Download to read offline

![In the next section we present the various sources length of the hypothesis was typically much shorter
of the STS data and the annotation procedure used. than the text, and we did not want to bias the STS
Section 4 investigates the evaluation of STS sys- task in this respect. We may, however, explore using
tems. Section 5 summarizes the resources and tools TE pairs for STS in the future.
used by participant systems. Finally, Section 6 Microsoft Research (MSR) has pioneered the ac-
draws the conclusions. quisition of paraphrases with two manually anno-
tated datasets. The first, called MSR Paraphrase
2 Source Datasets (MSRpar for short) has been widely used to evaluate
Datasets for STS are scarce. Existing datasets in- text similarity algorithms. It contains 5801 pairs of
clude (Li et al., 2006) and (Lee et al., 2005). The sentences gleaned over a period of 18 months from
first dataset includes 65 sentence pairs which cor- thousands of news sources on the web (Dolan et
respond to the dictionary definitions for the 65 al., 2004). 67% of the pairs were tagged as para-
word pairs in Similarity(Rubenstein and Goode- phrases. The inter annotator agreement is between
nough, 1965). The authors asked human informants 82% and 84%. Complete meaning equivalence is
to assess the meaning of the sentence pairs on a not required, and the annotation guidelines allowed
scale from 0.0 (minimum similarity) to 4.0 (maxi- for some relaxation. The pairs which were anno-
mum similarity). While the dataset is very relevant tated as not being paraphrases ranged from com-
to STS, it is too small to train, develop and test typ- pletely unrelated semantically, to partially overlap-
ical machine learning based systems. The second ping, to those that were almost-but-not-quite seman-
dataset comprises 50 documents on news, ranging tically equivalent. In this sense our graded annota-
from 51 to 126 words. Subjects were asked to judge tions enrich the dataset with more nuanced tags, as
the similarity of document pairs on a five-point scale we will see in the following section. We followed
(with 1.0 indicating “highly unrelated” and 5.0 indi- the original split of 70% for training and 30% for
cating “highly related”). This second dataset com- testing. A sample pair from the dataset follows:
prises a larger number of document pairs, but it goes
The Senate Select Committee on Intelligence
beyond sentence similarity into textual similarity. is preparing a blistering report on prewar
When constructing our datasets, gathering natu- intelligence on Iraq.
rally occurring pairs of sentences with different de-
grees of semantic equivalence was a challenge in it- American intelligence leading up to the
self. If we took pairs of sentences at random, the war on Iraq will be criticized by a powerful
vast majority of them would be totally unrelated, and US Congressional committee due to report
soon, officials said today.
only a very small fragment would show some sort of
semantic equivalence. Accordingly, we investigated
In order to construct a dataset which would reflect
reusing a collection of existing datasets from tasks
a uniform distribution of similarity ranges, we sam-
that are related to STS.
pled the MSRpar dataset at certain ranks of string
We first studied the pairs of text from the Recog-
similarity. We used the implementation readily ac-
nizing TE challenge. The first editions of the chal-
cessible at CPAN1 of a well-known metric (Ukko-
lenge included pairs of sentences as the following:
nen, 1985). We sampled equal numbers of pairs
T: The Christian Science Monitor named a US from five bands of similarity in the [0.4 .. 0.8] range
journalist kidnapped in Iraq as freelancer Jill separately from the paraphrase and non-paraphrase
Carroll. pairs. We sampled 1500 pairs overall, which we split
H: Jill Carroll was abducted in Iraq. 50% for training and 50% for testing.
