Downloaded 53 times













![Pattern Exploiting Training (Schick et al. 2020)
Eating chocolate
causes happiness
𝐶 0.01 0.21 0.15 𝟎. 𝟔𝟑
0 1 2 3
Traditional Classifier
Eating chocolate causes
happiness. The claim
strength is [MASK]
ℳ 0.01 0.21 0.15 𝟎. 𝟔𝟑
PET
Pattern: transform the input to a
cloze-style question
Verbalizer: predict tokens from
the language model which reflect
the data’s labels
Large pretrained
language model
𝑃0
𝑃1
𝑃2
ℳ0
ℳ1
ℳ2
𝑈
𝐶
𝐷 𝑈
Soft Labels
KL-Divergence Loss
(Unlabelled)](https://image.slidesharecdn.com/2023aaai-clean-230211225242-a5340eb6/75/Beyond-Fact-Checking-Modelling-Information-Change-in-Scientific-Communication-20-2048.jpg)
![MT-PET
Eating chocolate causes
happiness. The claim strength
is [MASK]
ℳ
0.01 0.21 0.15 𝟎. 𝟔𝟑
Scientists claim eating chocolate
sometimes causes happiness.
Reporters claim eating chocolate
causes happiness. The reporters
claims are [MASK]
0.01 0.05 𝟎. 𝟗𝟒
𝑃𝑚
𝑃𝑎
𝑃𝑚
0
ℳ0
𝑈𝑚
𝐶
𝐷𝑚
𝑈𝑚
Soft Labels
KL-Divergence Loss
(Unlabelled)
𝑃𝑎
0
𝐷𝑎
𝑃𝑚
1
ℳ1
𝐷𝑚
𝑃𝑎
1
𝐷𝑎](https://image.slidesharecdn.com/2023aaai-clean-230211225242-a5340eb6/75/Beyond-Fact-Checking-Modelling-Information-Change-in-Scientific-Communication-21-2048.jpg)
![MT-PET for Exaggeration Detection
Name Pattern
𝑃𝑇1
0 Scientists claim s. Reporters claim t. The reporters claims are
[MASK]
𝑃𝑇2
0 [Scientists|Reporters] say [s |t ]. The claim strength is [MASK]
𝑃𝑇1
1 Academic literature claims s. Popular media claims t. The media
claims are [MASK]
𝑃𝑇2
1 [Academic literature|Popular media] says [s |t ]. The claim
strength is [MASK]
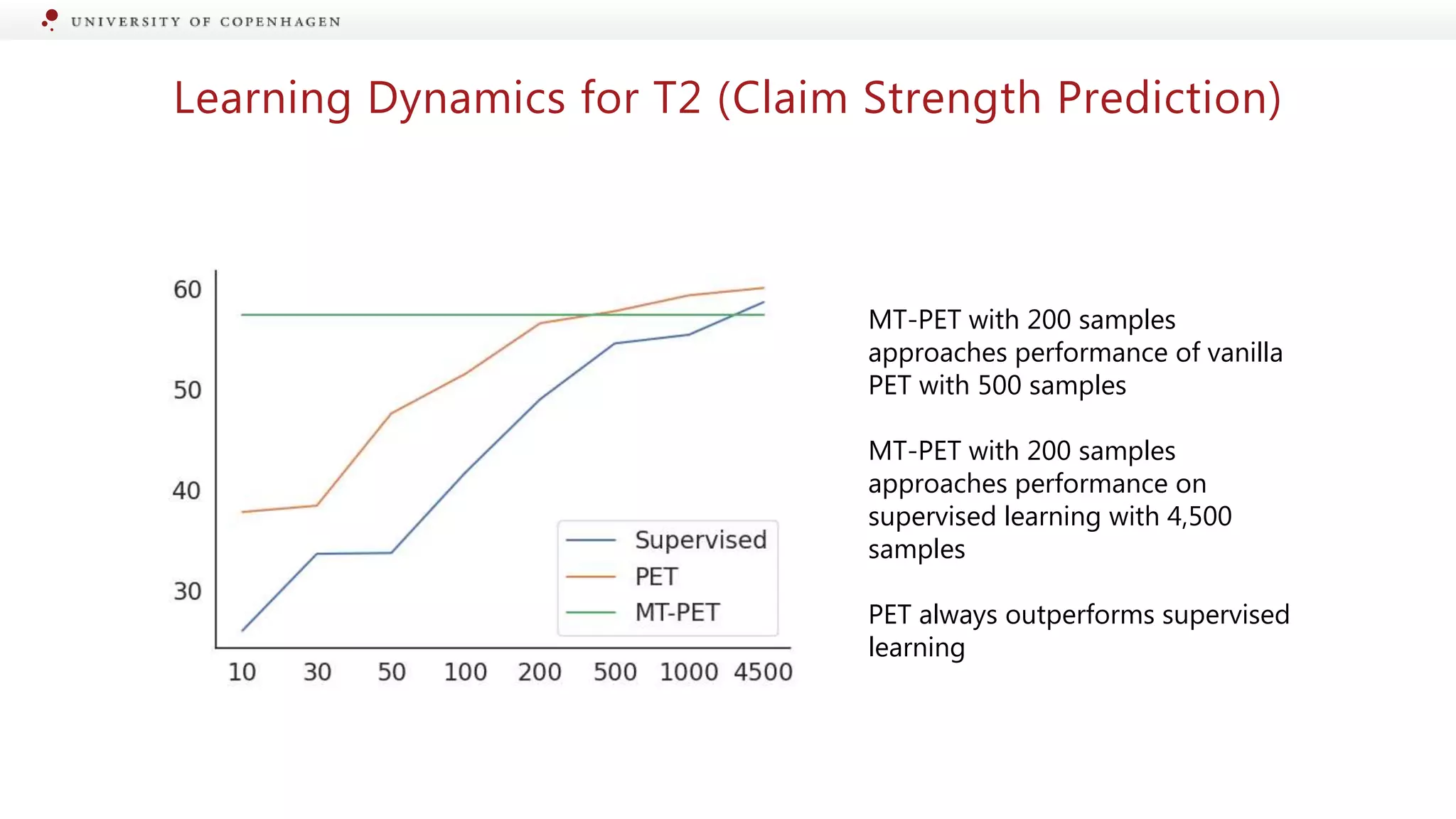
Our tasks are T1 (exaggeration prediction) and T2 (claim strength prediction)
We develop patterns by hand and verbalizers semi-automatically using PETAL (Schick et al. 2020)
s and t are the claim text in the abstract and press release, respectively](https://image.slidesharecdn.com/2023aaai-clean-230211225242-a5340eb6/75/Beyond-Fact-Checking-Modelling-Information-Change-in-Scientific-Communication-22-2048.jpg)



















The document discusses modelling information change in scientific communication. It begins by noting how science is often communicated through journalists to the public, and how the message can change and become exaggerated or misleading along the way. It then discusses developing models to detect exaggeration by predicting the strength of causal claims, such as distinguishing between correlational and causal language. Pattern exploiting training is explored as a way to leverage large language models for this task in a semi-supervised manner. Finally, it proposes generally modelling information change by comparing original research to how it is communicated elsewhere, such as in news articles and tweets, using semantic matching techniques. Experiments are discussed on newly created datasets to benchmark performance of models on this task.
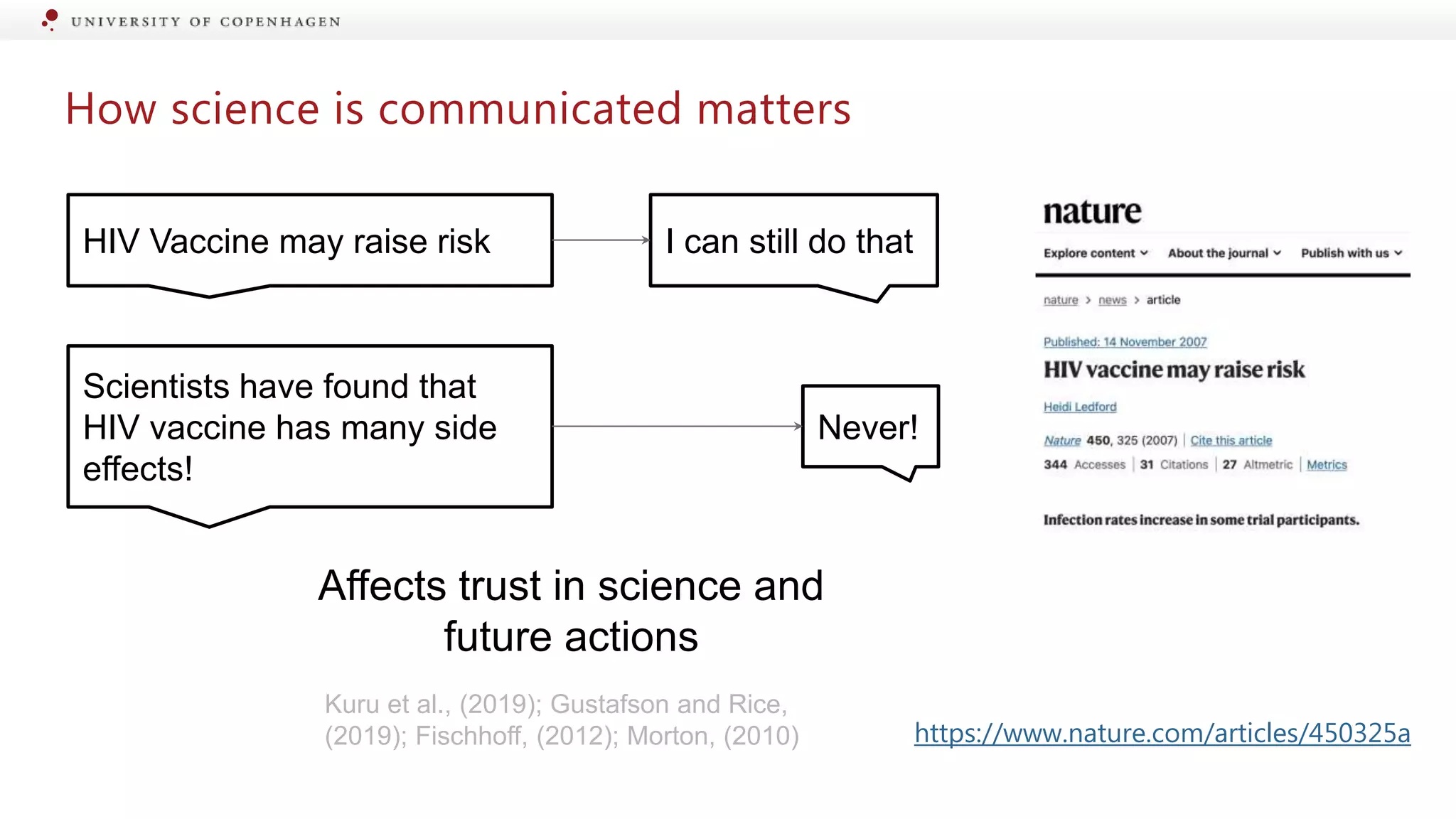
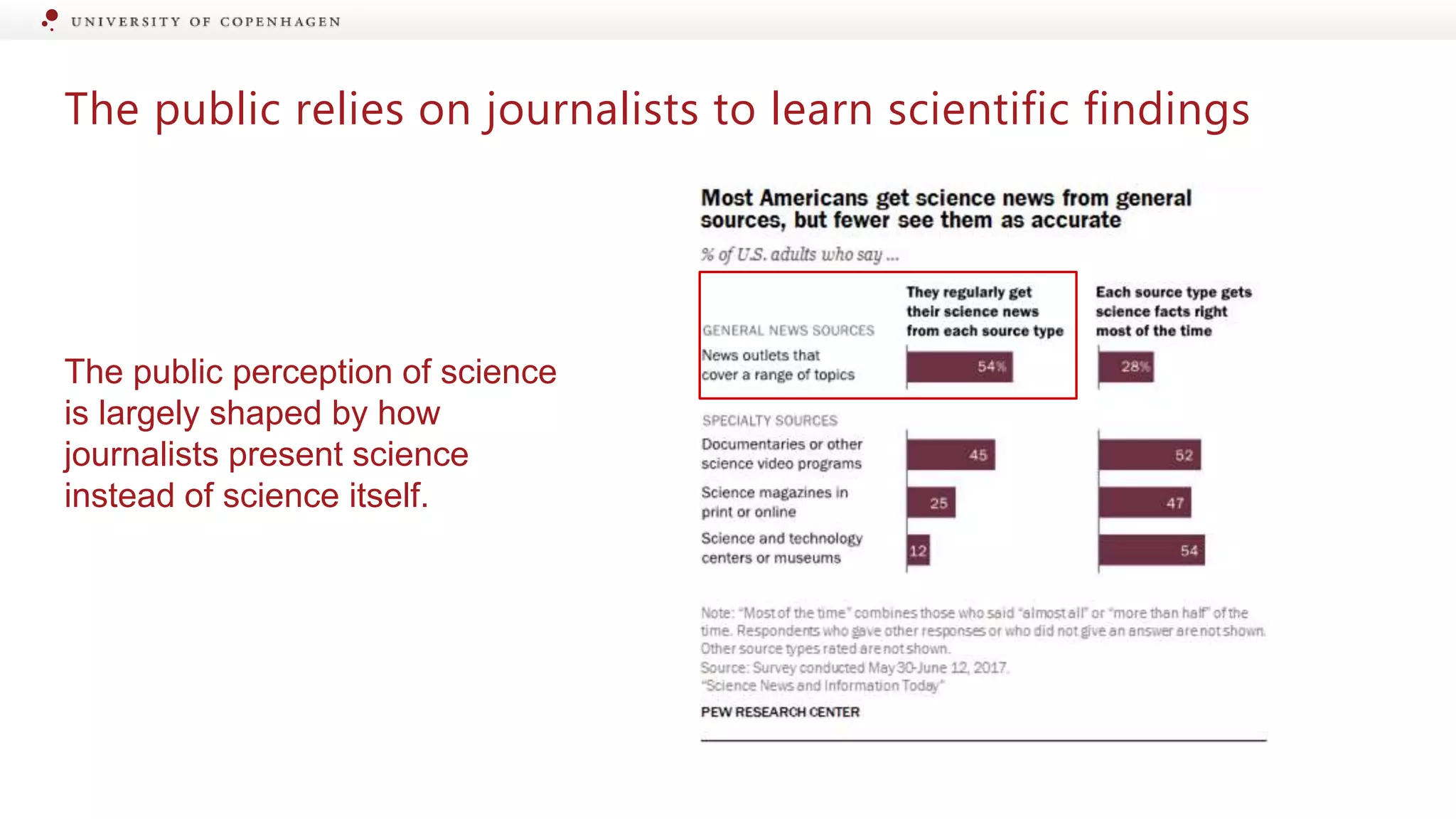
Introduction to science communication involving scientists, journalists, and the public.
