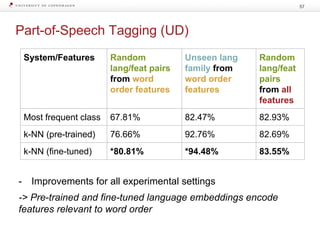
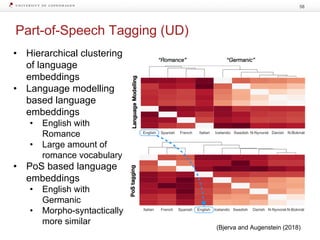
Download as PDF, PPTX









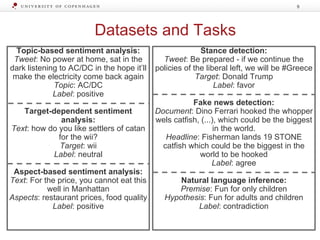
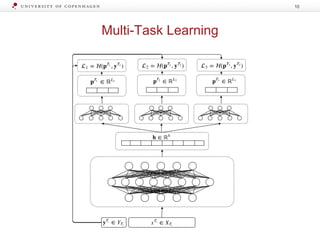
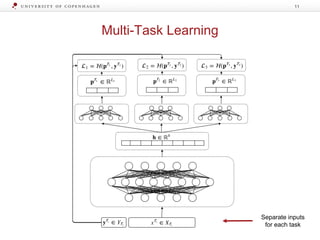
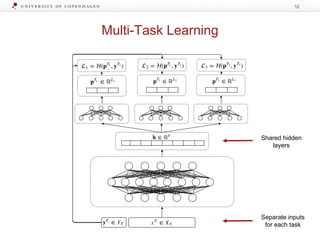
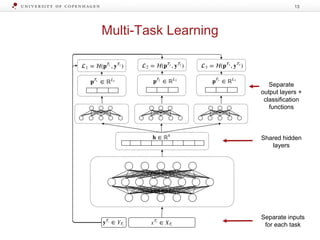
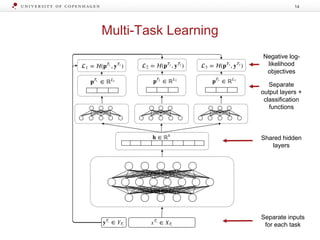



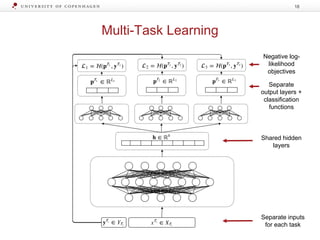
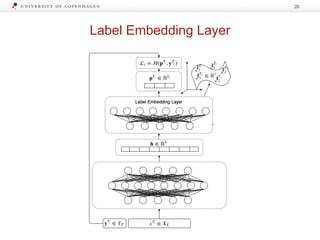
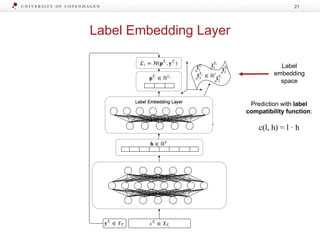
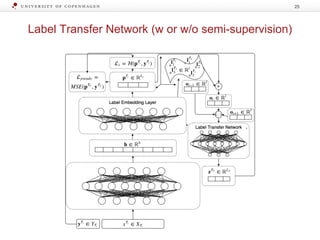
![Label Transfer Network
Goal: learn to produce pseudo labels for target task
LTNT = MLP([o1, …, oT-1])
Li
oi = ∑ pj
Ti lj
j=1
- Output label embedding oi of task Ti: sum of the task’s
label embeddings lj weighted with their probability pj
Ti
- LTN: trained on labelled target task data
- Trained with a negative log-likelihood objective LLTN to
produce a pseudo-label for the target task
23](https://image.slidesharecdn.com/lld-jhusmall-180530224718/85/Learning-with-limited-labelled-data-in-NLP-multi-task-learning-and-beyond-23-320.jpg)

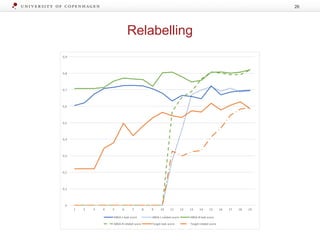
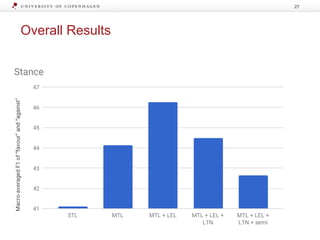
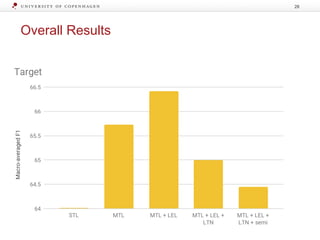
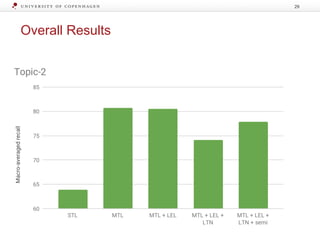
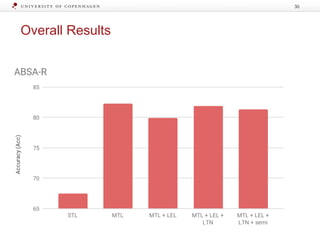
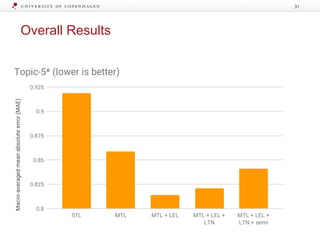





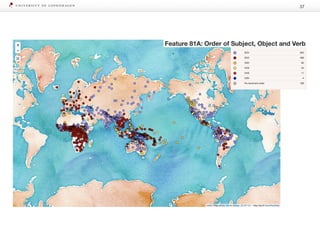
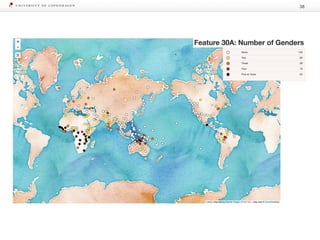



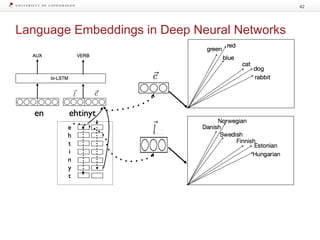
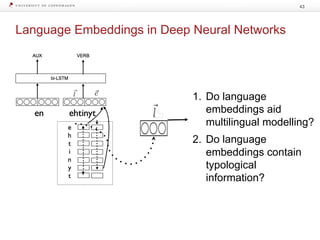


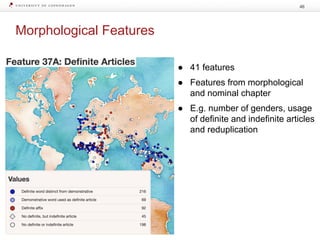

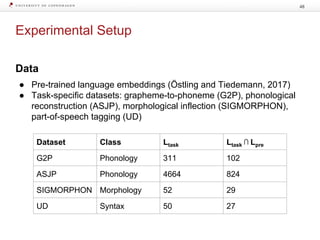









The document discusses strategies for learning with limited labeled data in natural language processing, focusing on multi-task and semi-supervised learning approaches. It highlights methods like domain adaptation, weakly supervised learning, and transfer learning, addressing challenges faced in multilingual contexts and underrepresented languages. The research includes applications in stance detection, sentiment analysis, and the use of computational typology to enhance language representations and understanding of typological features.


















































