The first sentence is the text, and the second is The second dataset from MSR is the MSR Video
the hypothesis. The organizers of the challenge an- Paraphrase Corpus (MSRvid for short). The authors
notated several pairs with a binary tag, indicating showed brief video segments to Annotators from
whether the hypothesis could be entailed from the Amazon Mechanical Turk (AMT) and were asked
text. Although these pairs of text are interesting we 1
http://search.cpan.org/˜mlehmann/
decided to discard them from this pilot because the String-Similarity-1.04/Similarity.pm
386](https://image.slidesharecdn.com/s12-1051-130408033808-phpapp01/75/SemEval-2012-Task-6-A-Pilot-on-Semantic-Textual-Similarity-2-2048.jpg)
![Given the strong connection between STS sys-
tems and Machine Translation evaluation metrics,
we also sampled pairs of segments that had been
part of human evaluation exercises. Those pairs in-
cluded a reference translation and a automatic Ma-
chine Translation system submission, as follows:
The only instance in which no tax is levied is
when the supplier is in a non-EU country and
the recipient is in a Member State of the EU.
Figure 1: Video and corresponding descriptions from
The only case for which no tax is still
MSRvid
perceived ”is an example of supply in the
European Community from a third country.
We selected pairs from the translation shared task
of the 2007 and 2008 ACL Workshops on Statistical
Machine Translation (WMT) (Callison-Burch et al.,
2007; Callison-Burch et al., 2008). For consistency,
we only used French to English system submissions.
The training data includes all of the Europarl human
ranked fr-en system submissions from WMT 2007,
with each machine translation being paired with the
Figure 2: Definition and instructions for annotation
correct reference translation. This resulted in 729
unique training pairs. The test data is comprised of
to provide a one-sentence description of the main ac- all Europarl human evaluated fr-en pairs from WMT
tion or event in the video (Chen and Dolan, 2011). 2008 that contain 16 white space delimited tokens or
Nearly 120 thousand sentences were collected for less.
