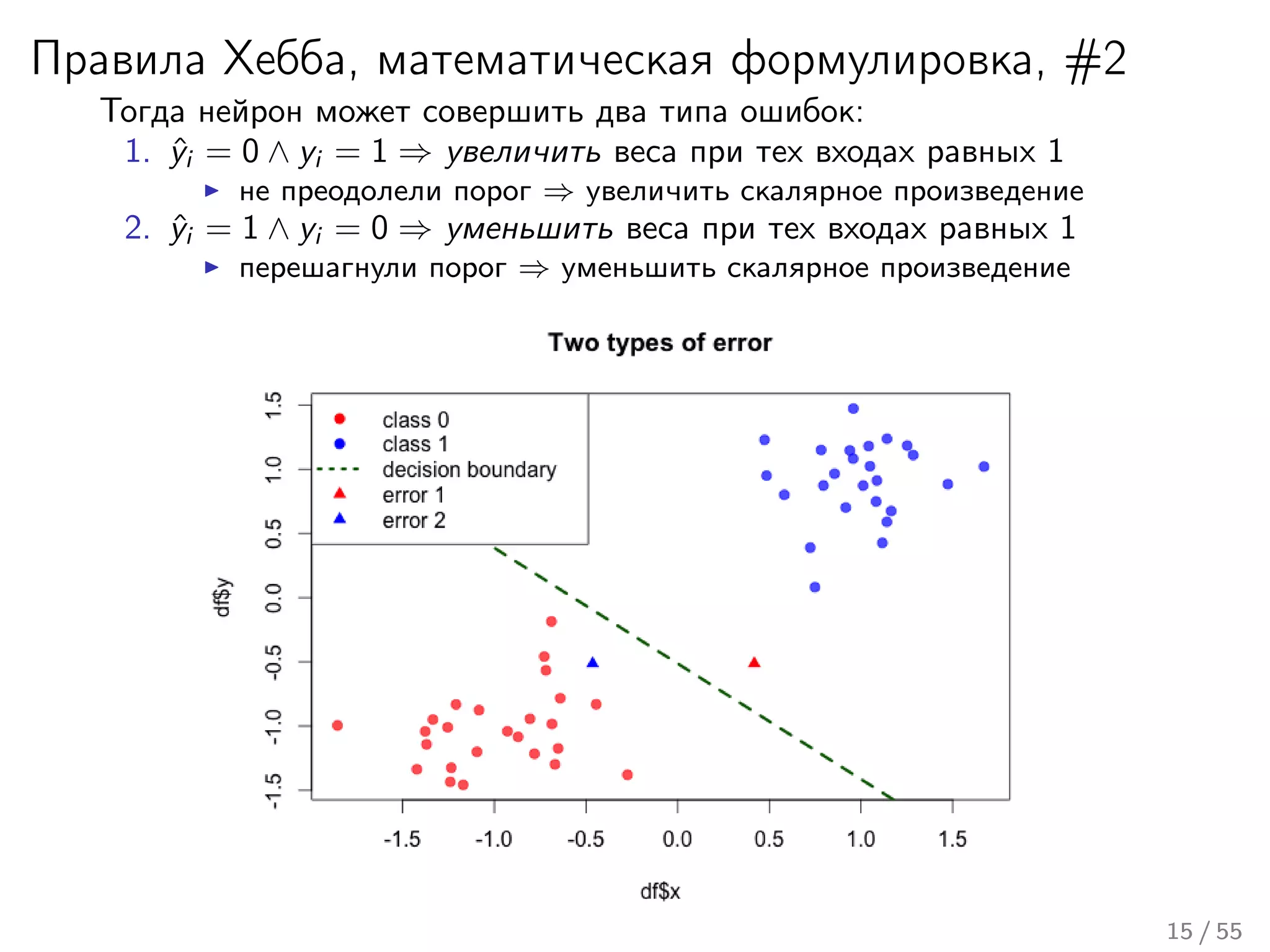
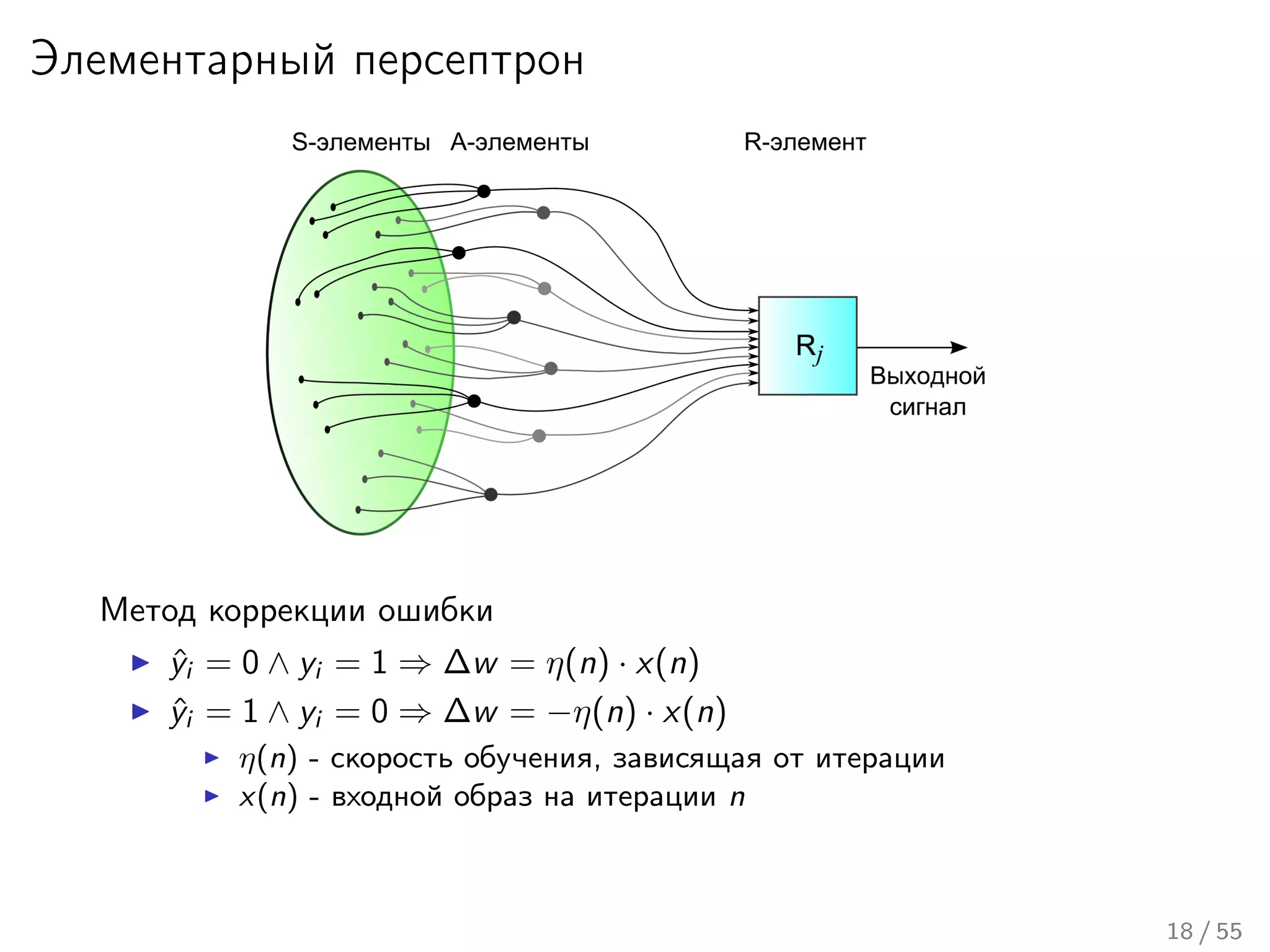
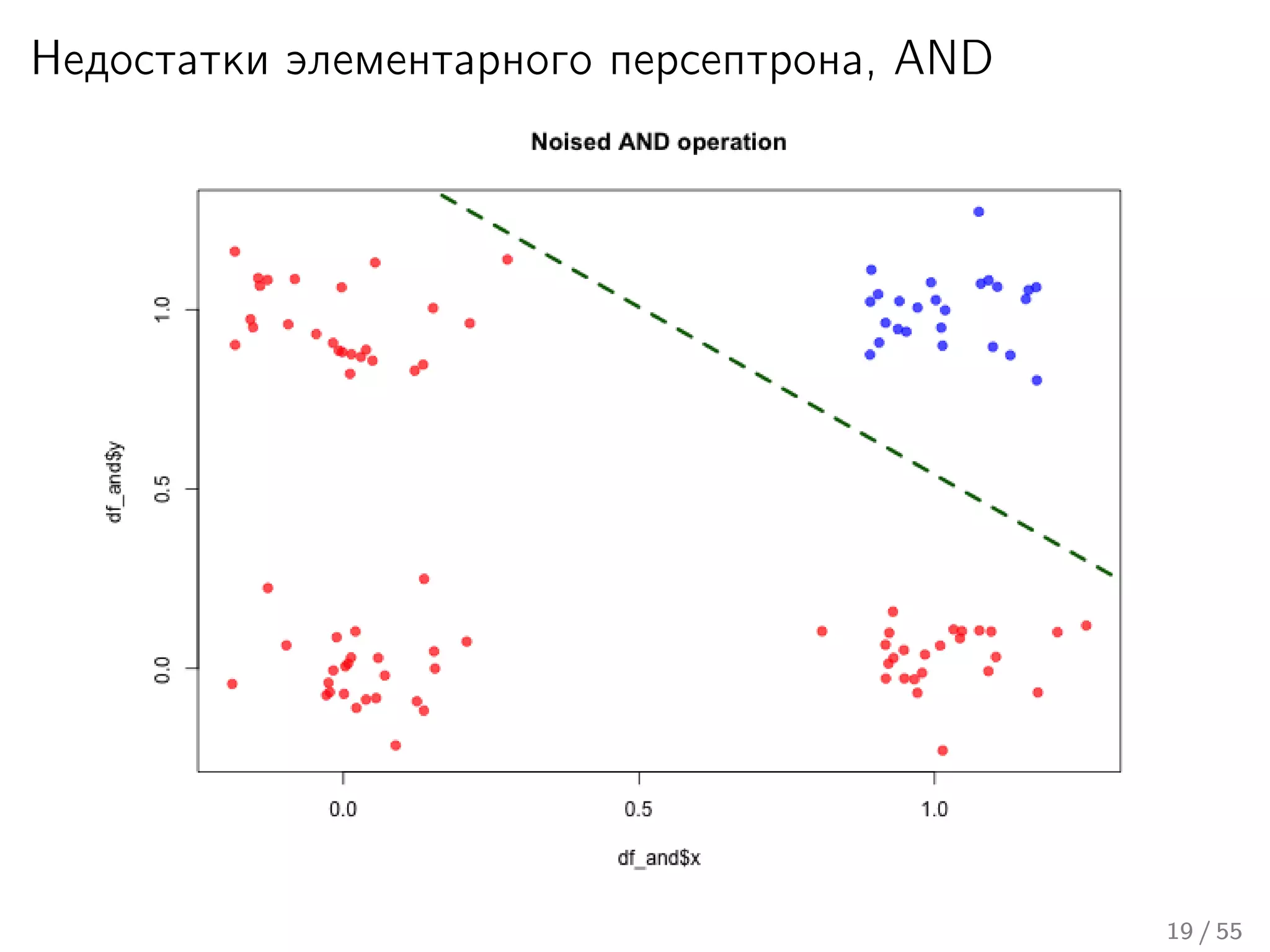