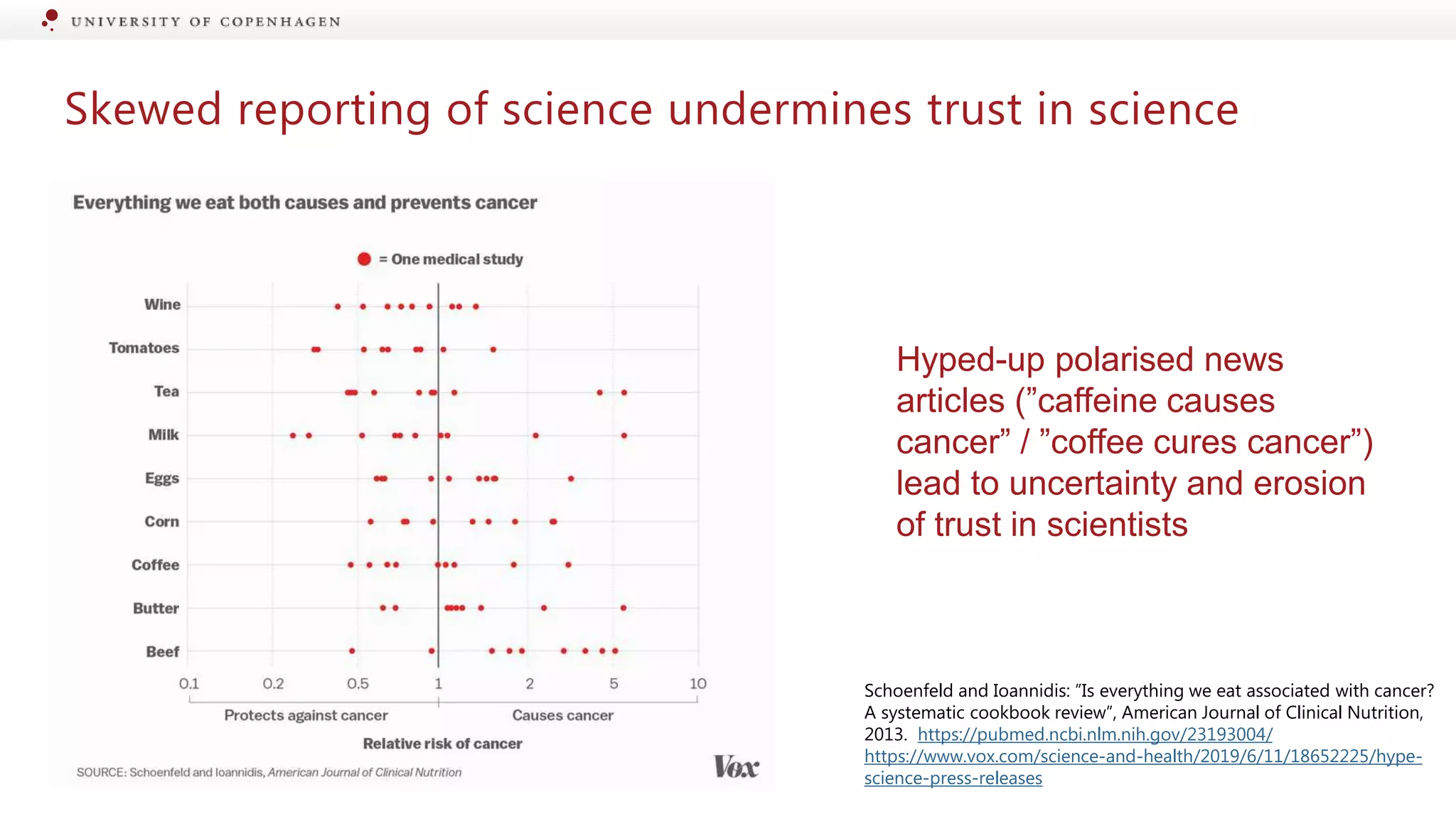
Journalistic representation shapes public perception; skewed reporting erodes trust in science.
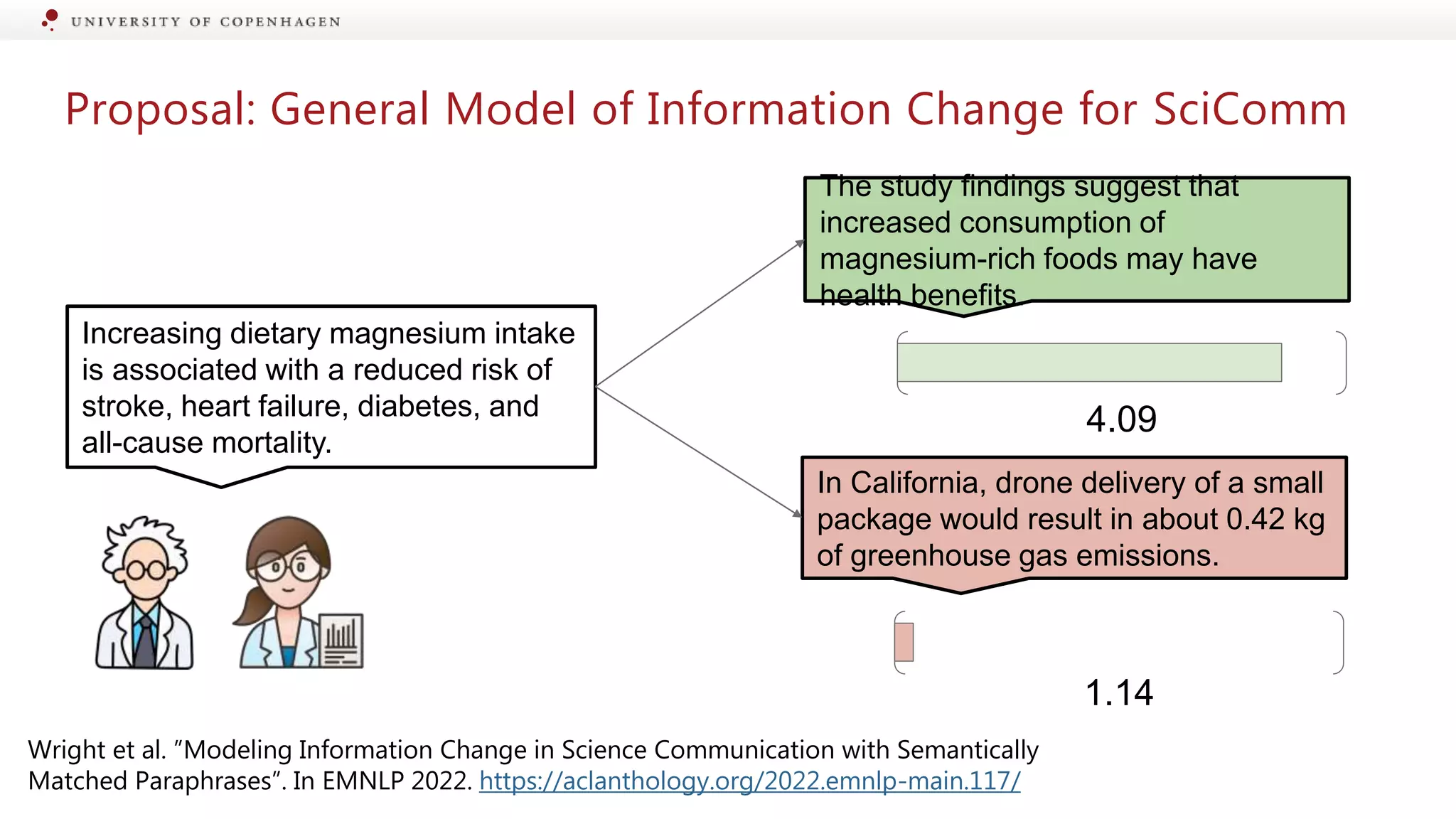
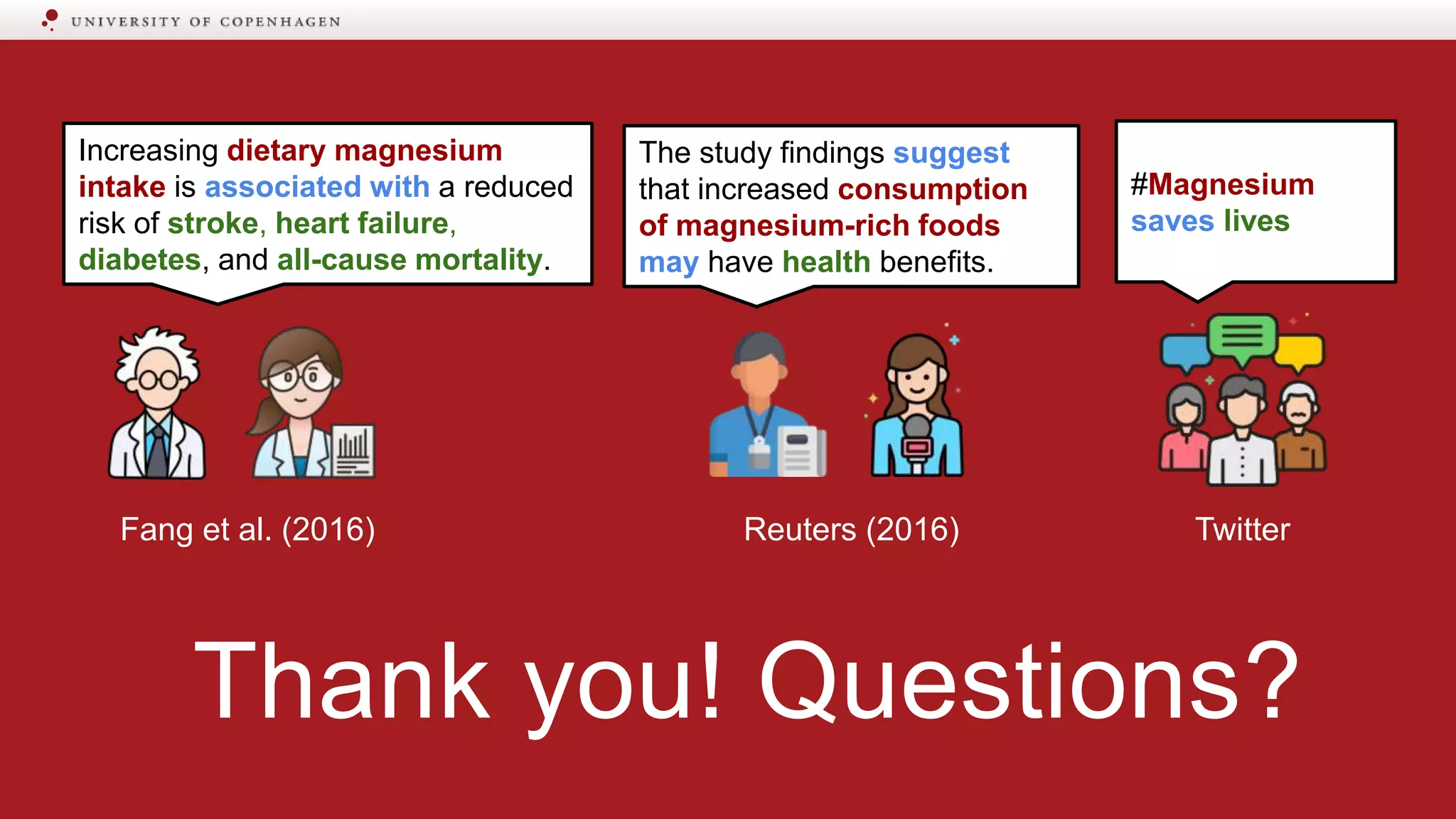
Examples of how scientific messages, like magnesium intake benefits, can be distorted in media.
