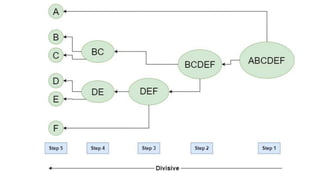
The document discusses clustering algorithms, focusing on their role in big data analytics for grouping similar data points. It details types of clustering methods, including k-means and hierarchical clustering, explaining their functions and applications, particularly in image segmentation. The advantages and disadvantages of each method are outlined, emphasizing the importance of choosing an appropriate technique based on specific data and goals.















































![Clustering[306] [Read-Only].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/clustering306read-only-230112103535-3fb144db-thumbnail.jpg?width=640&height=640&fit=bounds)



