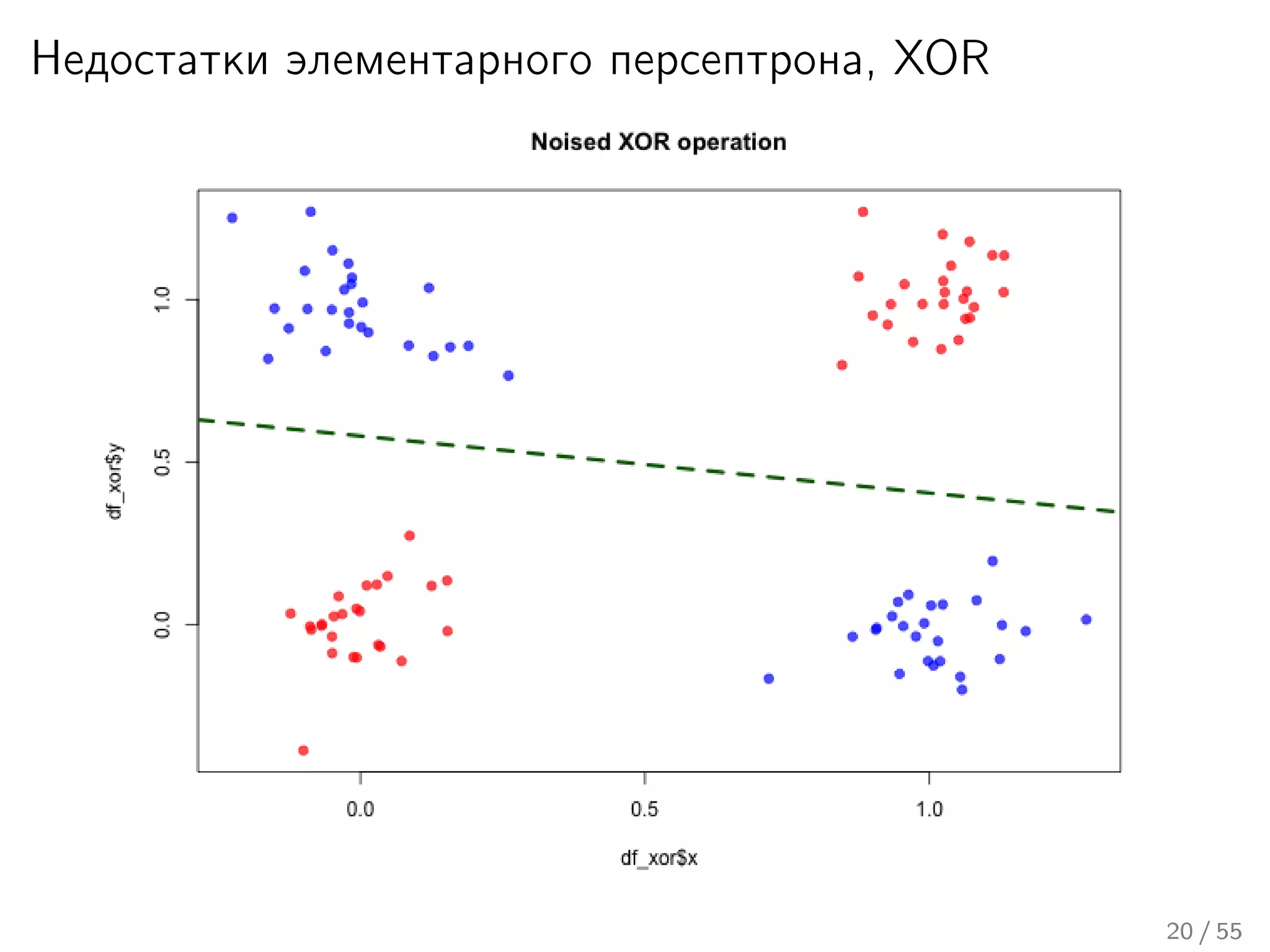
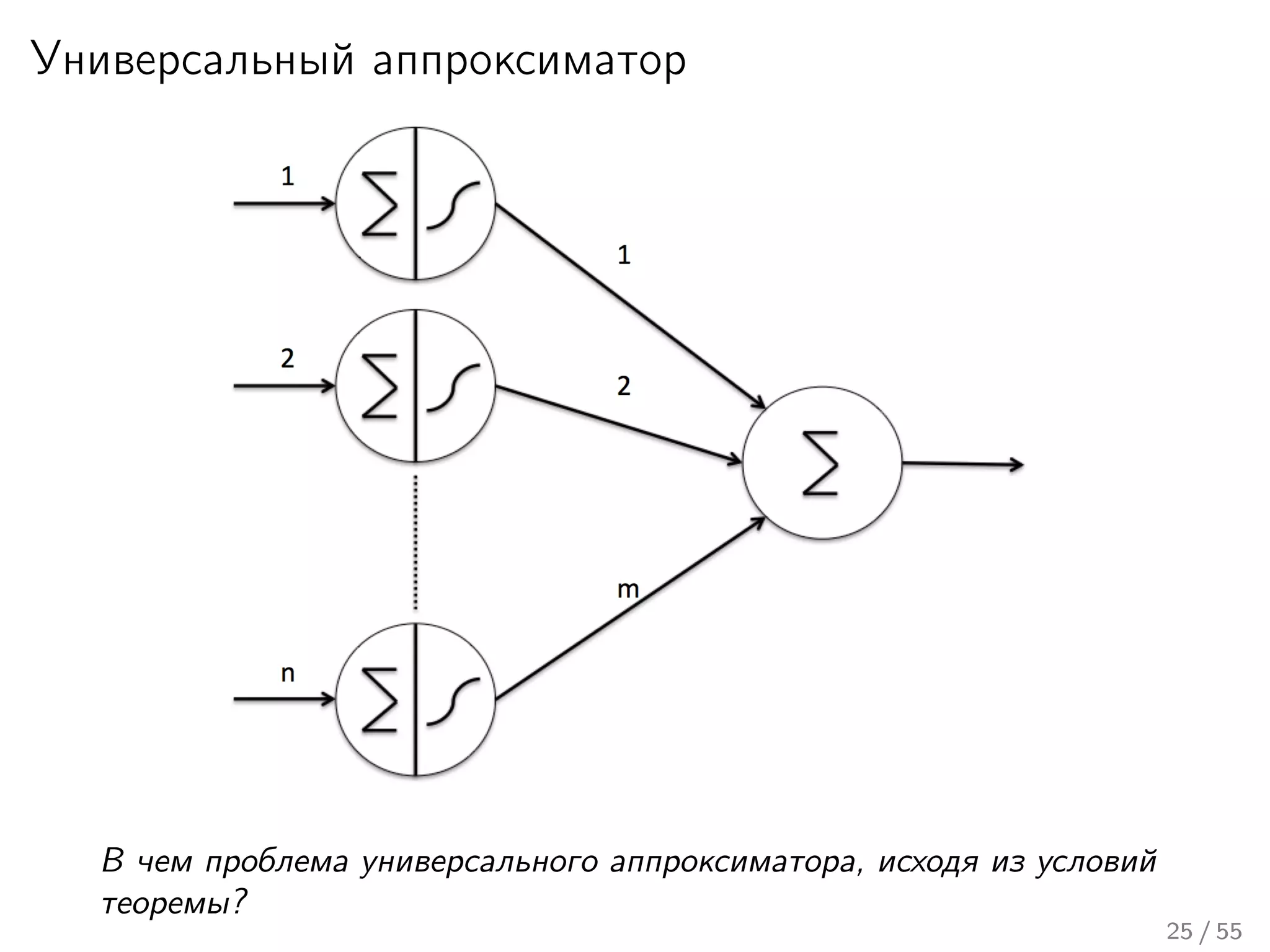
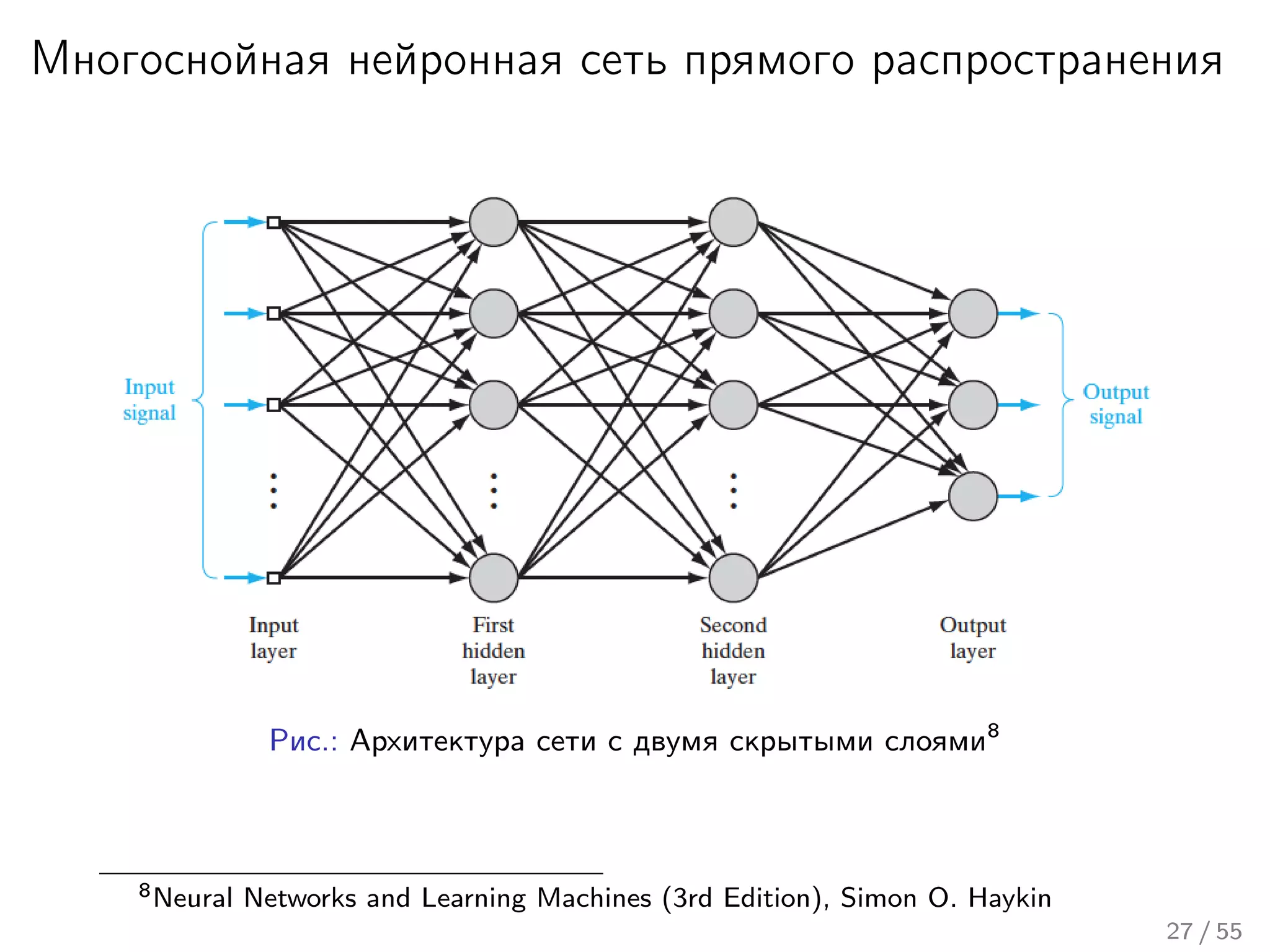
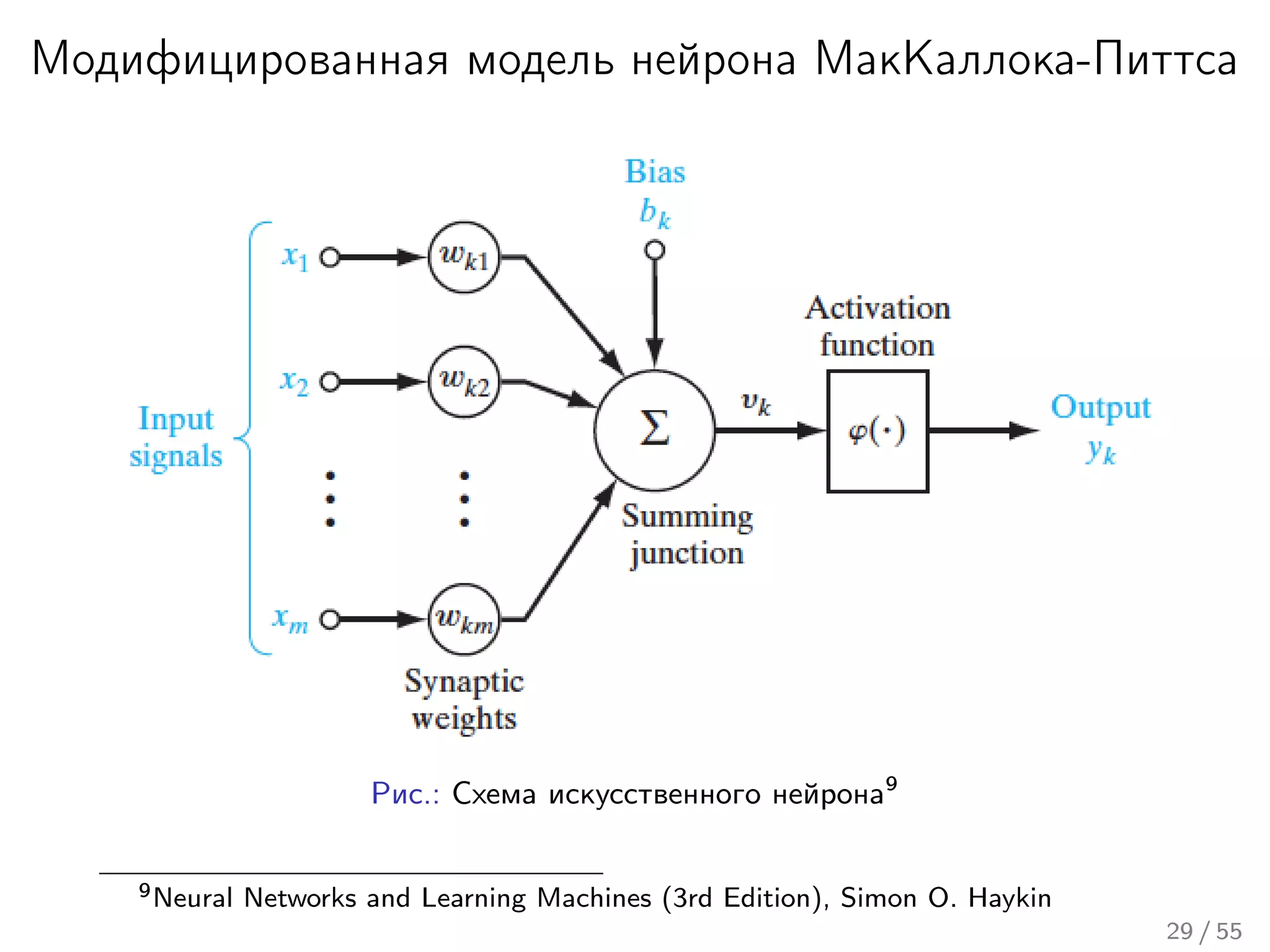
