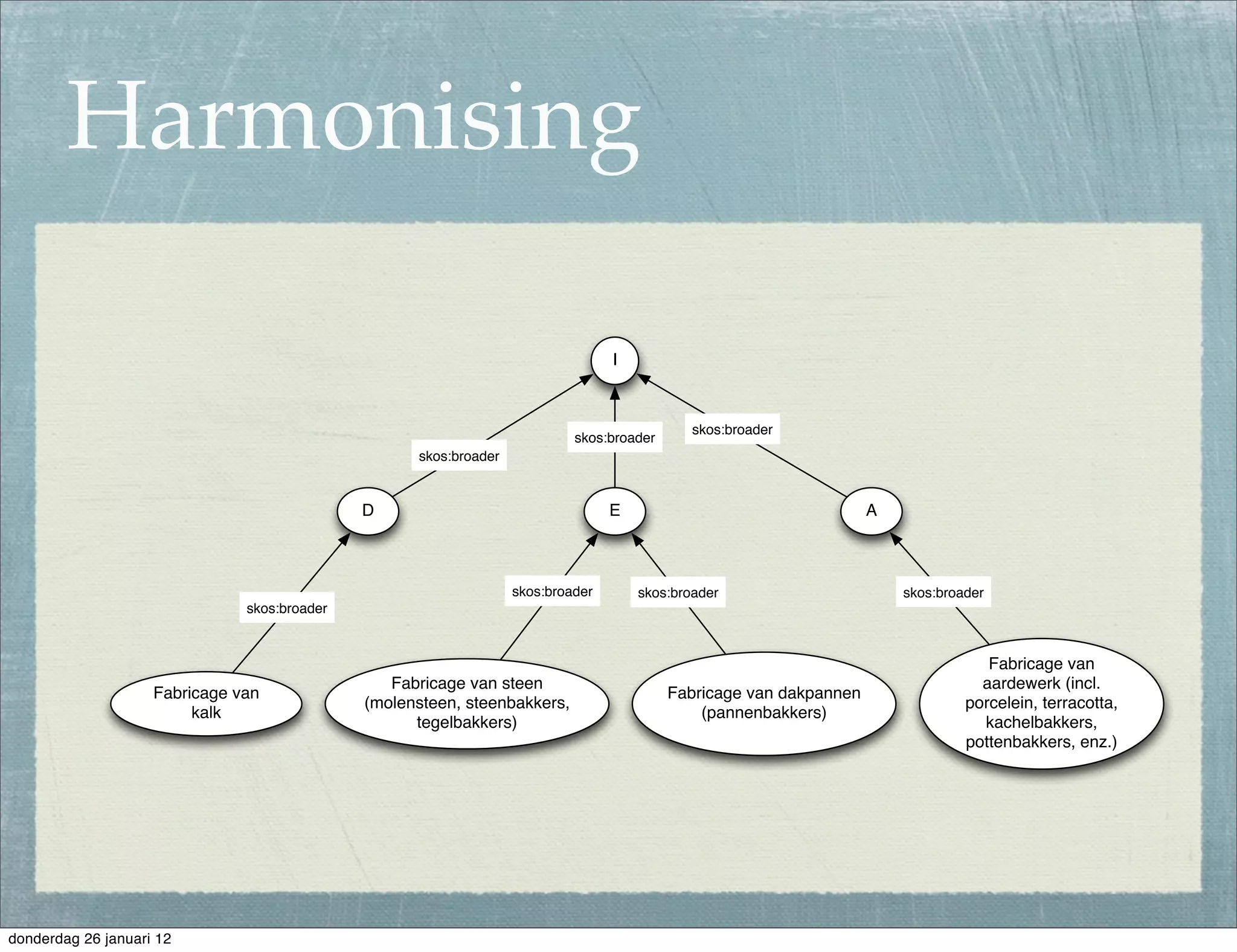
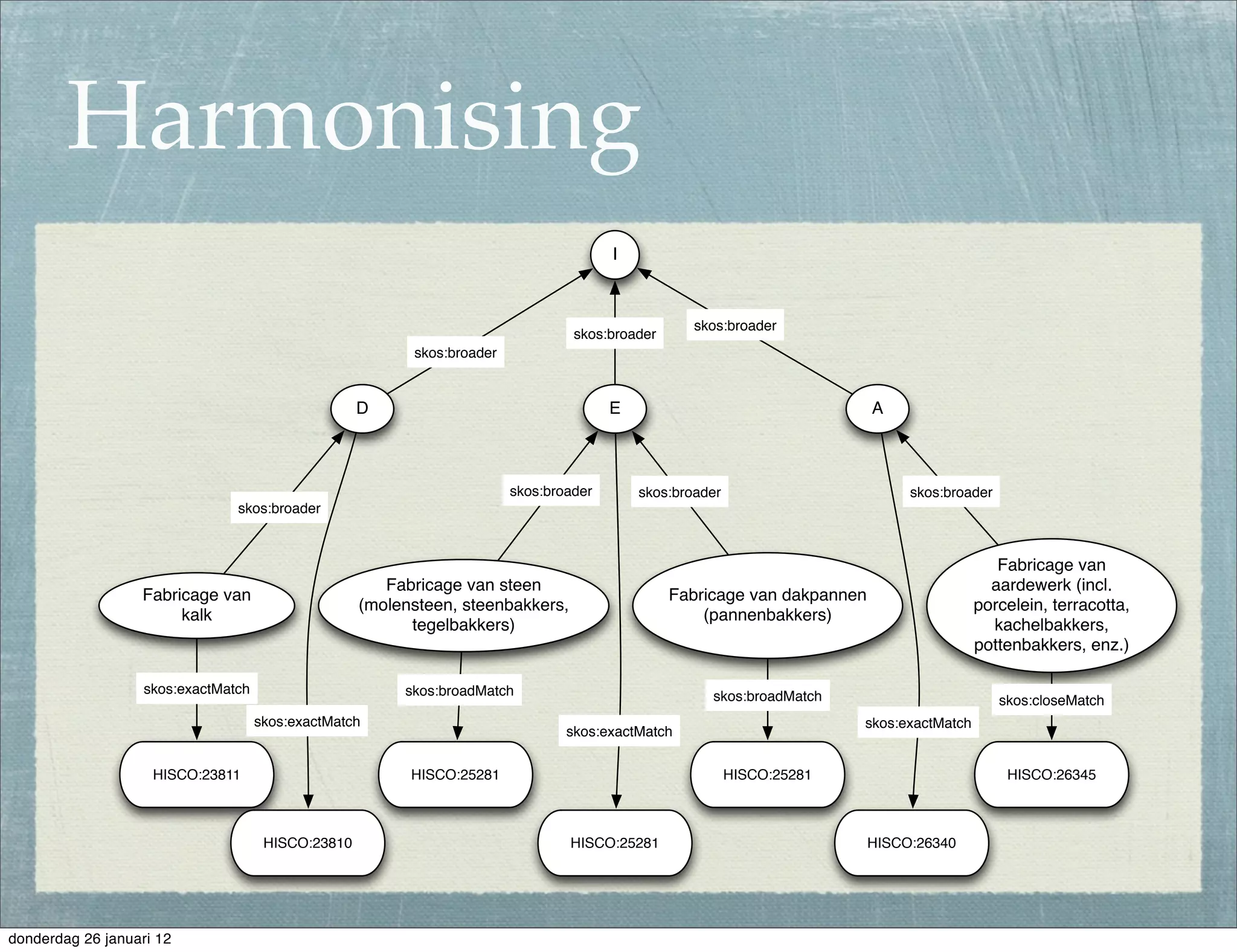
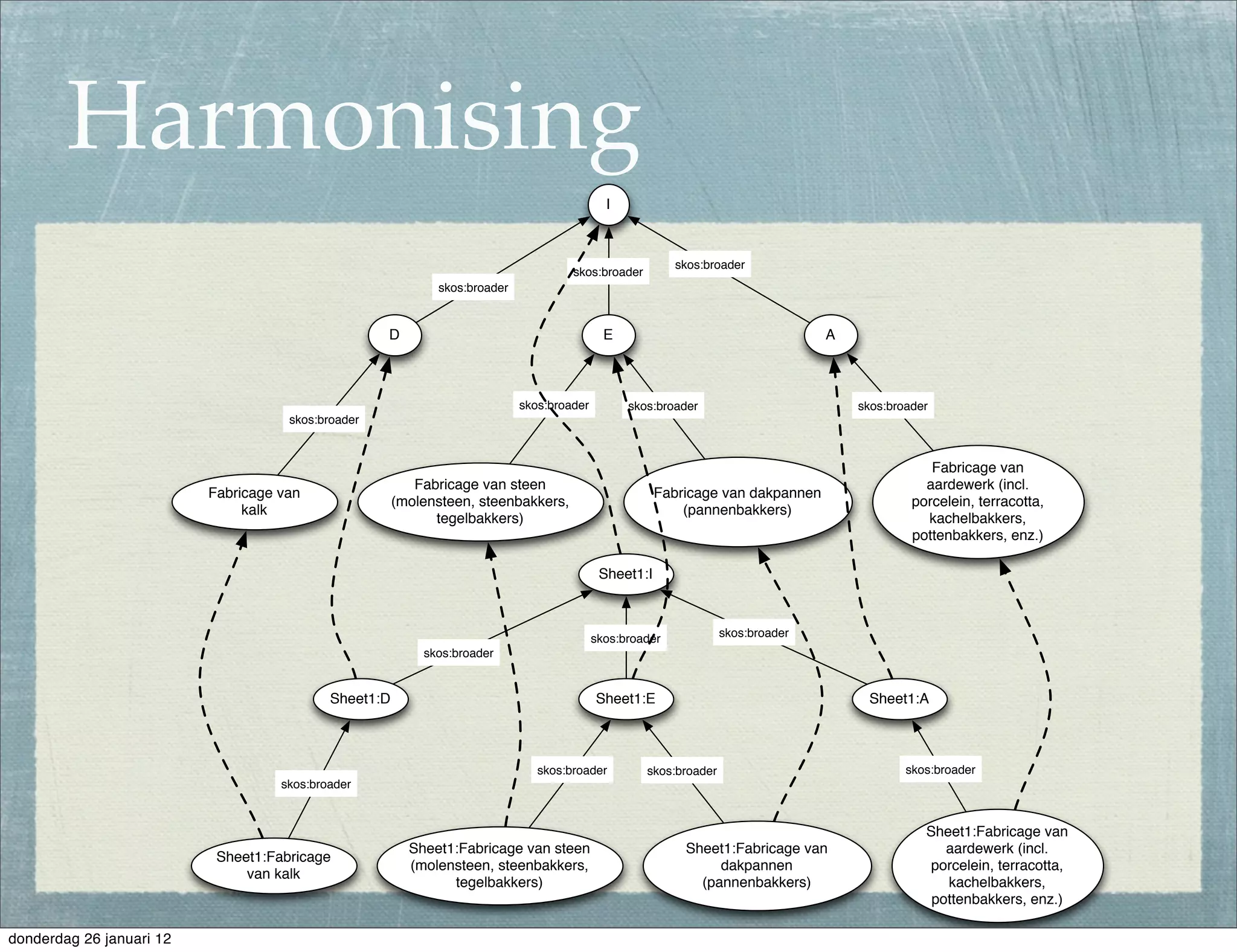