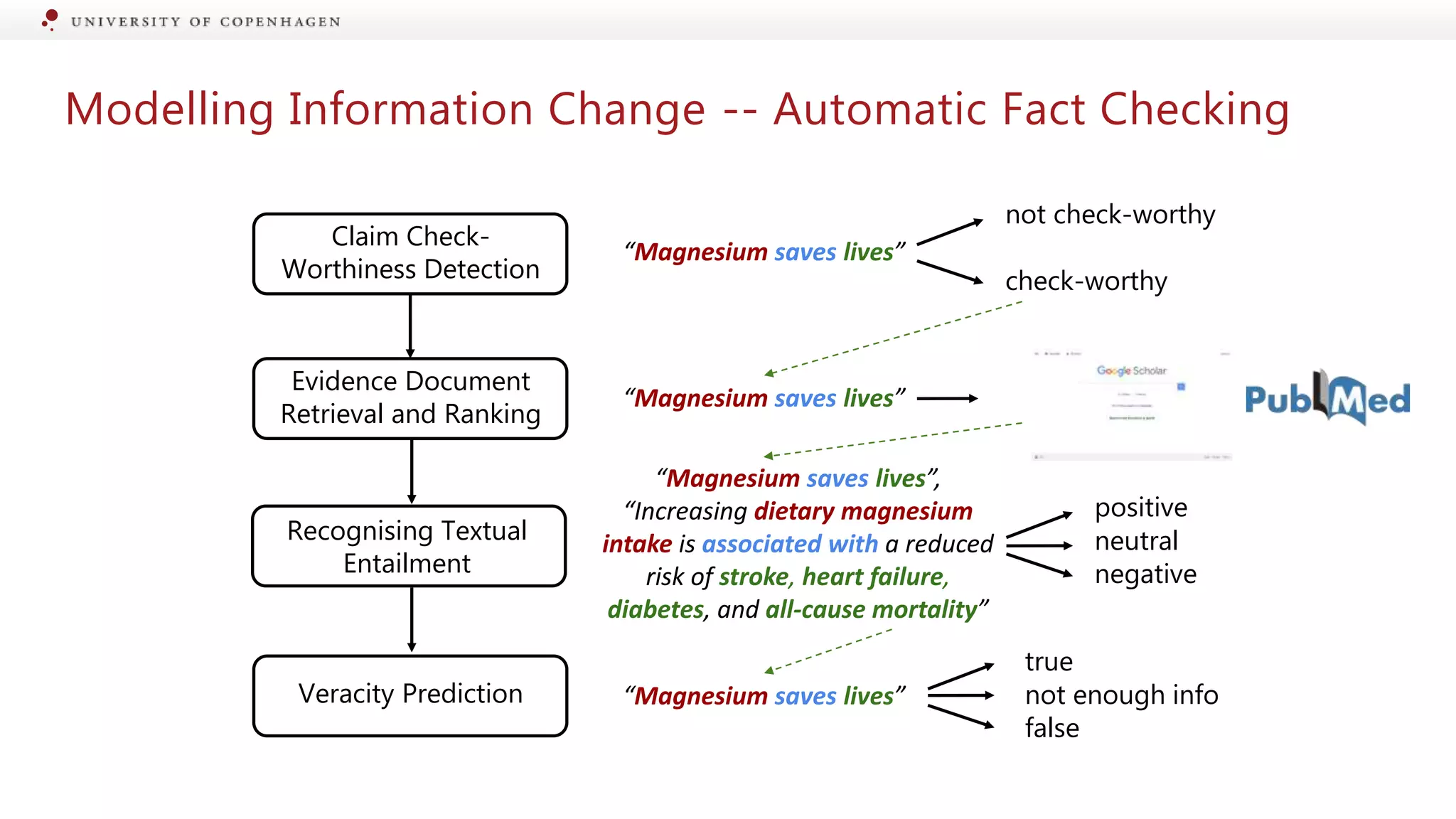
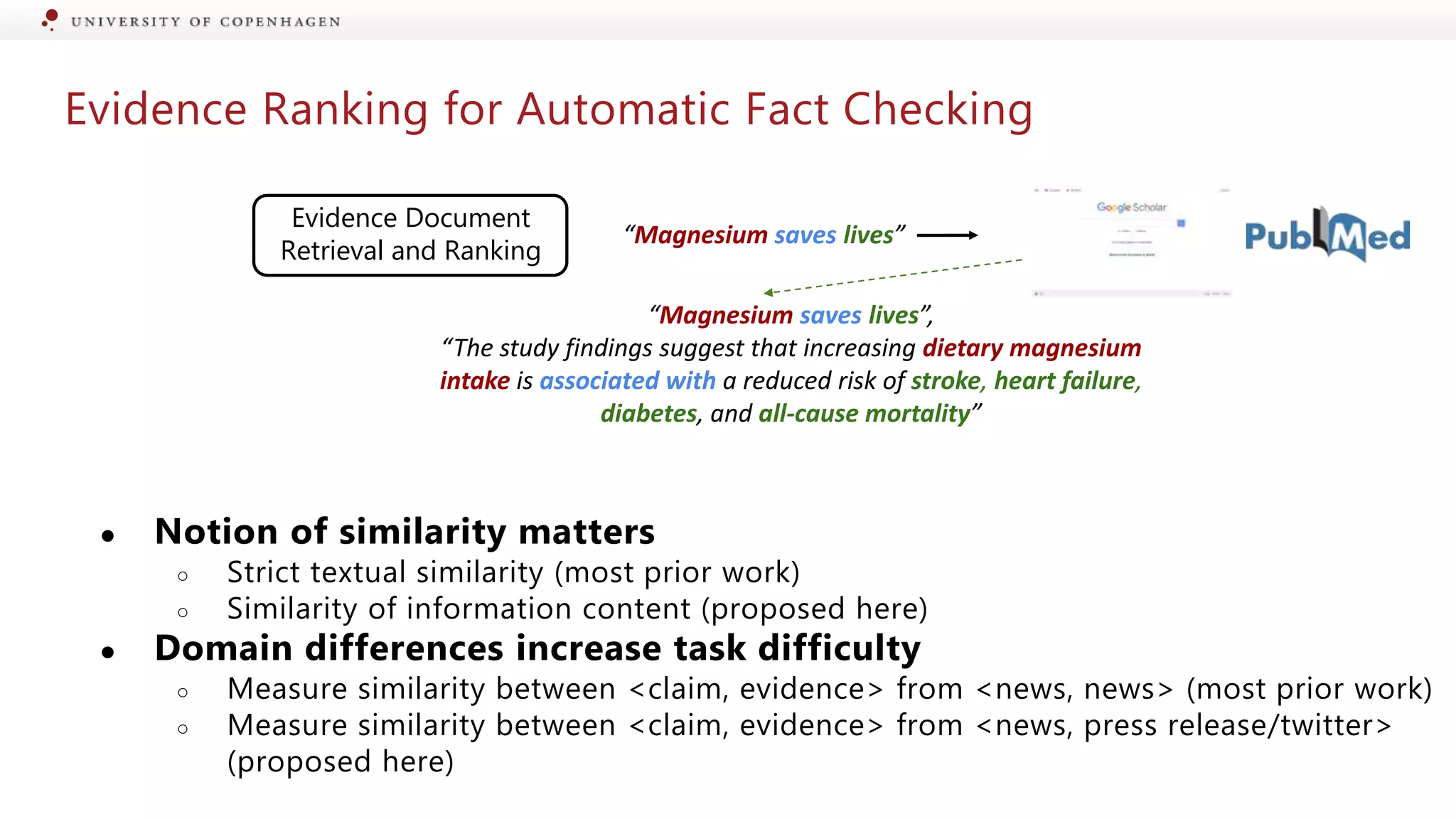
Discussion on automatic fact checking procedures and evidence ranking in verifying claims.
Overview of topics including exaggeration detection and modelling information change.
Studies show 33% of press releases exaggerate claims, impacting health-related behavior.