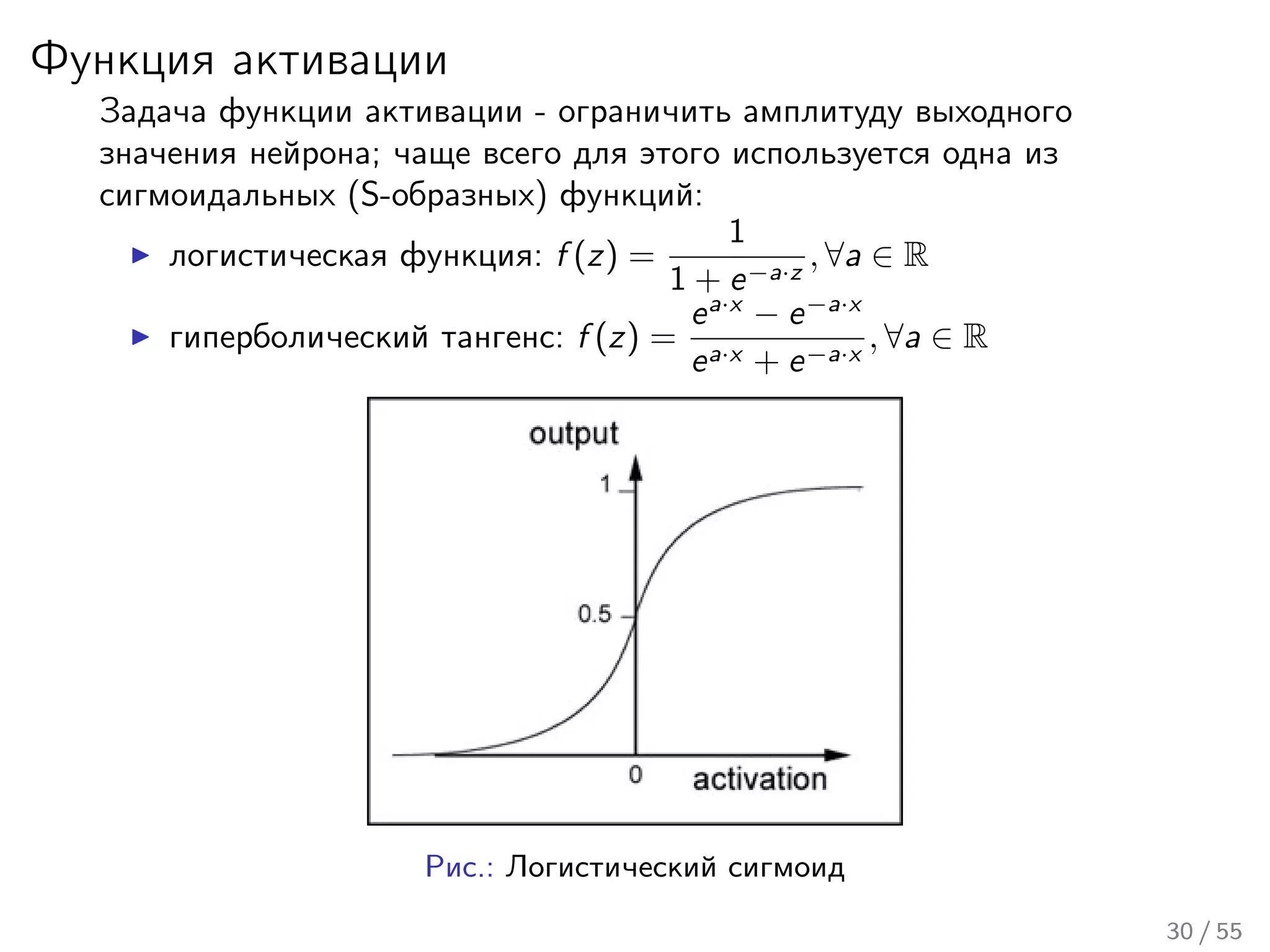
Лекция охватывает основы нейронных сетей, включая историю их теории и ключевые концепции, такие как многослойные нейронные сети и алгоритмы обратного распространения ошибки. Обсуждаются различные модели нейронов и классы алгоритмов, а также векторные представления и механизмы обучения, включая правила Хебба. Лекция также освещает достижения в нейробиологии и сравнивает работу мозга с современными компьютерными системами.







![Модель МакКаллока-Питтса (1943 год)
a (x) = θ
n
j=1 wj · xi − w0 ;
θ (z) = [z ≥ 0] = 0,z<0
1,z≥0 - функция Хевисайда;
эквивалентно линейному классификатору.
Данная модель, с незначительными изменениями, актуальна и по
сей день.
12 / 55](https://image.slidesharecdn.com/lecture10-150417051138-conversion-gate01/75/11-13-2048.jpg)