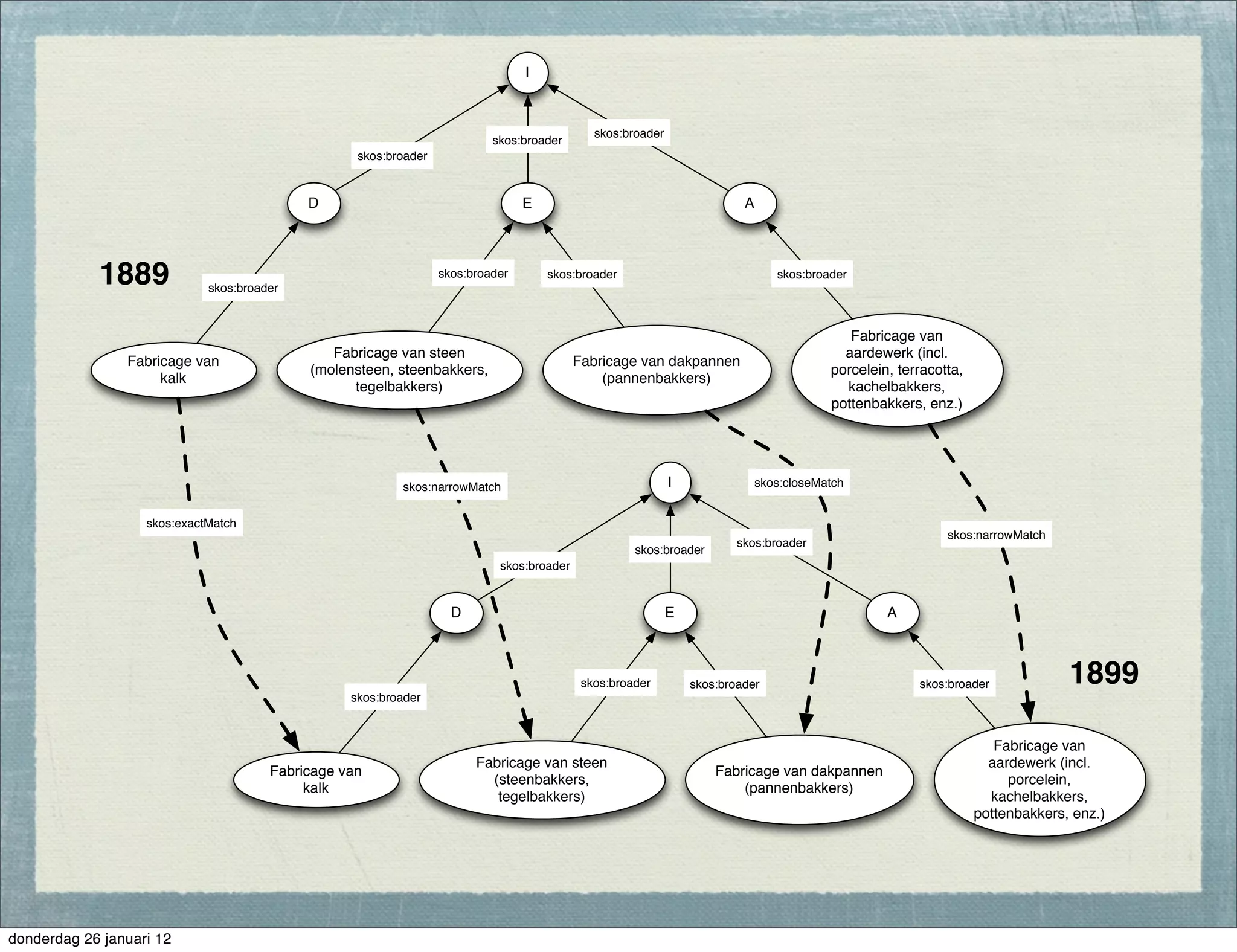
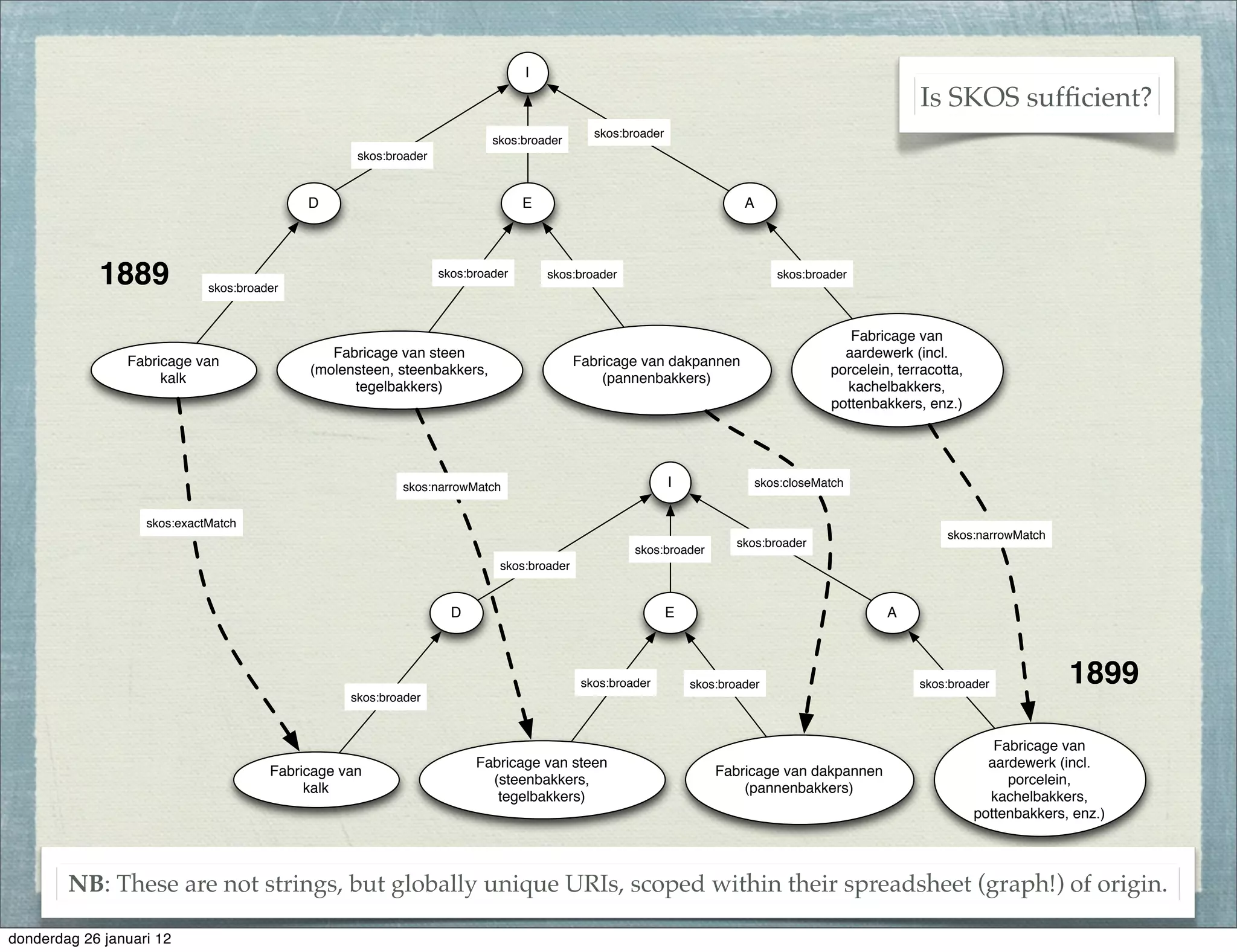
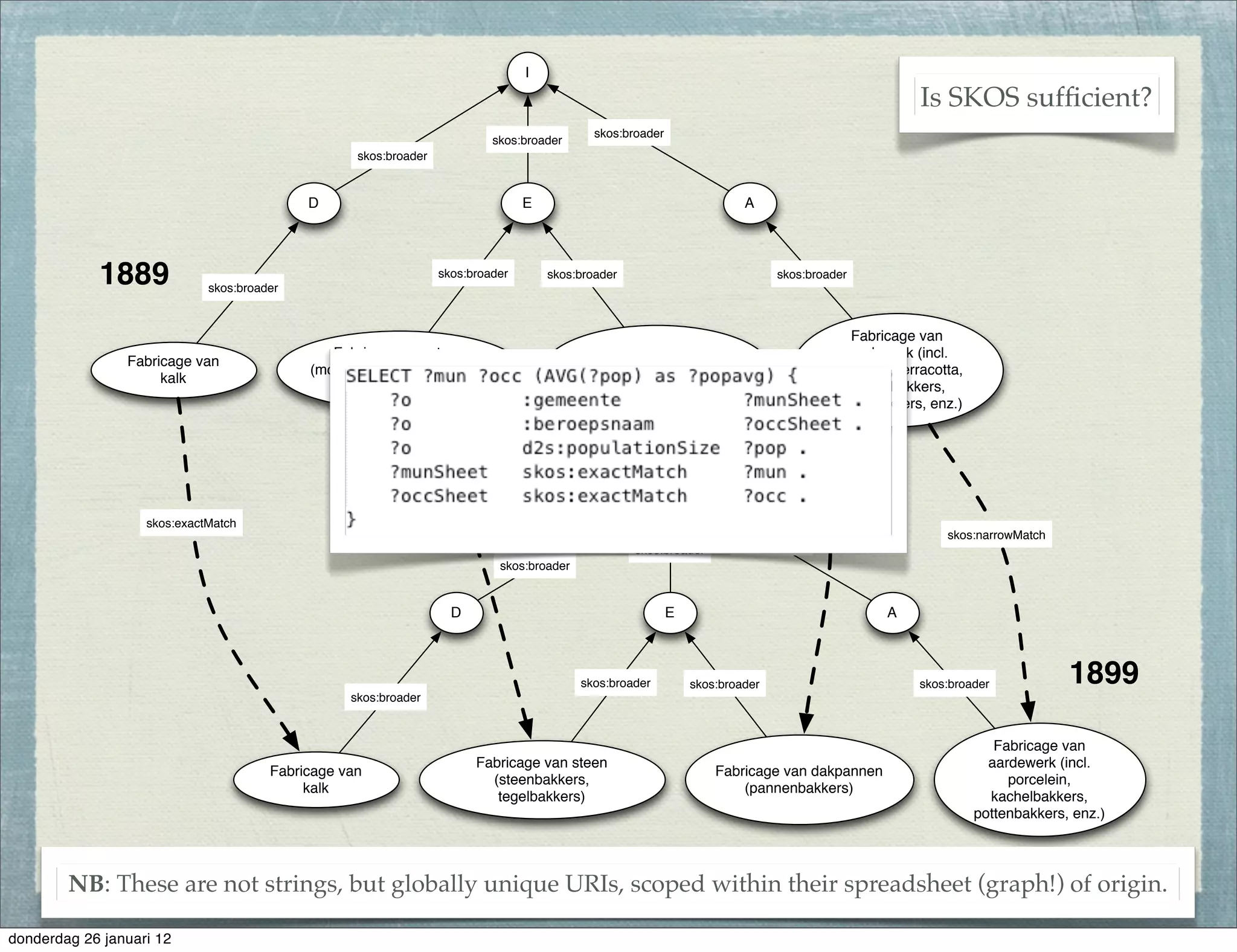