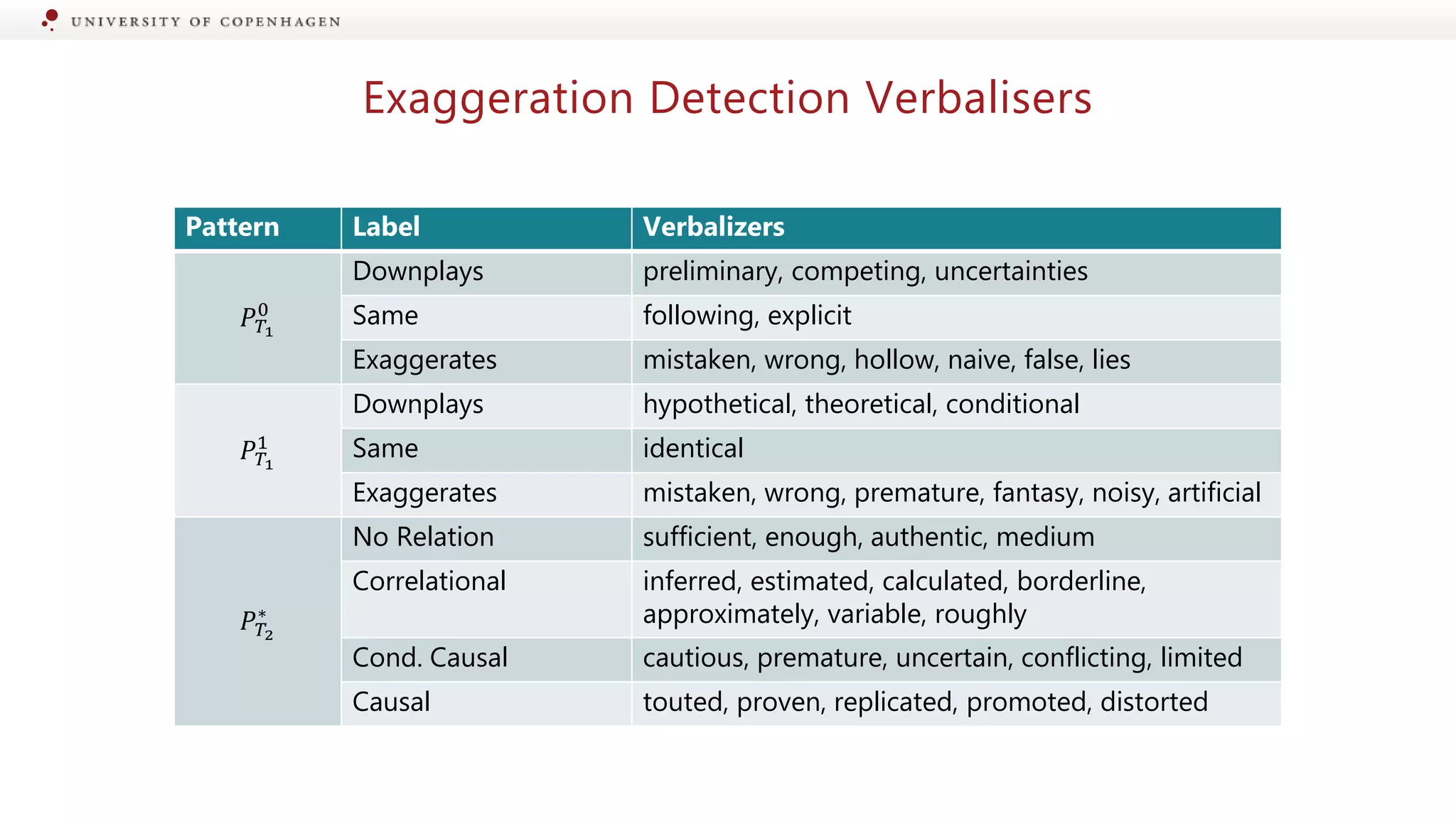
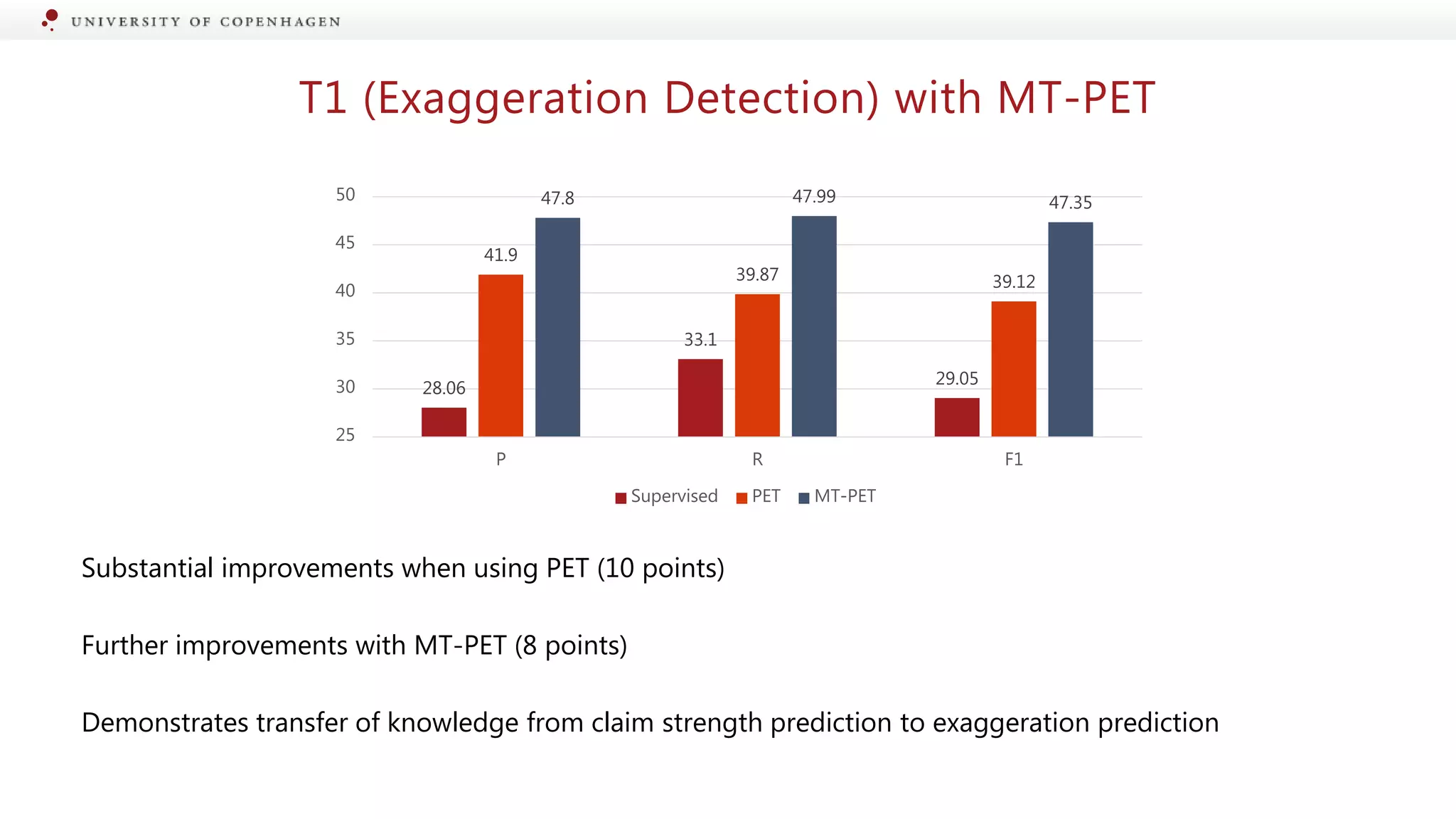
Introduction of Pattern Exploiting Training for enhancing exaggeration detection capabilities.
Showcased improvements in detection performance using machine learning techniques.
