Download as PDF, PPTX


![[Machine Learning is the] field of study that
gives computers the ability to learn without
being explicitly programmed.
—Arthur Samuel, 1959
“](https://image.slidesharecdn.com/machinelearninglandscape-190827095303/75/Machine-Learning-Landscape-3-2048.jpg)




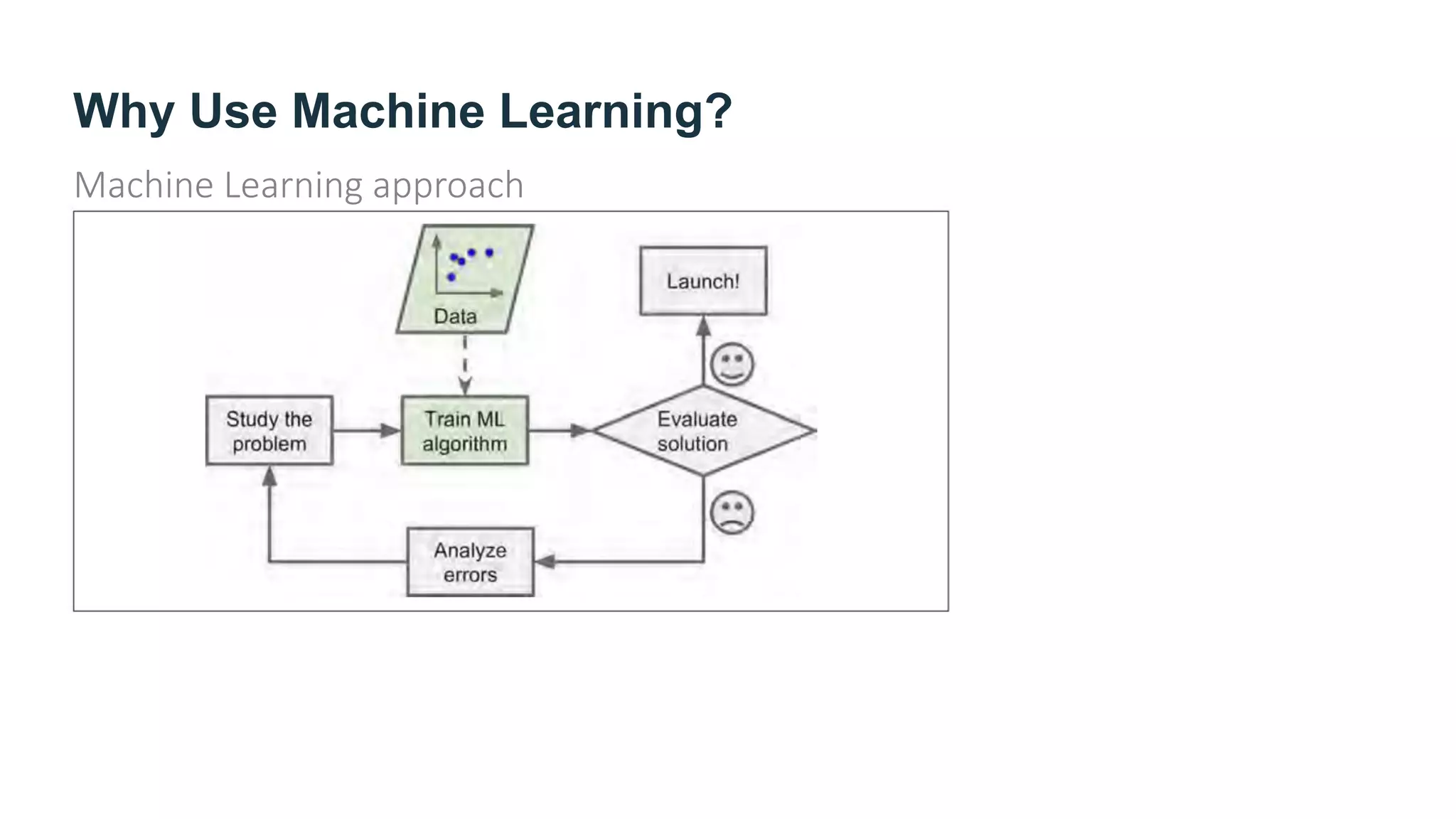

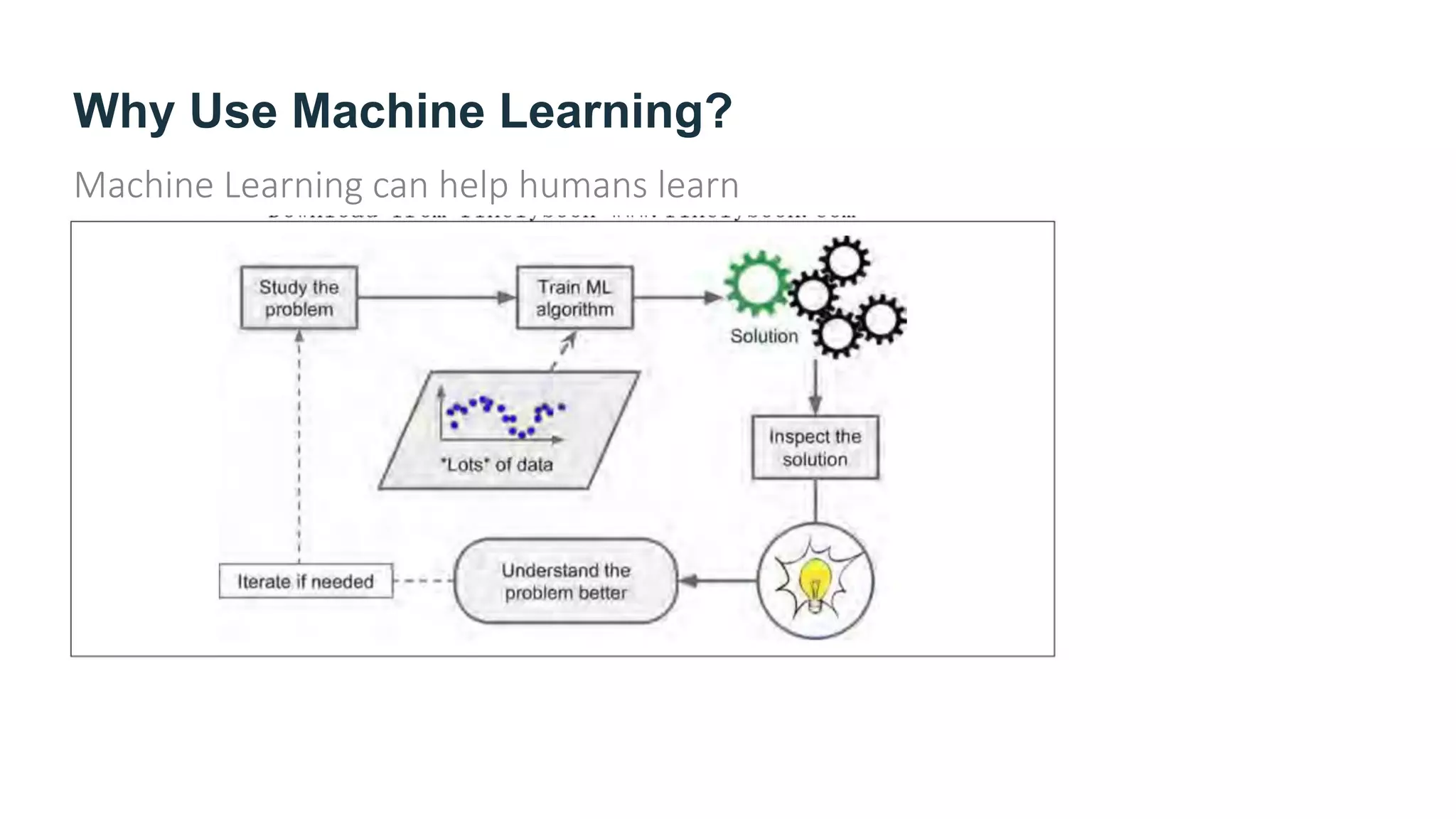