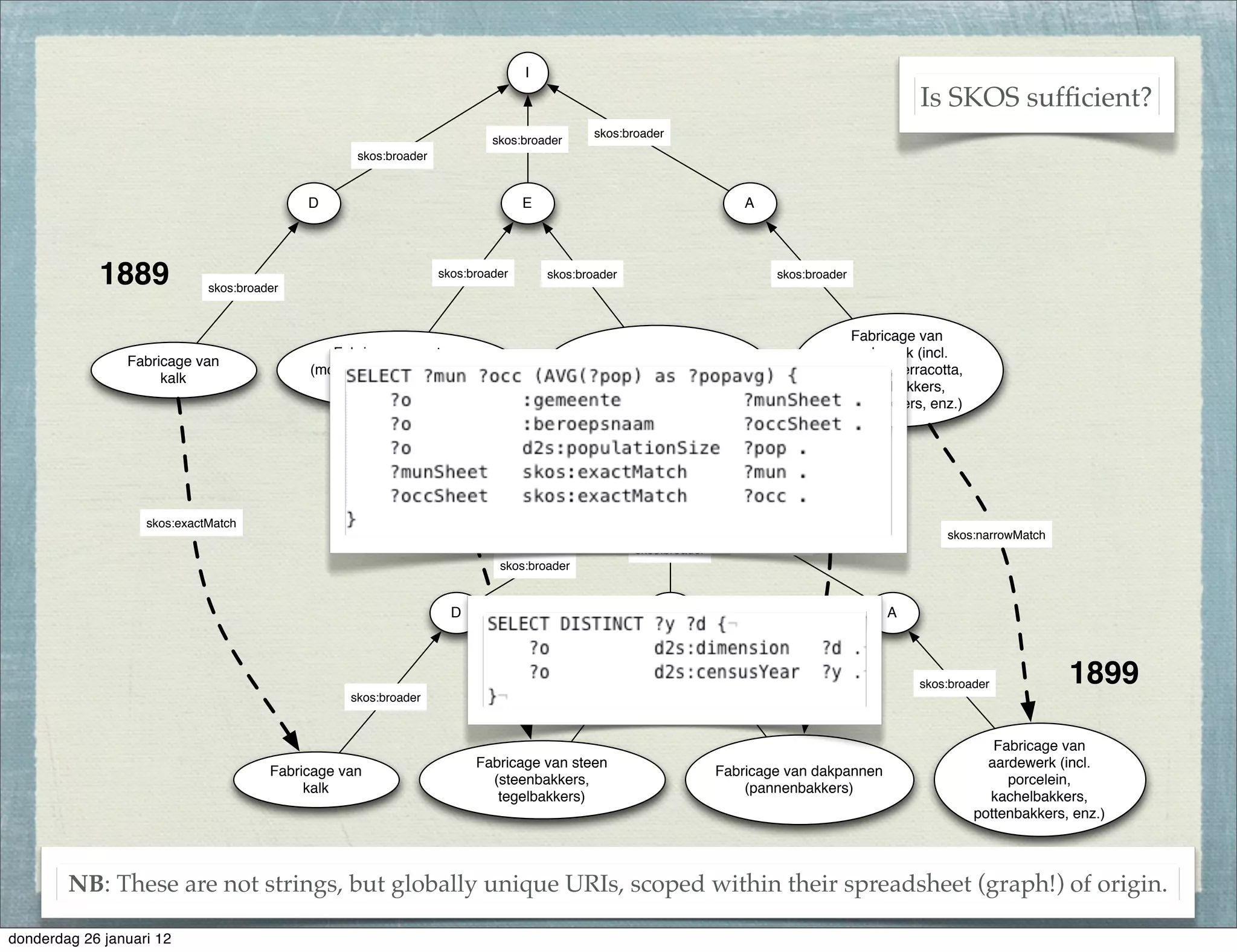






The document discusses the challenges and procedures involved in linking historical census data for analysis, highlighting issues like data structure, errors, and normalization. It explains the transformation from disparate Excel spreadsheets to a unified linked data model, emphasizing the use of RDF and SPARQL for data querying and visualization. The advantages of this approach include improved data integration and documentation, while potential downsides involve performance and limited support for certain operations.



































