Models developed to predict how scientific findings change as they are communicated.
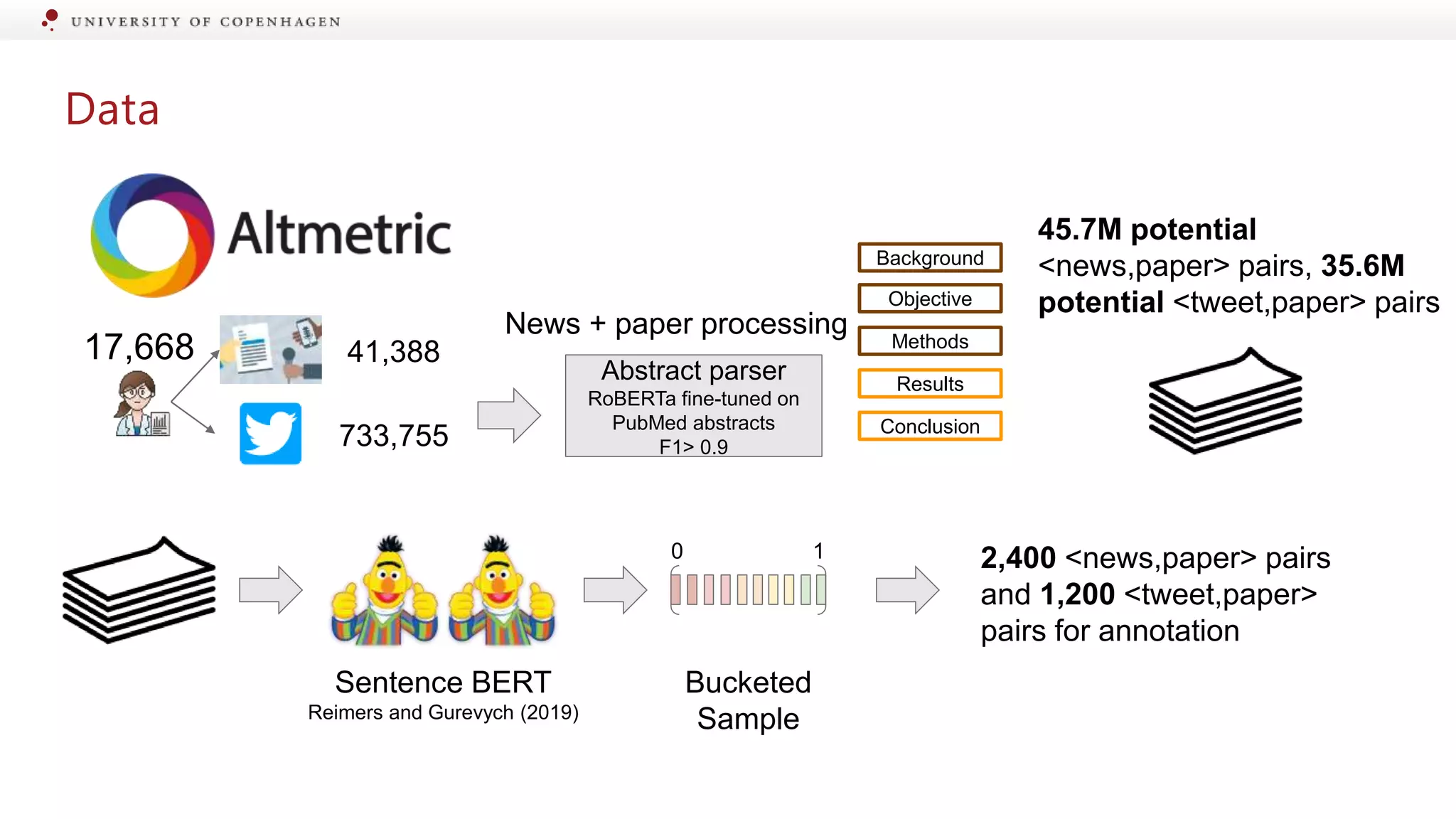
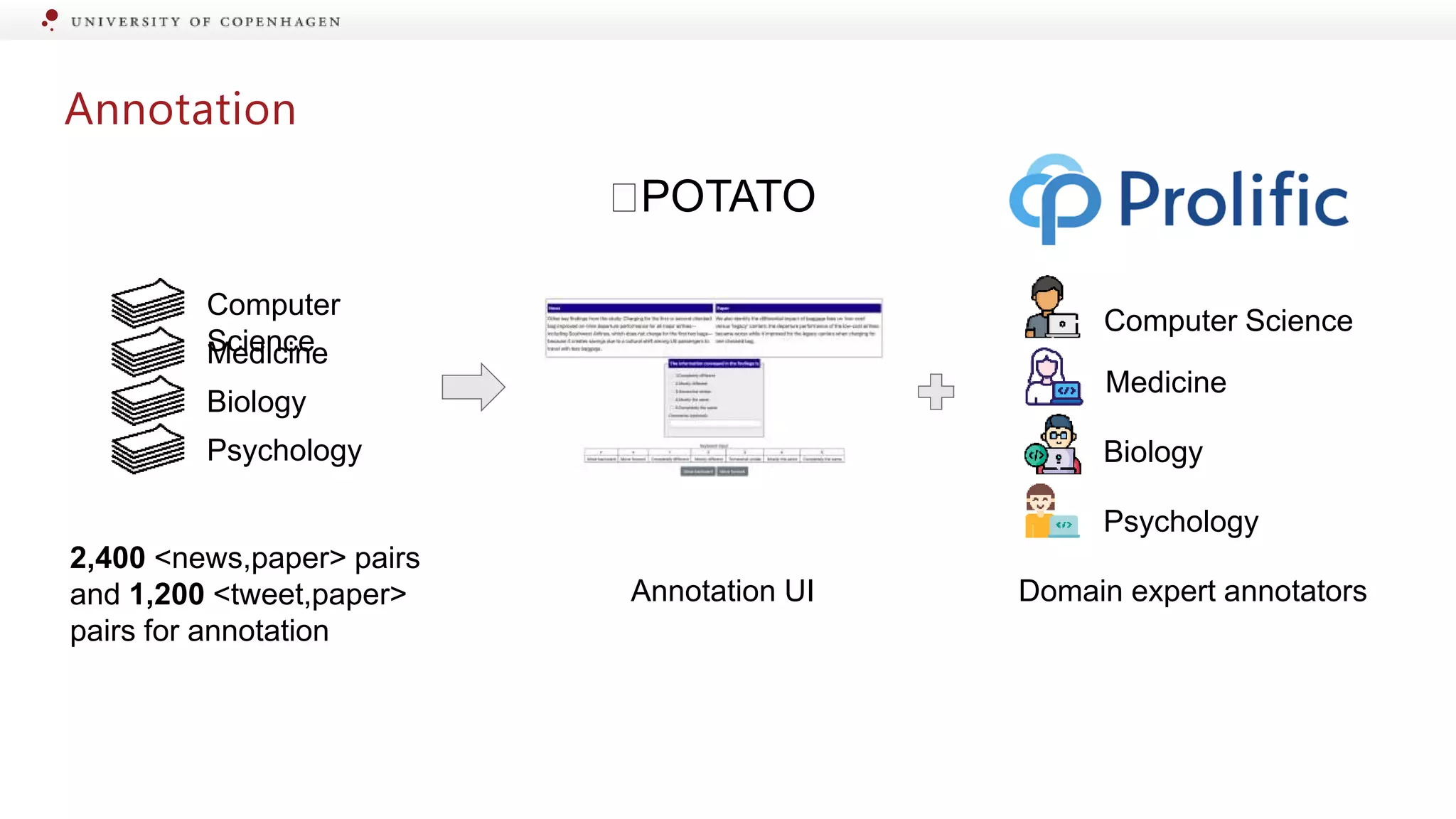
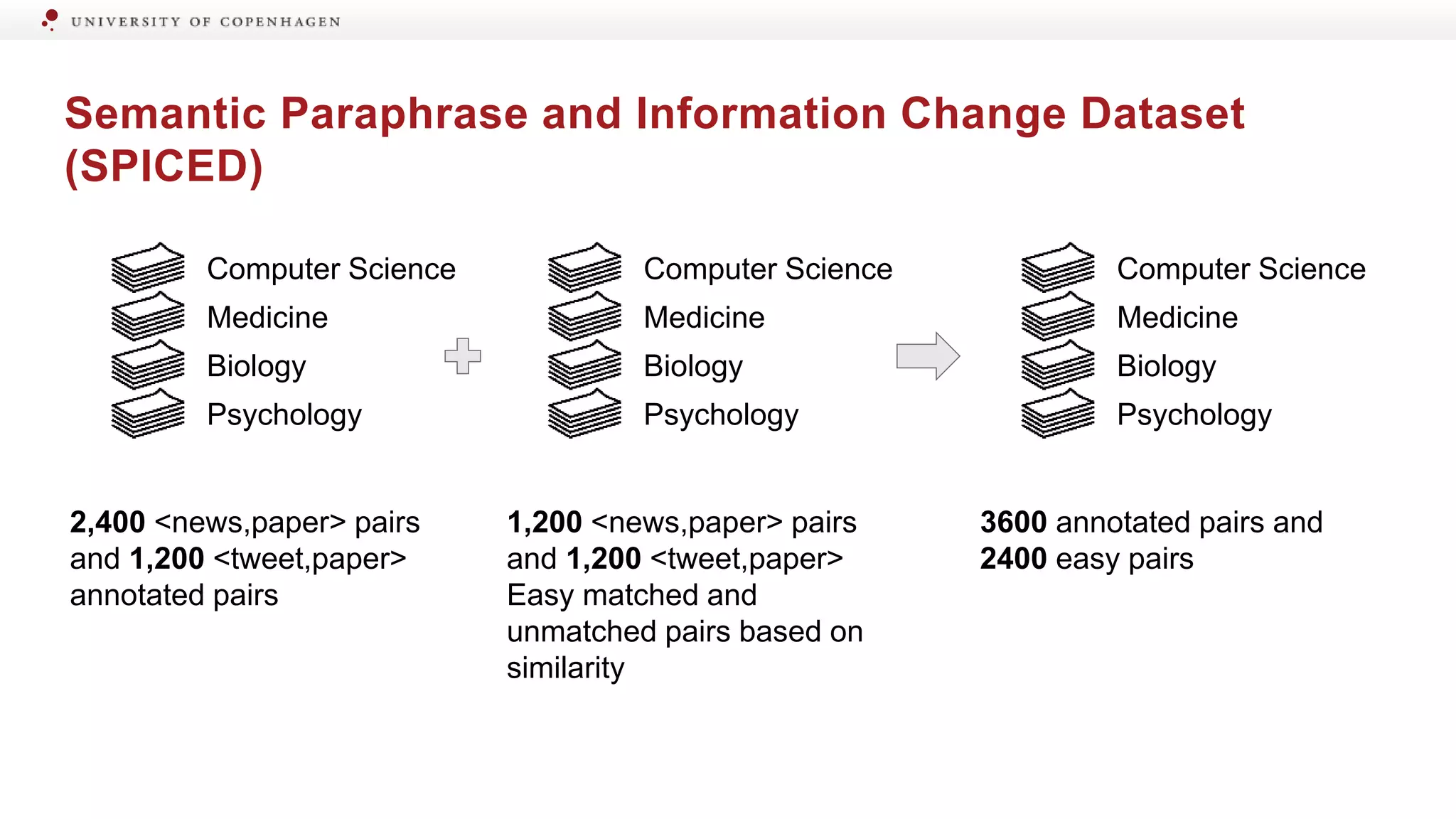
Details on the dataset creation for matched pairs in various scientific domains.