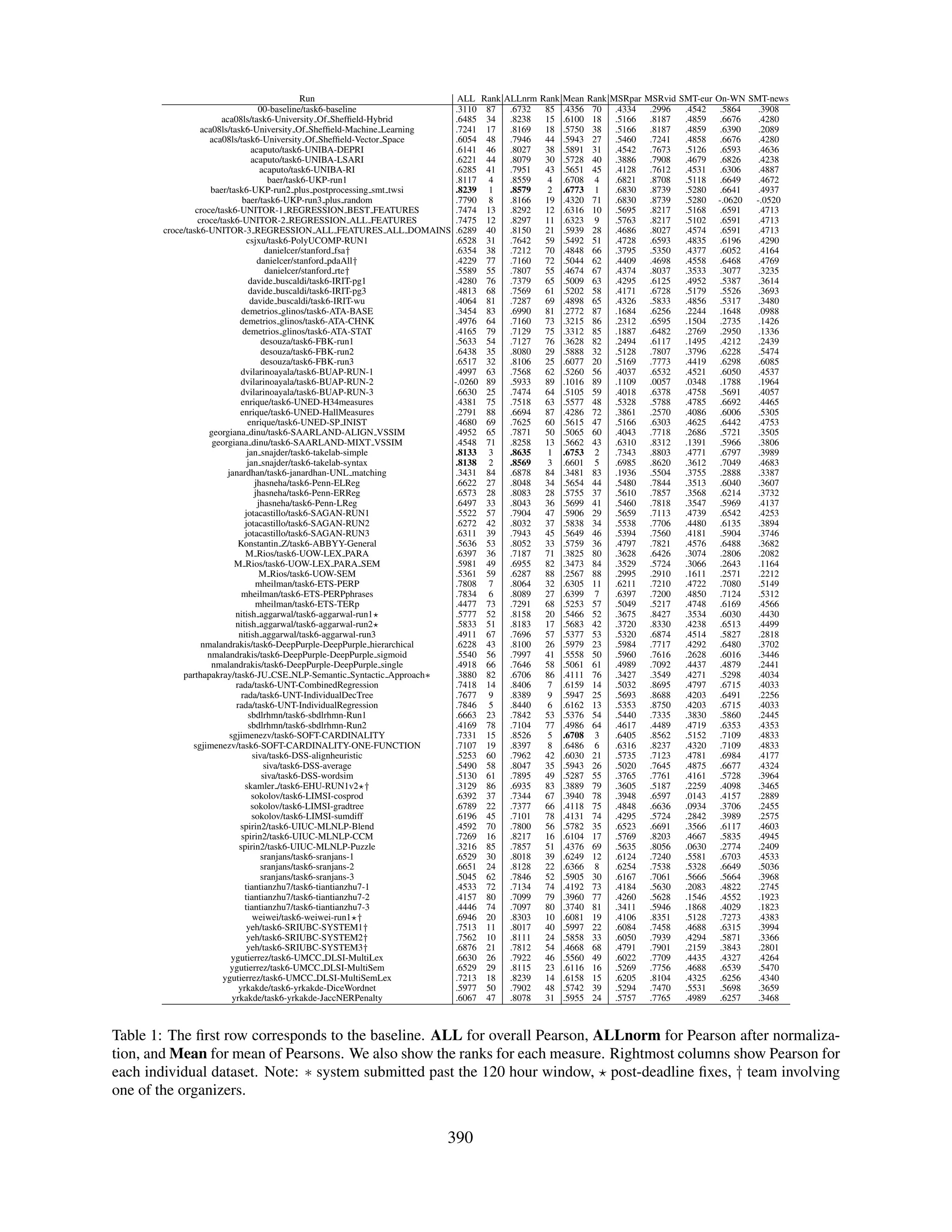
2000 videos. The sentences can be taken to be In addition, we selected two other datasets that
roughly parallel descriptions, and they included sen- were used as out-of-domain testing. One of them
tences for many languages. Figure 1 shows a video comprised of all the human ranked fr-en system
and corresponding descriptions. submissions from the WMT 2007 news conversa-
tion test set, resulting in 351 unique system refer-
The sampling procedure from this dataset is sim-
ence pairs.2 The second set is radically different as
ilar to that for MSRpar. We construct two bags of
it comprised 750 pairs of glosses from OntoNotes
data to draw samples. The first includes all possible
4.0 (Hovy et al., 2006) and WordNet 3.1 (Fellbaum,
pairs for the same video, and the second includes
1998) senses. The mapping of the senses of both re-
pairs taken from different videos. Note that not all
sources comprised 110K sense pairs. The similarity
sentences from the same video were equivalent, as
between the sense pairs was generated using simple
some descriptions were contradictory or unrelated.
word overlap. 50% of the pairs were sampled from
Conversely, not all sentences coming from different
senses which were deemed as equivalent senses, the
videos were necessarily unrelated, as many videos
rest from senses which did not map to one another.
were on similar topics. We took an equal number of
samples from each of these two sets, in an attempt to 3 Annotation
provide a balanced dataset between equivalent and
non-equivalent pairs. The sampling was also done In this first dataset we defined a straightforward lik-
according to string similarity, but in four bands in the ert scale ranging from 5 to 0, but we decided to pro-
[0.5 .. 0.8] range, as sentences from the same video vide definitions for each value in the scale (cf. Fig-
had a usually higher string similarity than those in ure 2). We first did pilot annotations of 200 pairs se-
the MSRpar dataset. We sampled 1500 pairs overall, 2
At the time of the shared task, this data set contained dupli-
which we split 50% for training and 50% for testing. cates resulting in 399 sentence pairs.