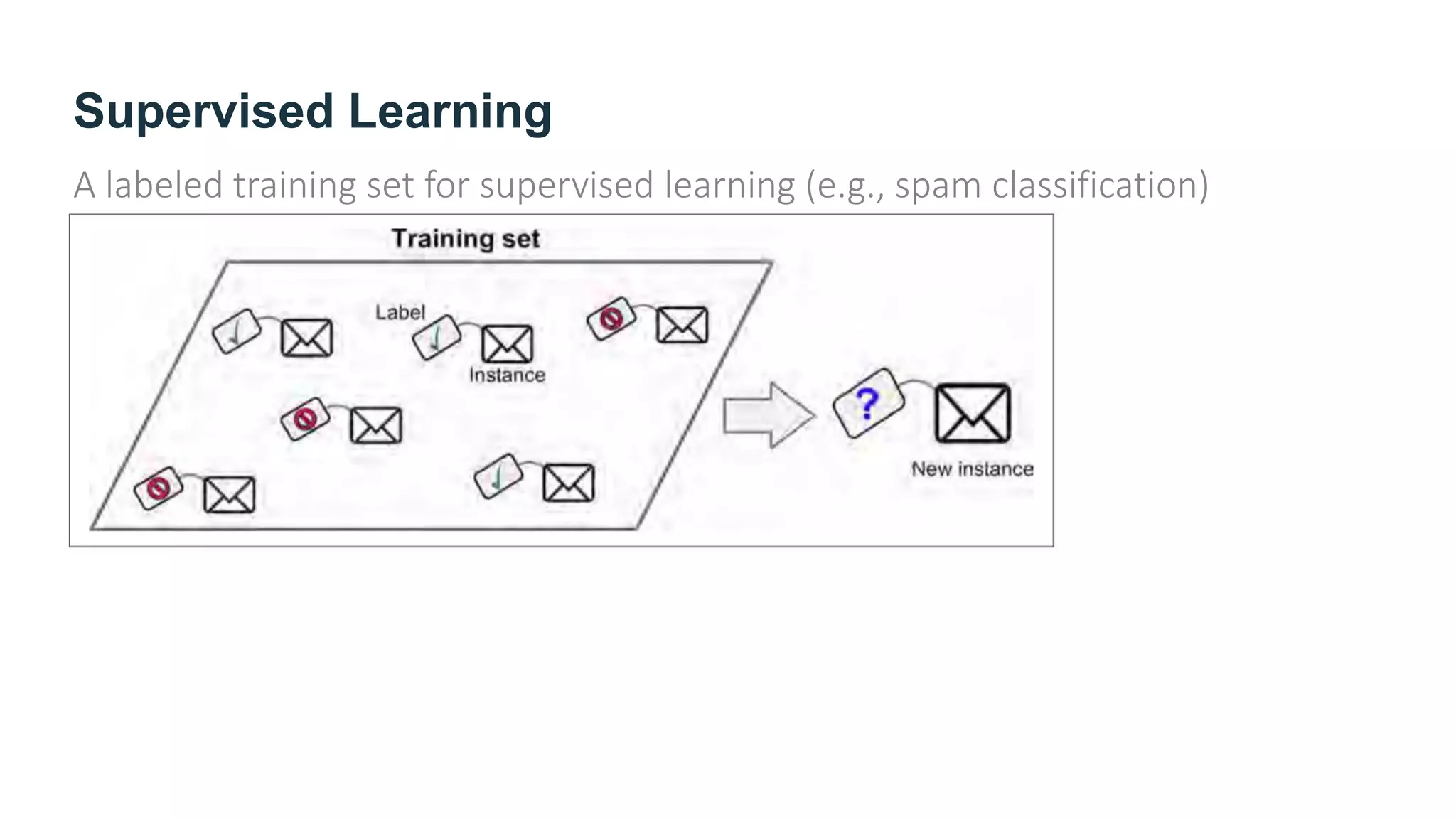




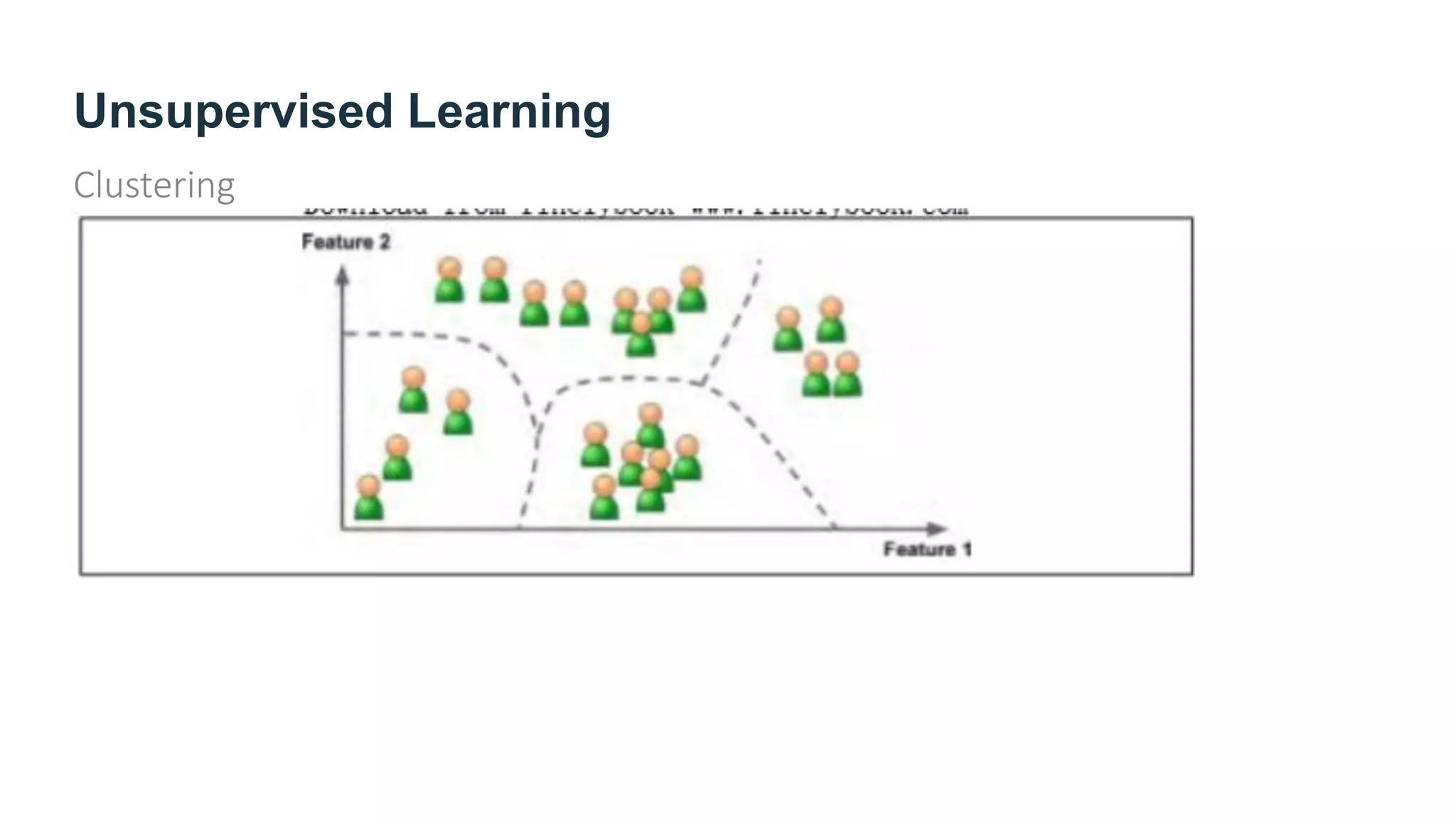

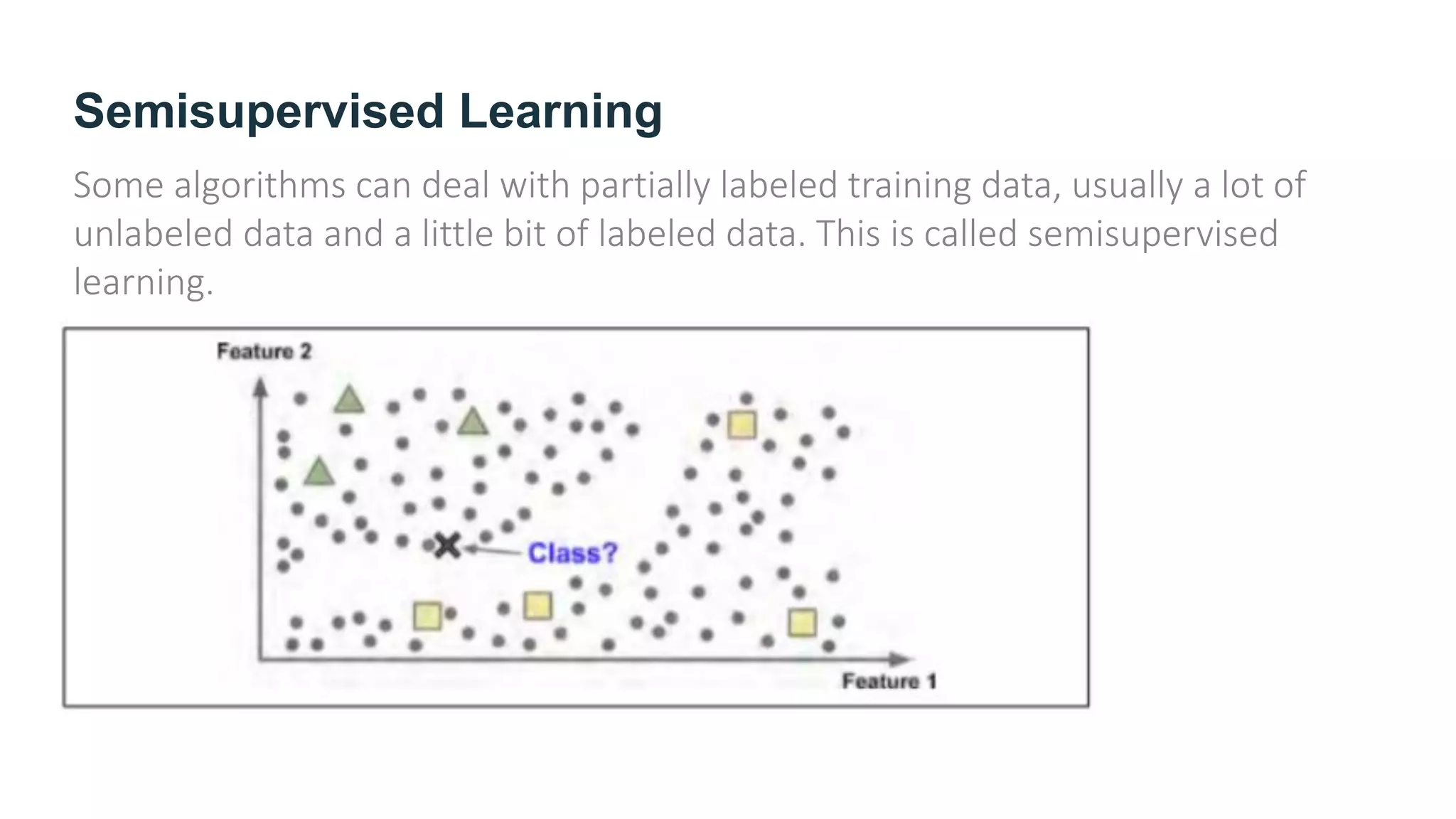







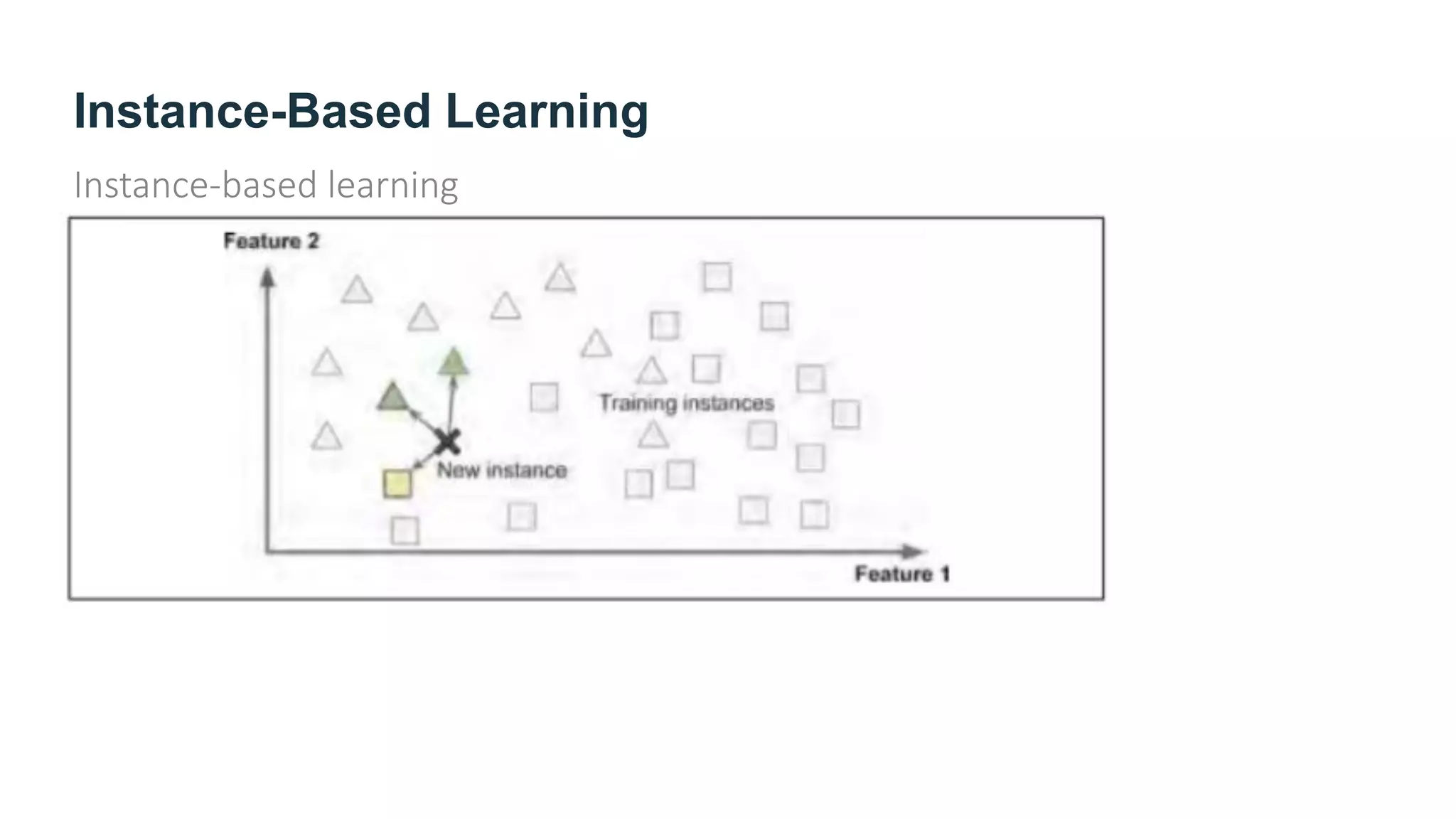
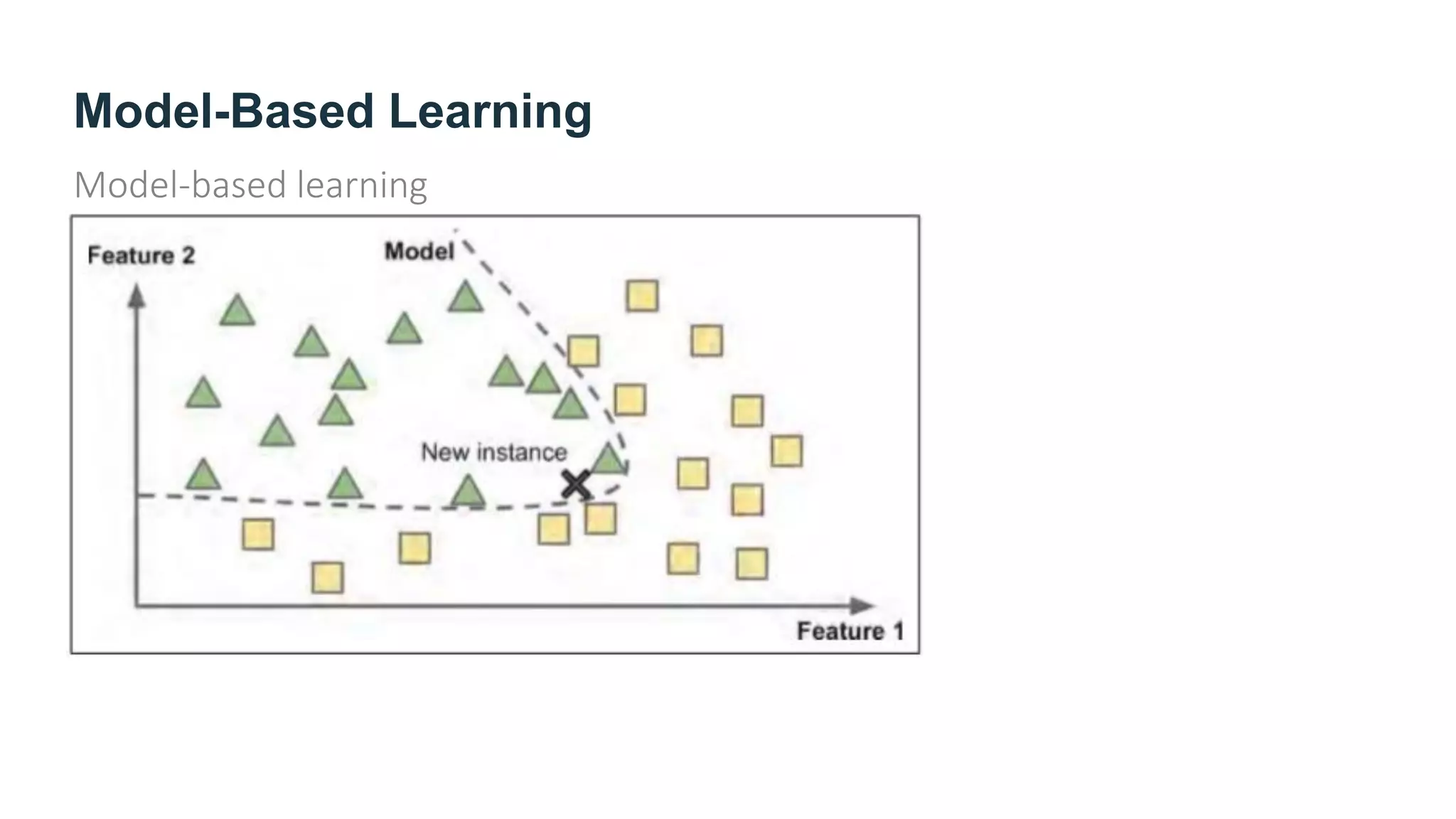





The document provides an overview of machine learning, explaining its definition, importance, and various types, including supervised, unsupervised, semi-supervised, and reinforcement learning. It highlights the advantages of machine learning over traditional programming in solving complex problems and adapting to changes. Additionally, it addresses the challenges in selecting algorithms and dealing with data quality, emphasizing the significance of good data and appropriate techniques.




































![1_Introduction to Machine Learning [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/1introductiontomachinelearningautosaved-250910004933-3913b711-thumbnail.jpg?width=640&height=640&fit=bounds)

















