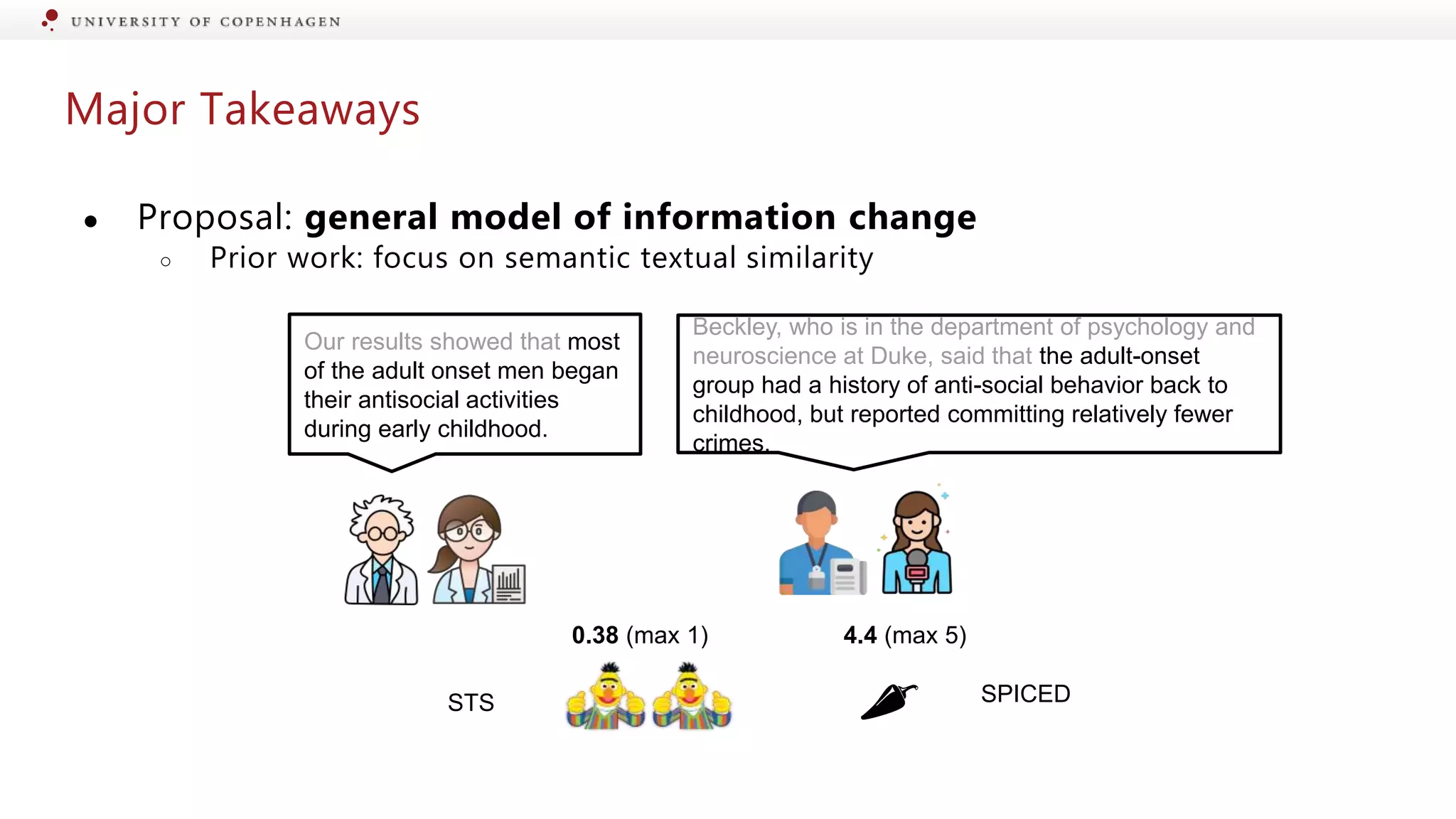
Comparison of SPICED approach with standard similarity tasks for measuring changes.
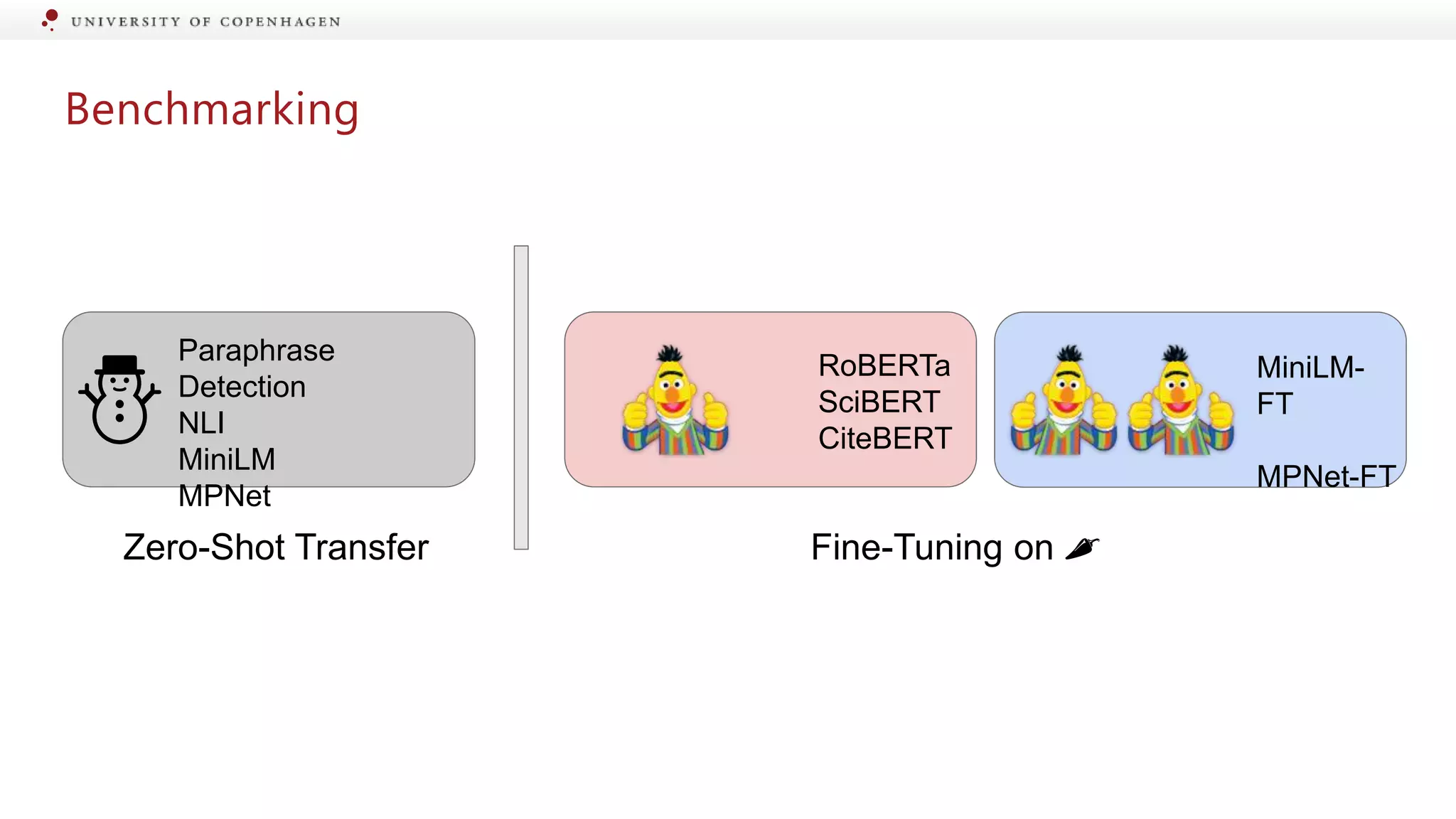
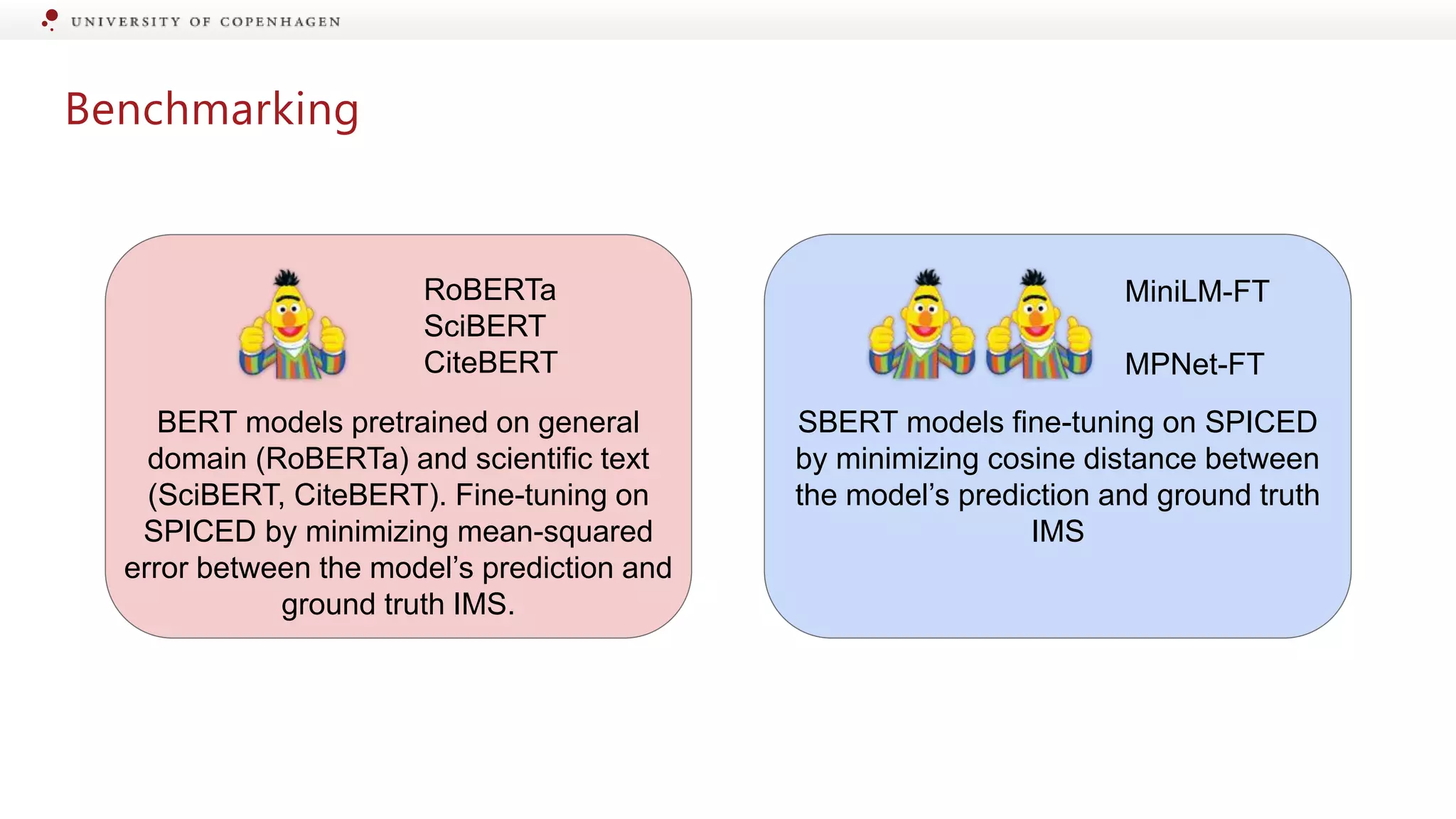
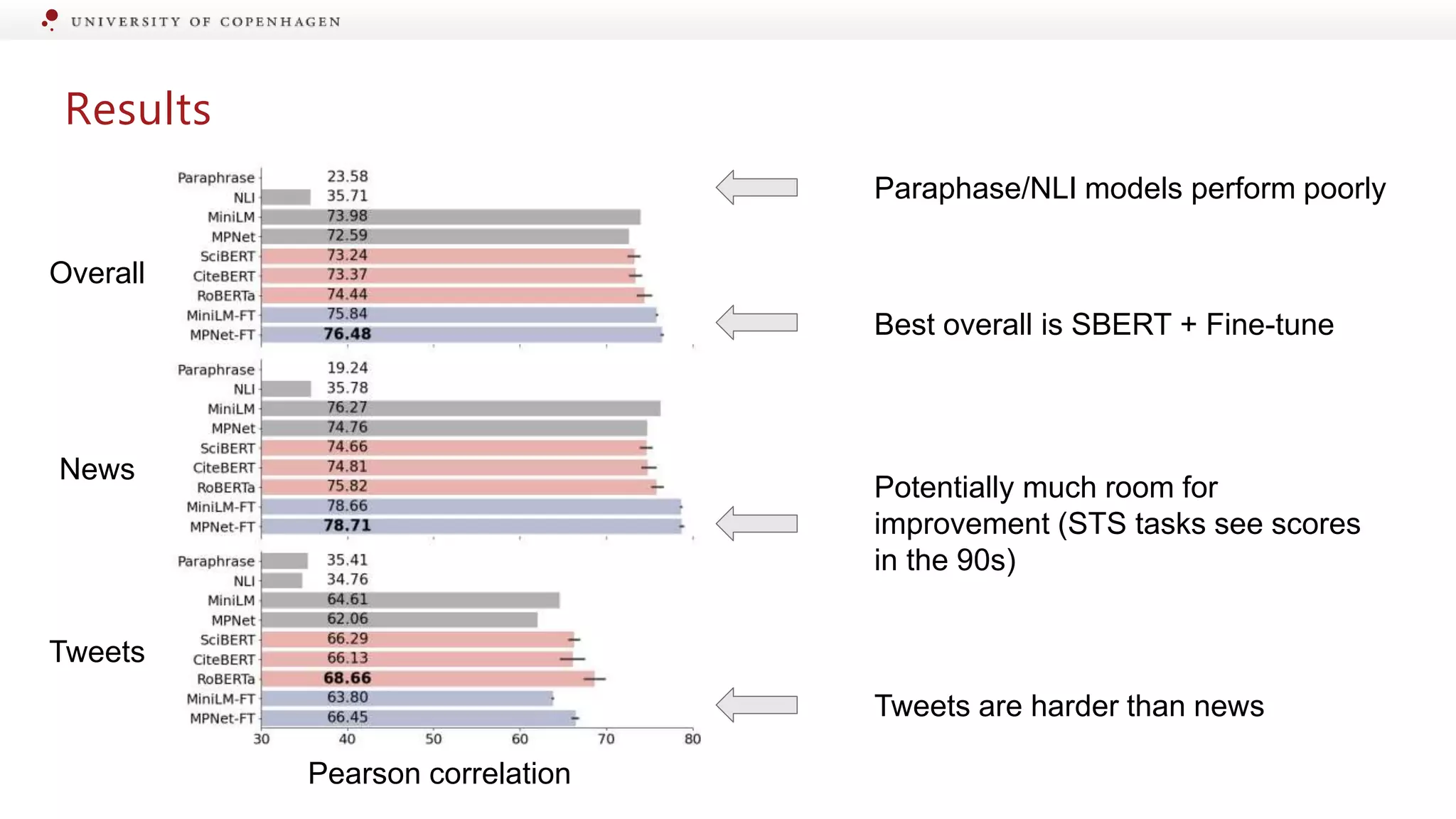
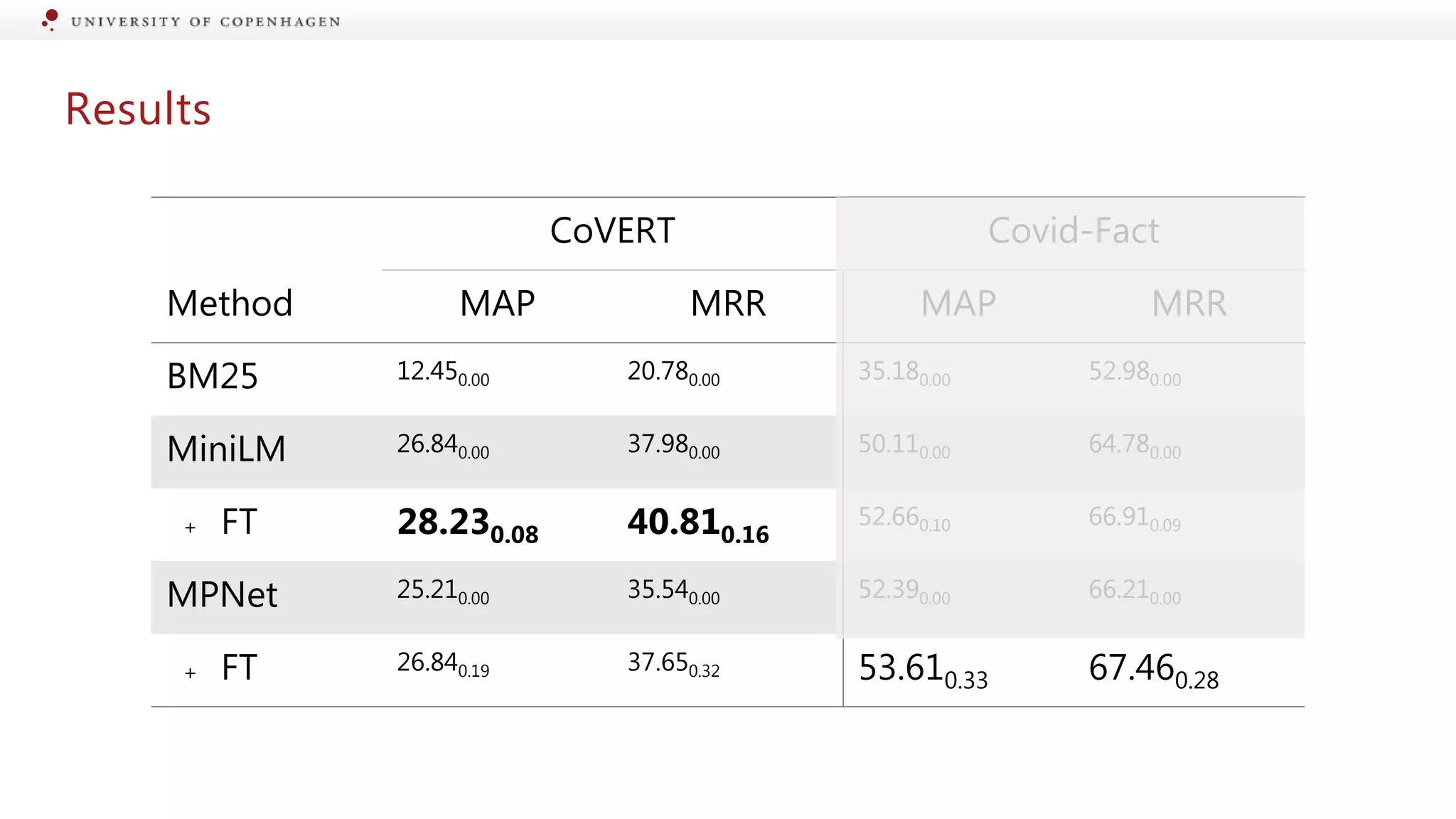