387](https://image.slidesharecdn.com/s12-1051-130408033808-phpapp01/75/SemEval-2012-Task-6-A-Pilot-on-Semantic-Textual-Similarity-3-2048.jpg)

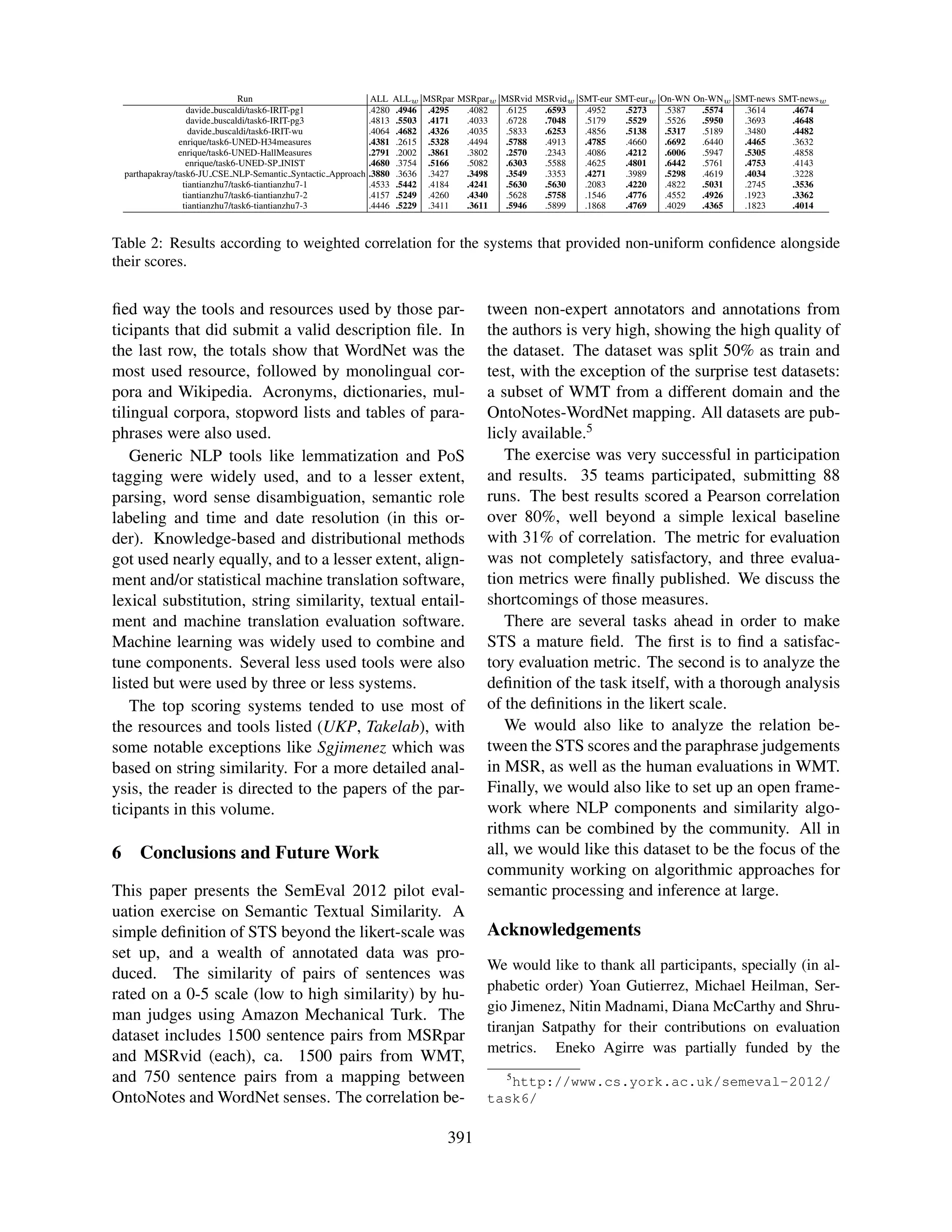
![scores3 . Table 2 includes the list of systems which the 110K OntoNotes-WordNet dataset from which
provided a non-uniform confidence. The results the other organizers sampled the surprise data set.
show that some systems were able to improve their After the submission deadline expired, the orga-
correlation, showing promise for the usefulness of nizers published the gold standard in the task web-
confidence in applications. site, in order to ensure a transparent evaluation pro-
cess.
