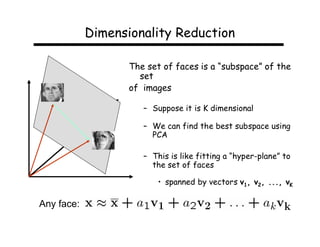
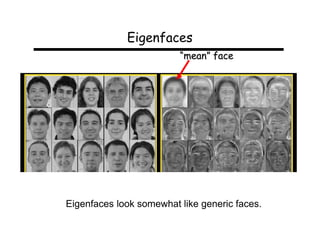
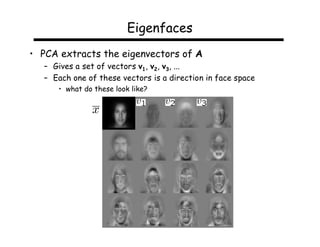
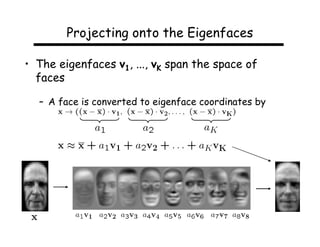
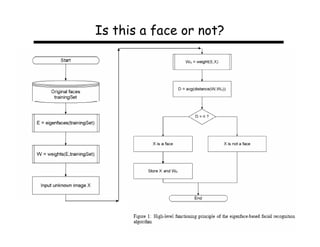
This document describes using principal component analysis (PCA) for object recognition from images. PCA is used to represent objects in an "eigenspace" where each object is represented by a point defined by its coordinates along the principal axes of variation among sample images. This provides an efficient representation that can handle variations in viewpoint, illumination, etc. by requiring fewer samples. The key steps are: (1) collect sample images and represent each as a high-dimensional vector, (2) compute eigenvectors of the sample covariance matrix to define the eigenspace, (3) project new images into this space for recognition.












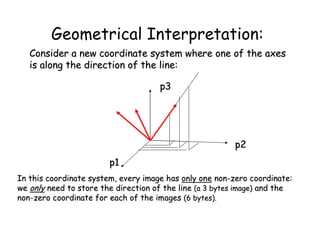





![PCA Theorem
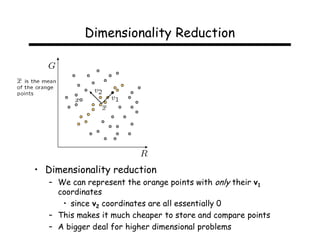
Let Q = X XT be the N2 x N2 matrix:
Notes:
1. Q is square
2. Q is symmetric
3. Q is the covariance matrix [aka scatter matrix]
4. Q can be very large (remember that N2 is the number of
pixels in the template)](https://image.slidesharecdn.com/lecture32-110524023636-phpapp02/85/Lecture32-19-320.jpg)




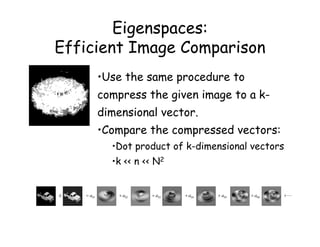


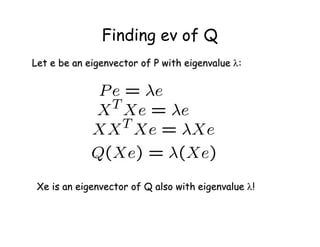










![Example: EigenFaces
These slides from S. Narasimhan, CMU
= +
• An image is a point in a high dimensional space
– An N x M image is a point in RNM
– We can define vectors in this space as we did in the 2D case
[Thanks to Chuck Dyer, Steve Seitz, Nishino]](https://image.slidesharecdn.com/lecture32-110524023636-phpapp02/85/Lecture32-39-320.jpg)