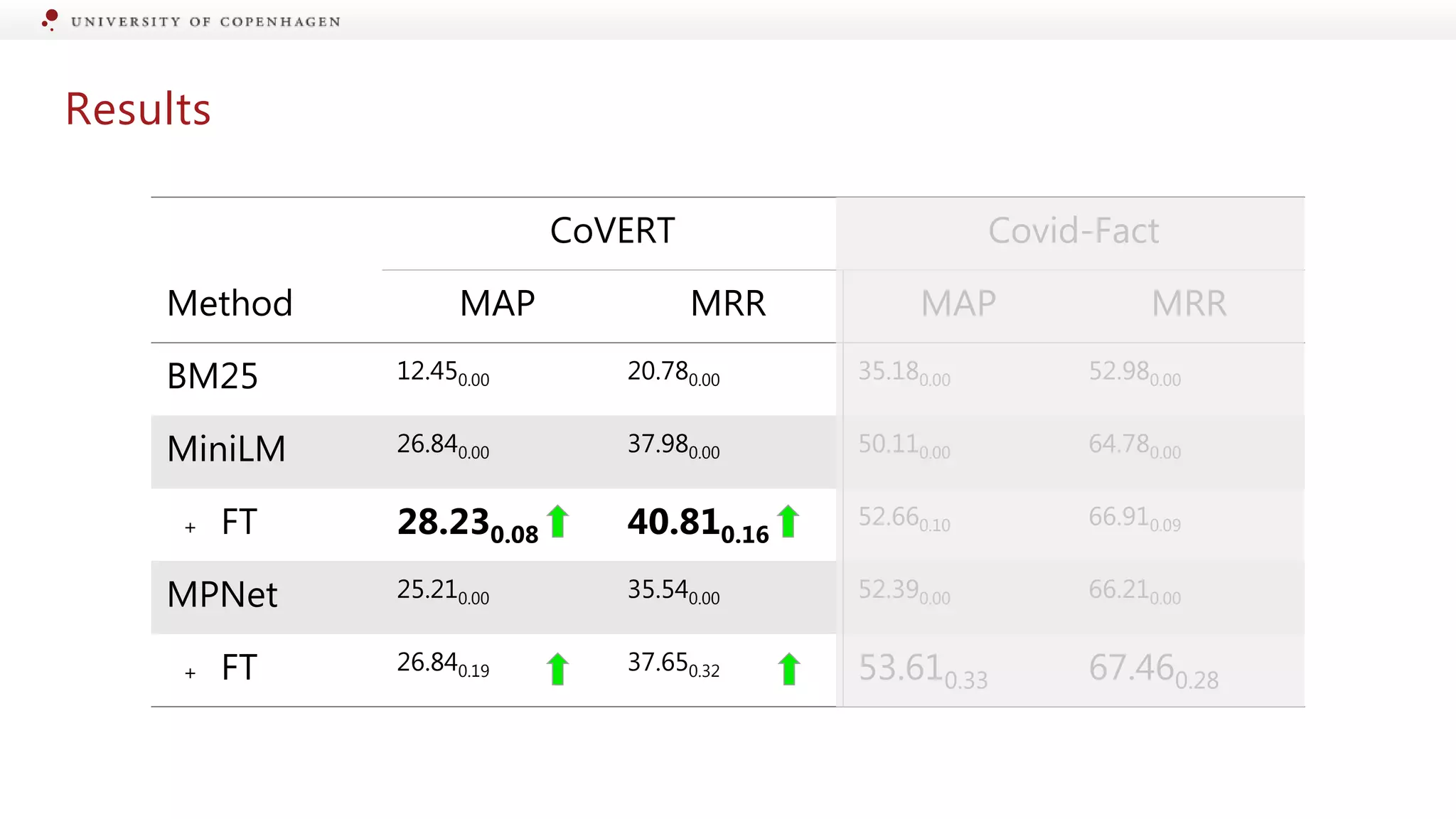
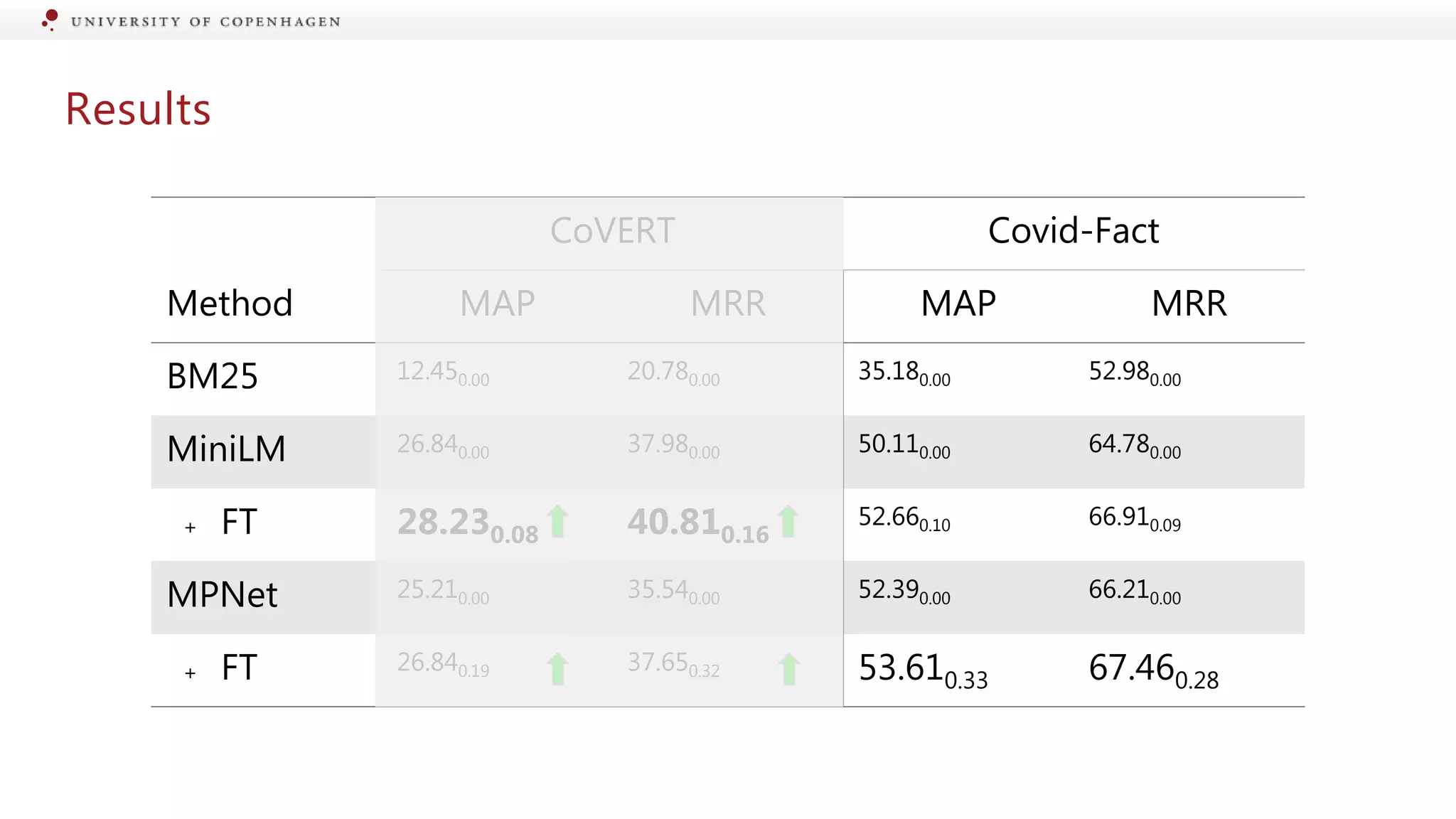
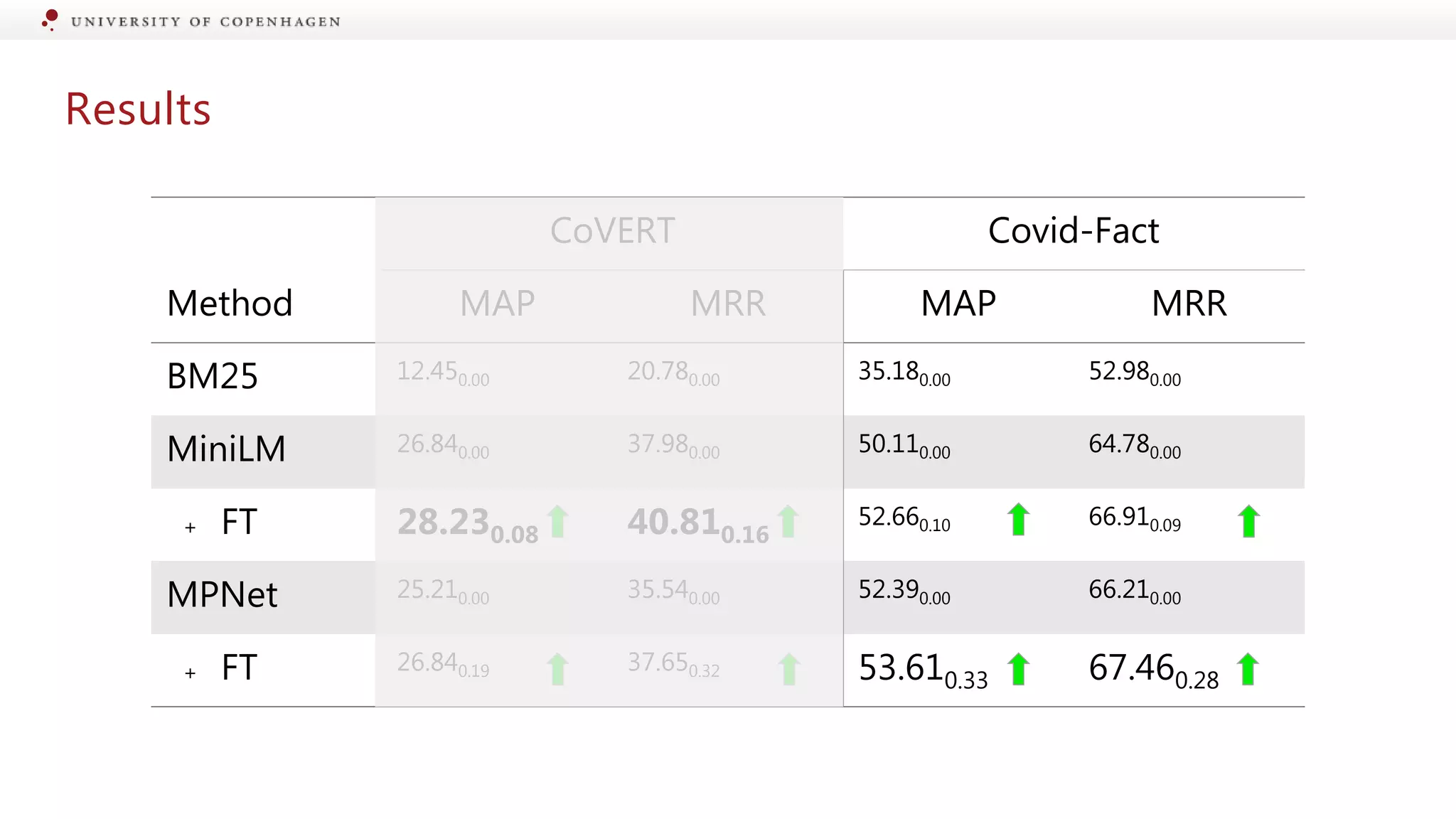
Evaluation of different models for their effectiveness in detecting information changes.
Assessing performance of models in retrieving scientific evidence from public claims.