4.3 The Baseline System
We produced scores using a simple word overlap 4.5 Results
baseline system. We tokenized the input sentences Table 1 shows the results for each run in alphabetic
splitting at white spaces, and then represented each order. Each result is followed by the rank of the sys-
sentence as a vector in the multidimensional to- tem according to the given evaluation measure. To
ken space. Each dimension had 1 if the token was the right, the Pearson score for each dataset is given.
present in the sentence, 0 otherwise. Similarity of In boldface, the three best results in each column.
vectors was computed using cosine similarity. First of all we want to stress that the large majority
We also run a random baseline several times, of the systems are well above the simple baseline,
yielding close to 0 correlations in all datasets, as ex- although the baseline would rank 70 on the Mean
pected. We will refer to the random baseline again measure, improving over 19 runs.
in Section 4.5. The correlation for the non-MT datasets were re-
ally high: the highest correlation was obtained was
4.4 Participation
for MSRvid (0.88 r), followed by MSRpar (0.73 r)
Participants could send a maximum of three system and On-WN (0.73 r). The results for the MT evalu-
runs. After downloading the test datasets, they had ation data are lower, (0.57 r) for SMT-eur and (0.61
a maximum of 120 hours to upload the results. 35 r) for SMT-News. The simple token overlap base-
teams participated, submitting 88 system runs (cf. line, on the contrary, obtained the highest results
first column of Table 1). Due to lack of space we for On-WN (0.59 r), with (0.43 r) on MSRpar and
can’t detail the full names of authors and institutions (0.40 r) on MSRvid. The results for MT evaluation
that participated. The interested reader can use the data are also reversed, with (0.40 r) for SMT-eur and
name of the runs to find the relevant paper in these (0.45 r) for SMT-News.
proceedings. The ALLnorm measure yields the highest corre-
There were several issues in the submissions. The lations. This comes at no surprise, as it involves a
submission software did not ensure that the nam- normalization which transforms the system outputs
ing conventions were appropriately used, and this using the gold standard. In fact, a random base-
caused some submissions to be missed, and in two line which gets Pearson correlations close to 0 in all
