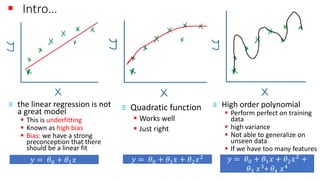
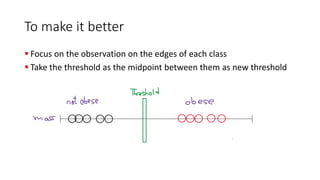
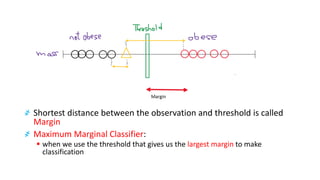
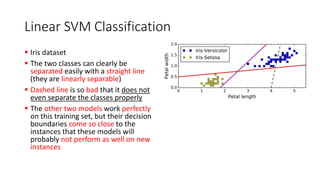
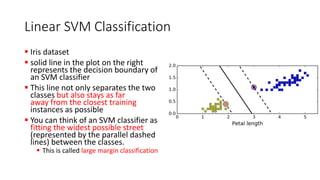
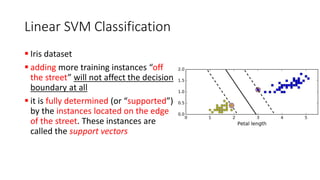
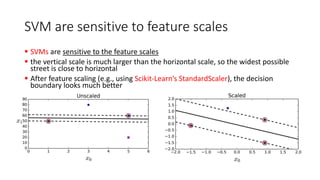
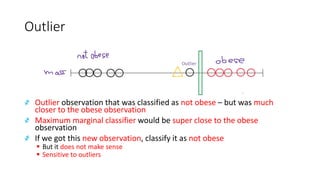
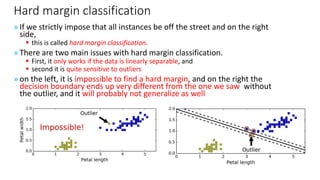
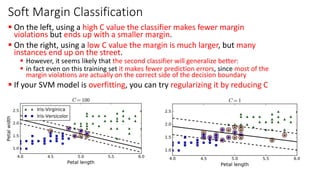
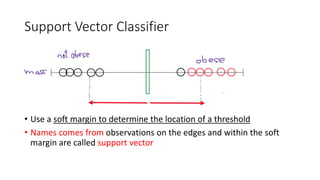
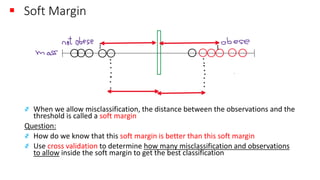
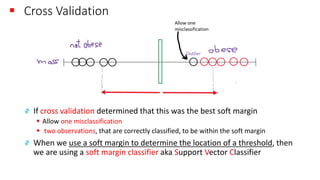
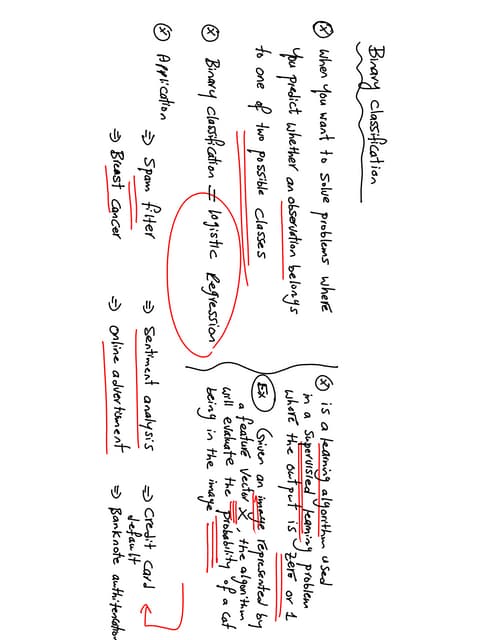
The document explains the concept of support vector classifiers, including the bias/variance tradeoff and its impact on model performance. It covers the importance of margin classification, differentiating between hard and soft margin classifications, and the use of cross-validation to fine-tune model thresholds. Additionally, it mentions practical implementation using scikit-learn for linear SVM on datasets like the iris dataset, emphasizing the sensitivity of SVMs to feature scales and outliers.






















![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)




