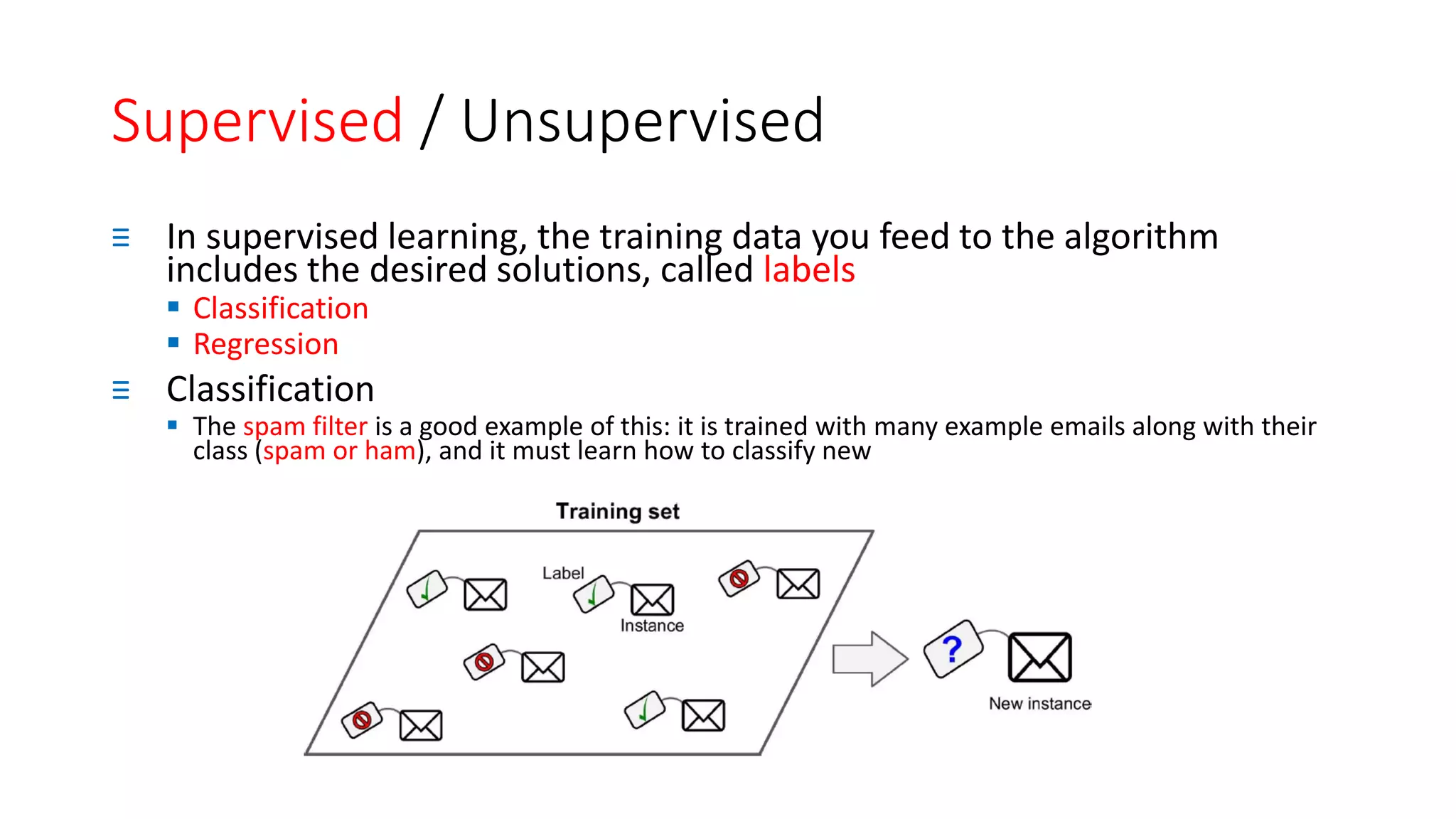
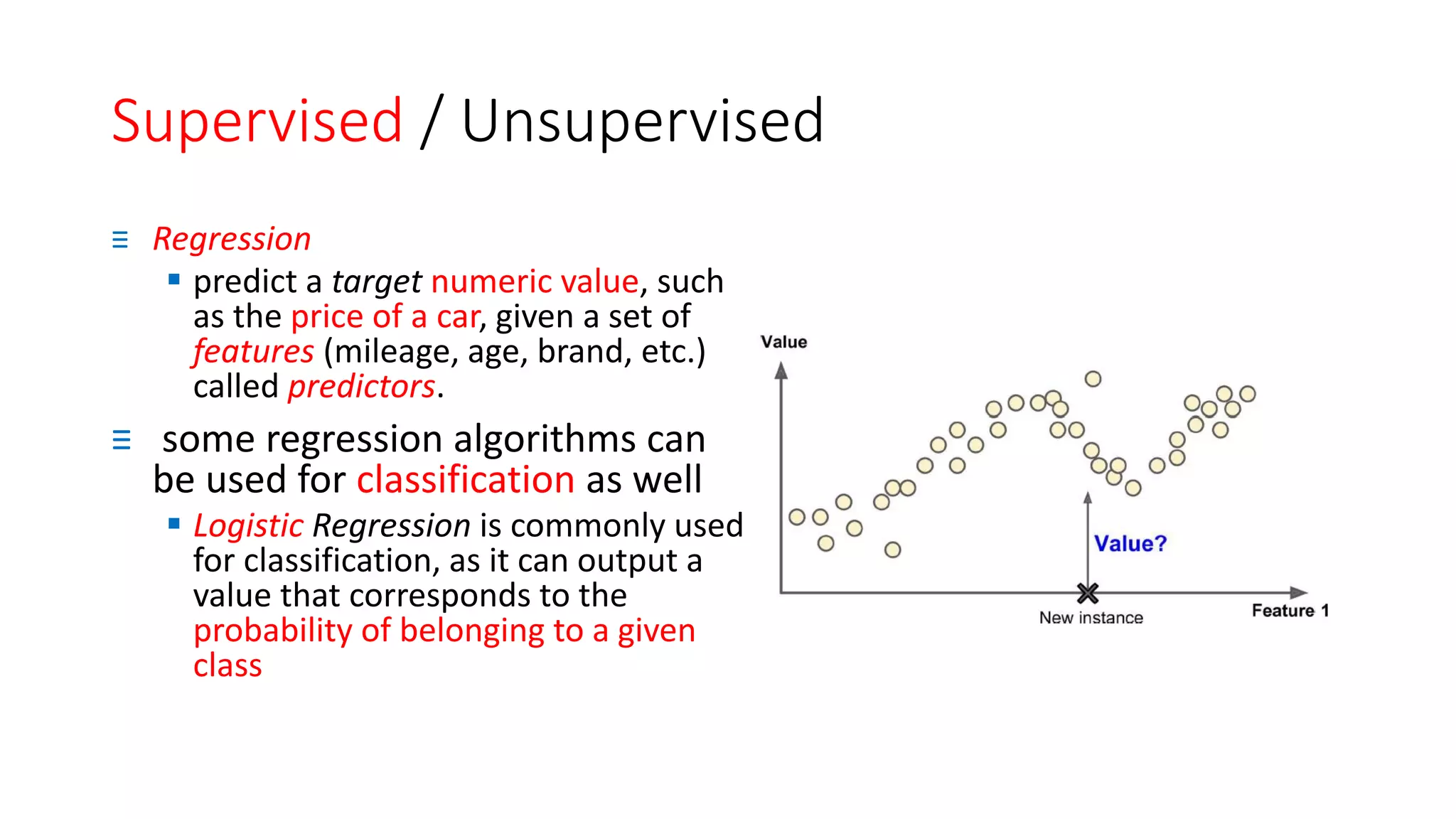
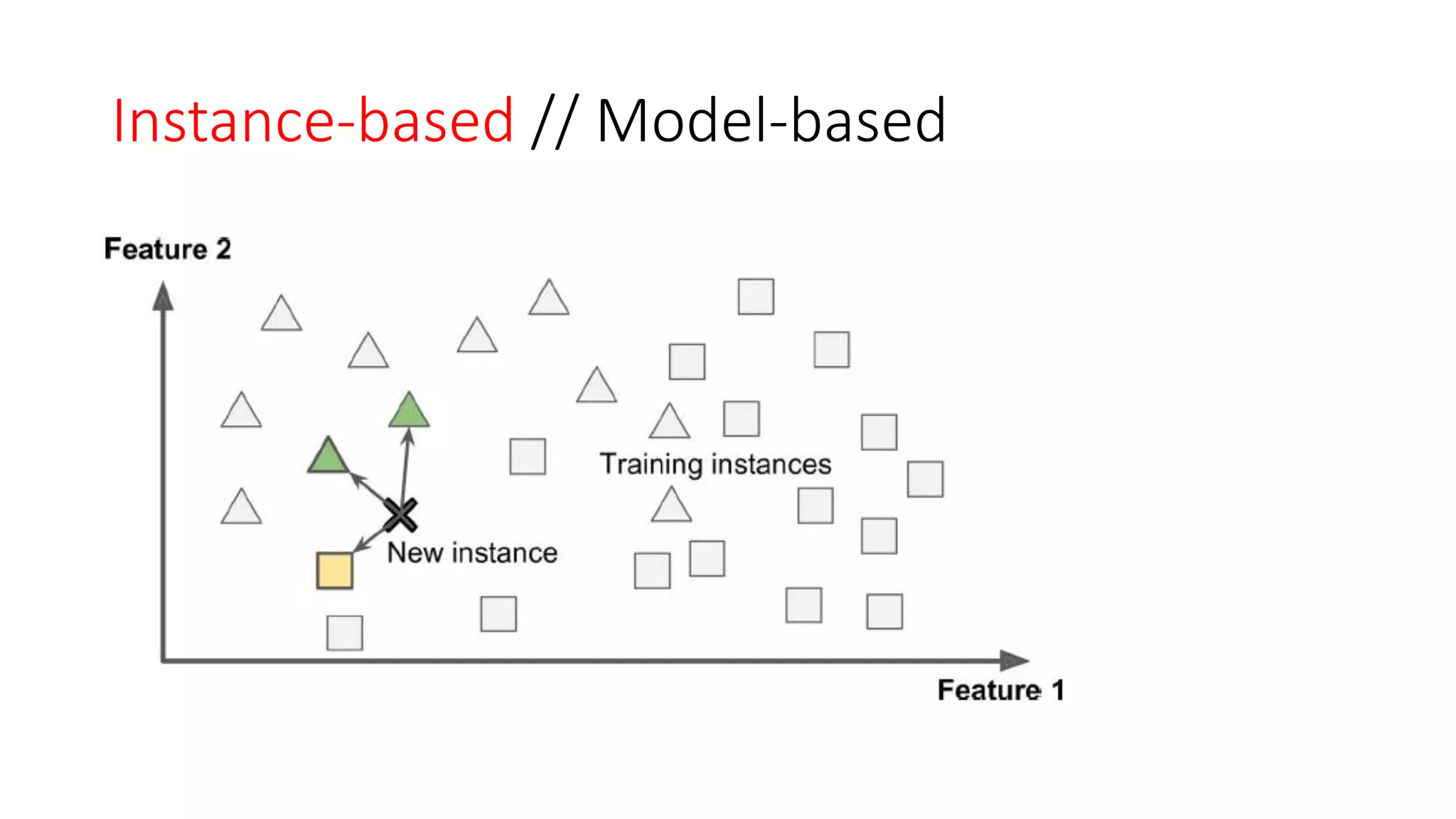
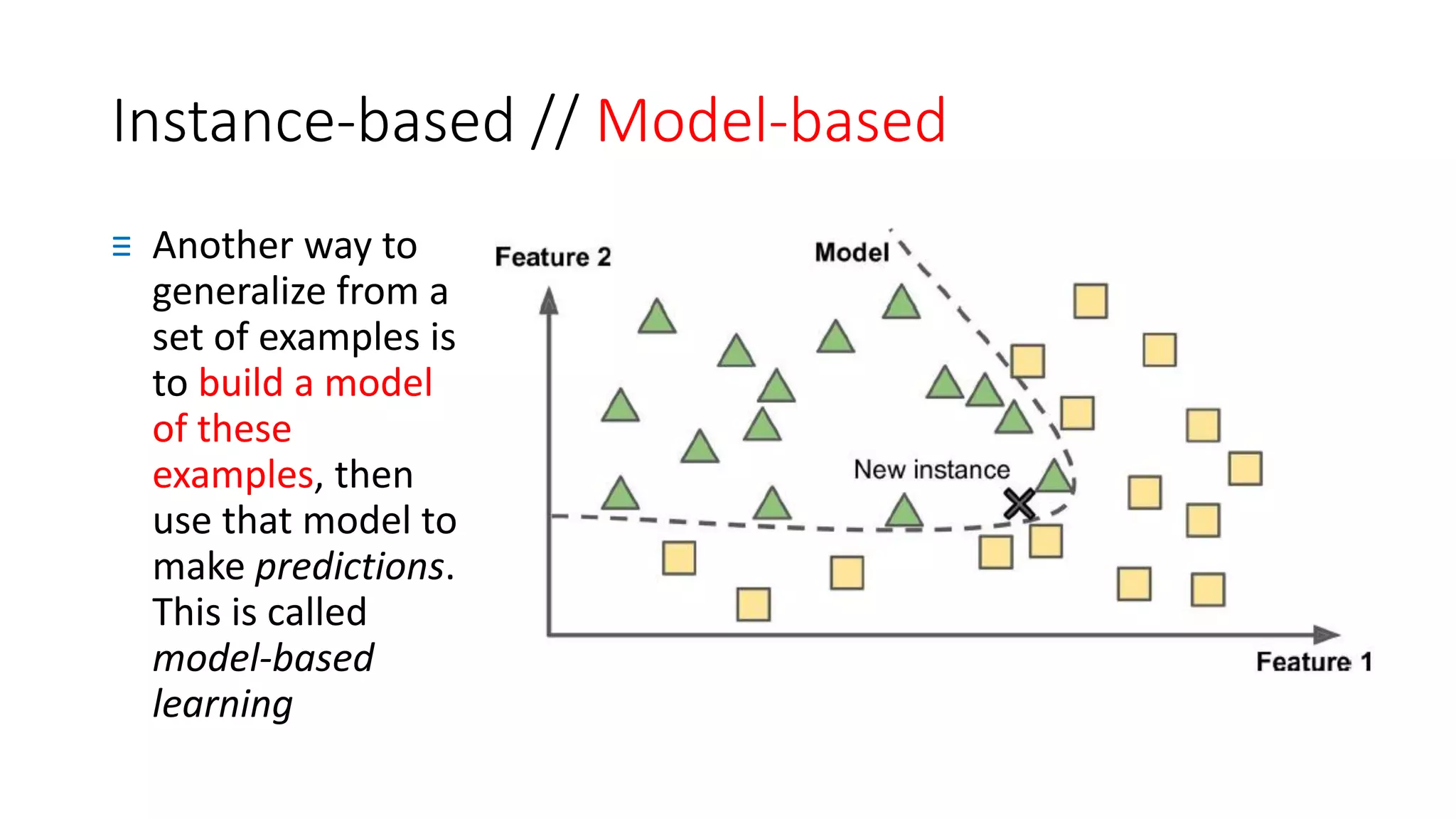
The document discusses machine learning types and concepts, including definitions, supervised and unsupervised learning, and various methods such as classification and regression. It explains differences in learning approaches, including online versus batch learning and instance-based versus model-based learning, emphasizing the importance of generalizing from training data. Key applications of each learning type, such as anomaly detection and association rule learning, are also highlighted.