cases the results were wrongly assigned. Some par- datasets would attain Pearson of 0.58914 .
ticipants returned Not-a-Number as a score, and the Although not included in the results table for lack
organizers had to request whether those where to be of space, we also performed an analysis of confi-
taken as a 0 or as a 5. dence intervals. For instance, the best run according
Finally, one team submitted past the 120 hour to ALL (r = .8239) has a 95% confidence interval of
deadline and some teams sent missing files after the [.8123,.8349] and the second a confidence interval
deadline. All those are explicitly marked in Table 1. of [.8016,.8254], meaning that the differences are
The teams that included one of the organizers are not statistically different.
also explicitly marked. We want to stress that in
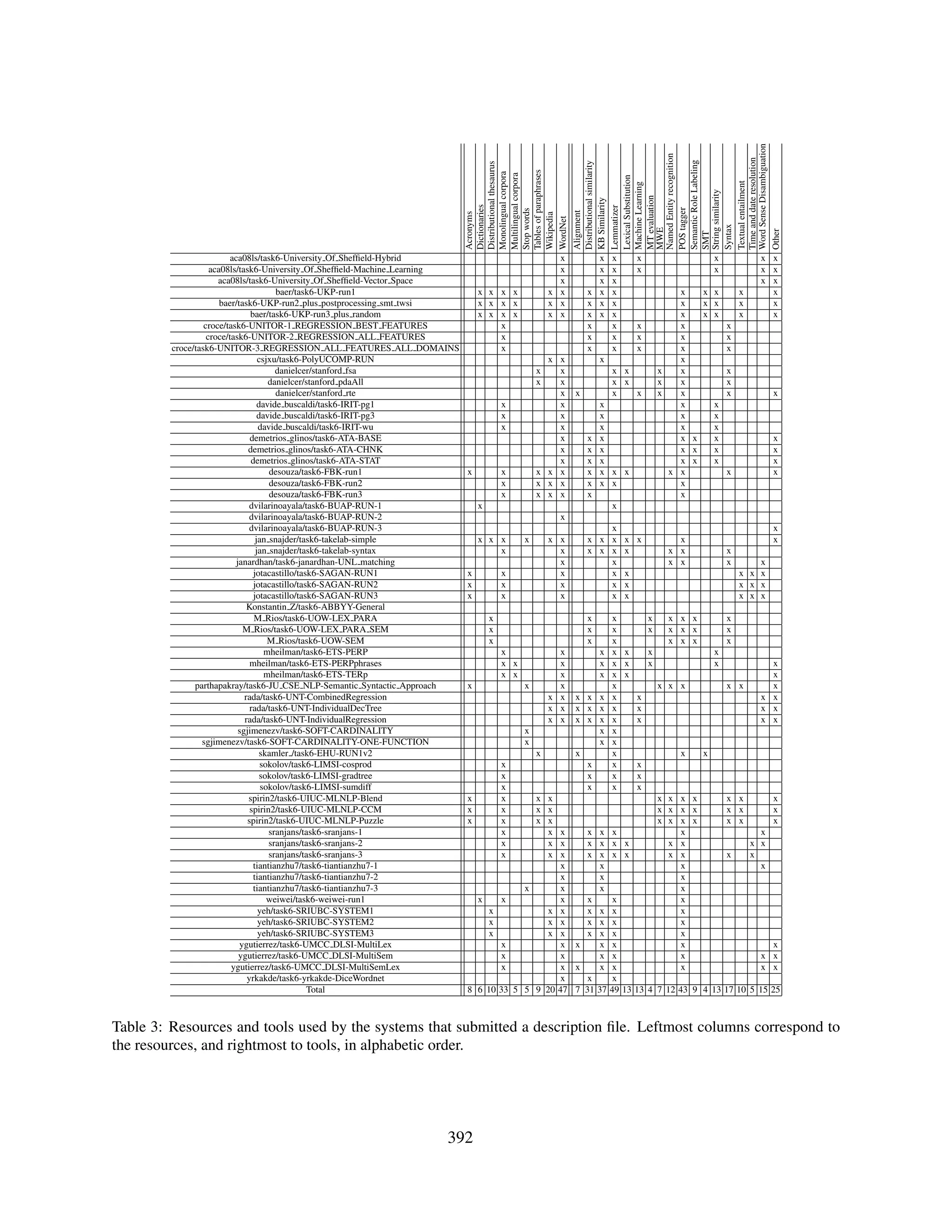
these teams the organizers did not allow the devel- 5 Tools and resources used
opers of the system to access any data or informa-
tion which was not available for the rest of partic- The organizers asked participants to submit a de-
ipants. One exception is weiwei, as they generated scription file, special emphasis on the tools and re-
sources that they used. Table 3 shows in a simpli-
3
http://en.wikipedia.org/wiki/Pearson_
4
product-moment_correlation_coefficient# We run the random baseline 10 times. The mean is reported
Calculating_a_weighted_correlation here. The standard deviation is 0.0005
389](https://image.slidesharecdn.com/s12-1051-130408033808-phpapp01/75/SemEval-2012-Task-6-A-Pilot-on-Semantic-Textual-Similarity-5-2048.jpg)


This document describes the SemEval-2012 Task 6 on semantic textual similarity. The task involved measuring the semantic equivalence of sentence pairs on a scale from 0 to 5. The training data consisted of 2000 sentence pairs from existing paraphrase and machine translation datasets. The test data also had 2000 sentence pairs from these datasets as well as surprise datasets. Systems were evaluated based on their Pearson correlation with human annotations. 35 teams participated and the best systems achieved a Pearson correlation over 80%. This pilot task established semantic textual similarity as an area for further exploration.



































































