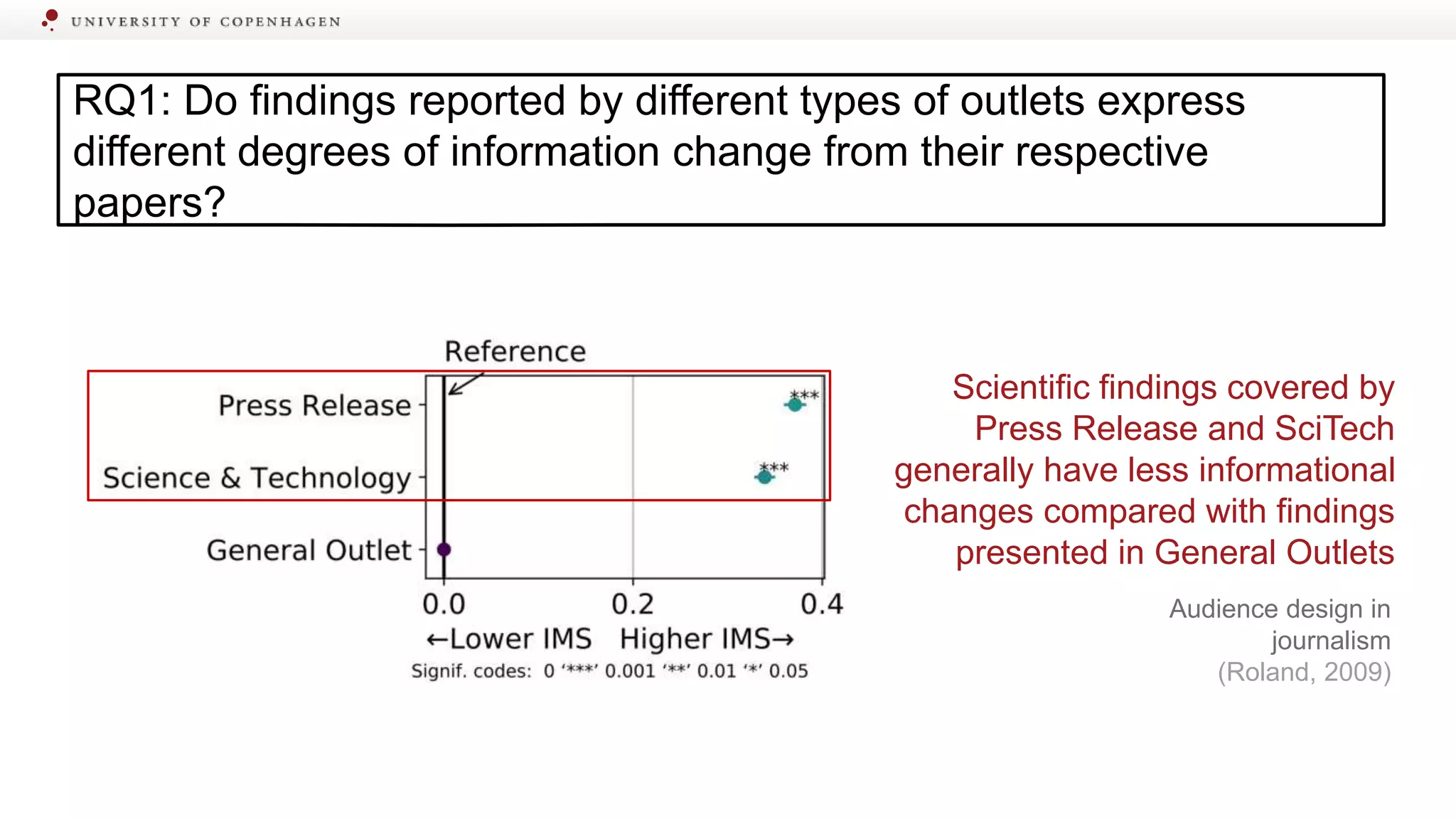
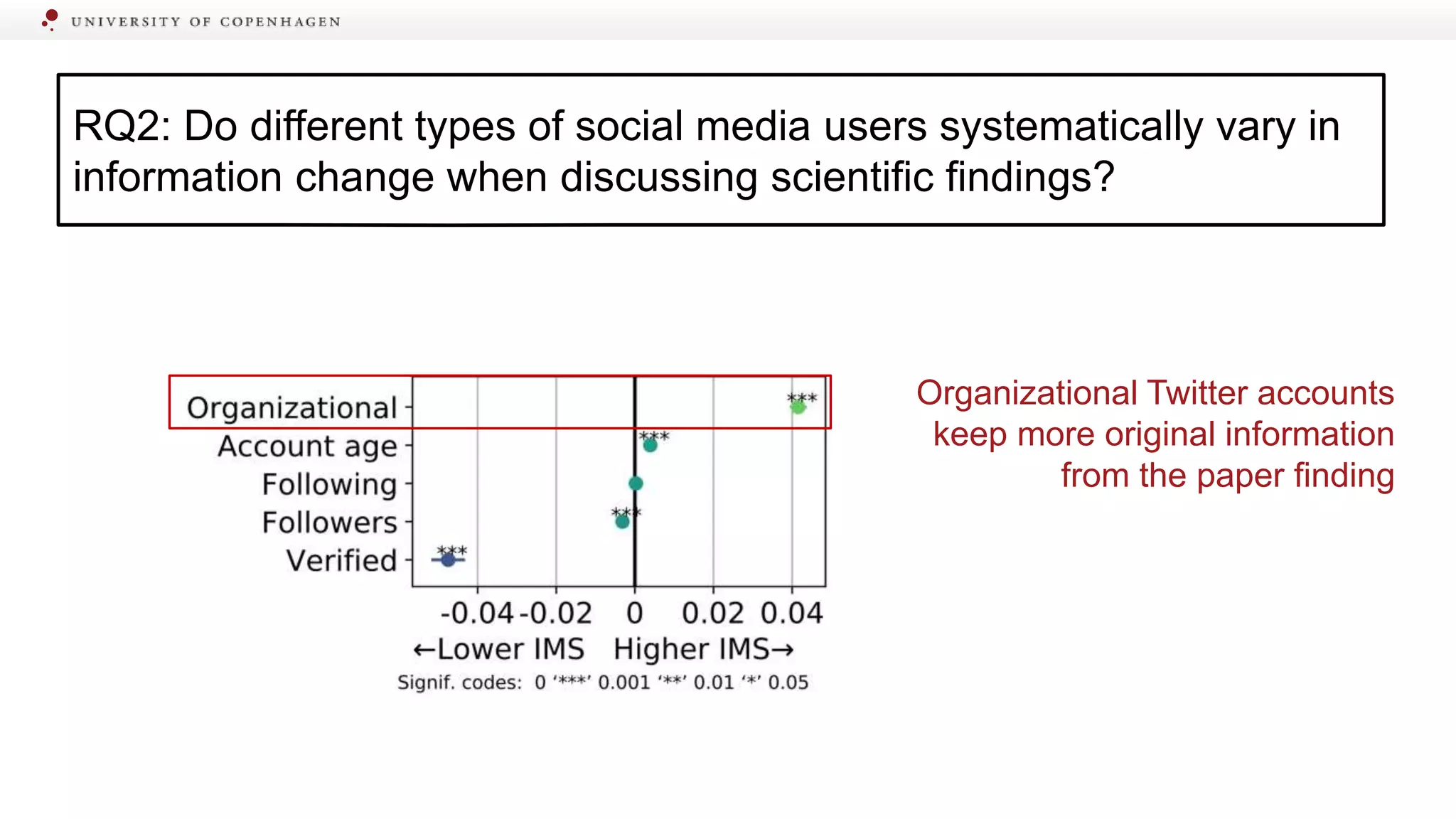
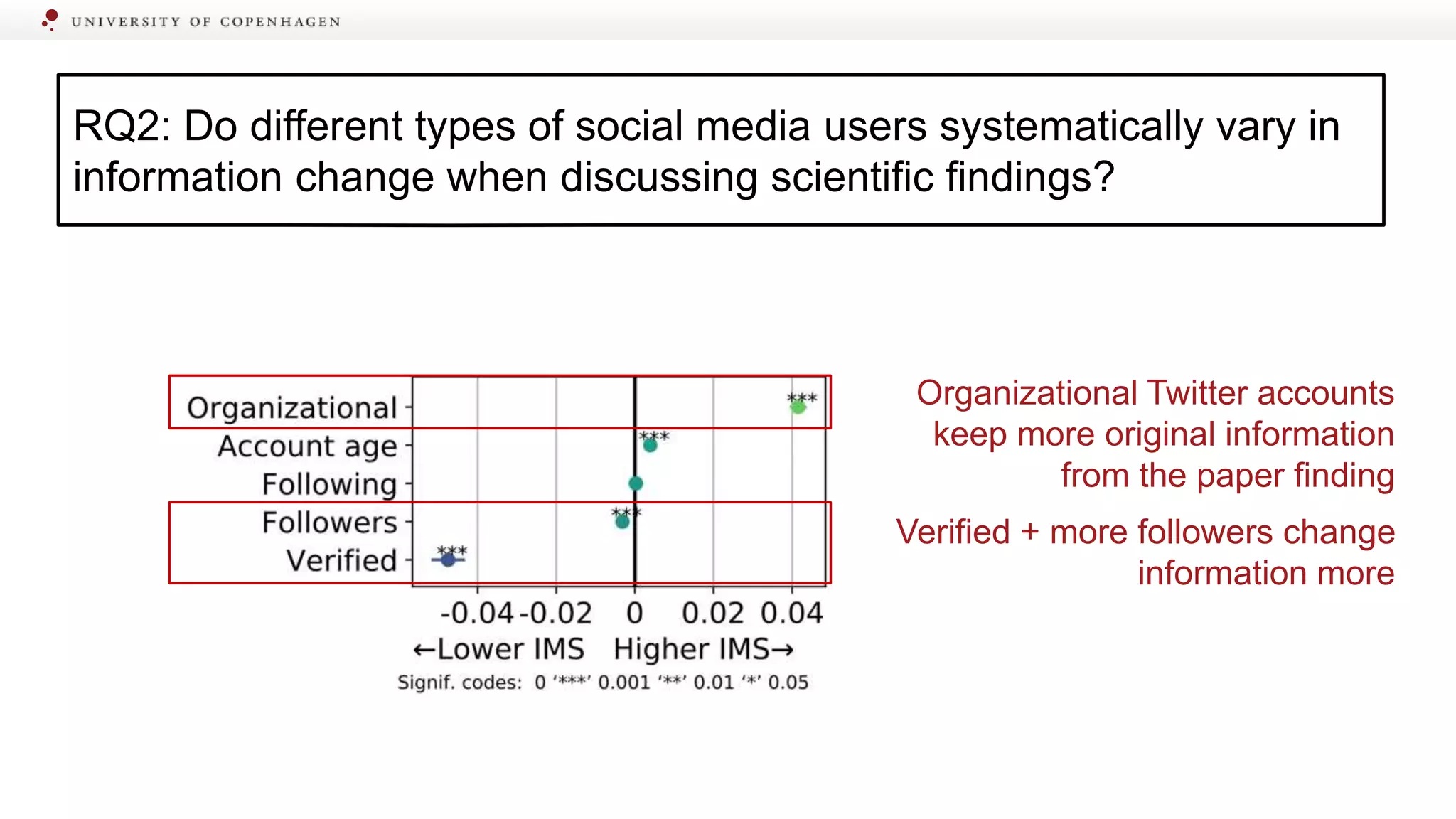
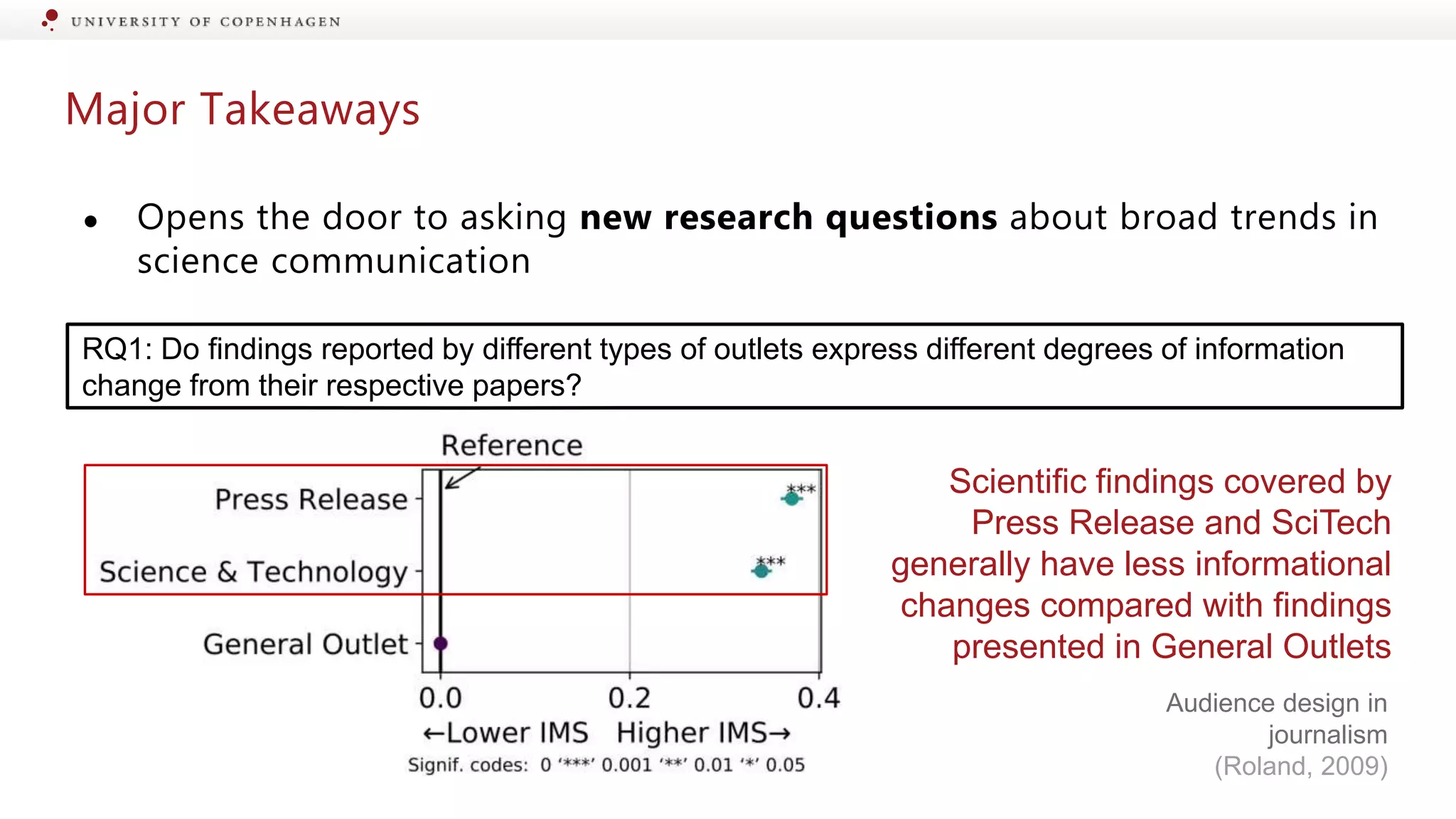
Explores differences in information change among various media platforms and user types.
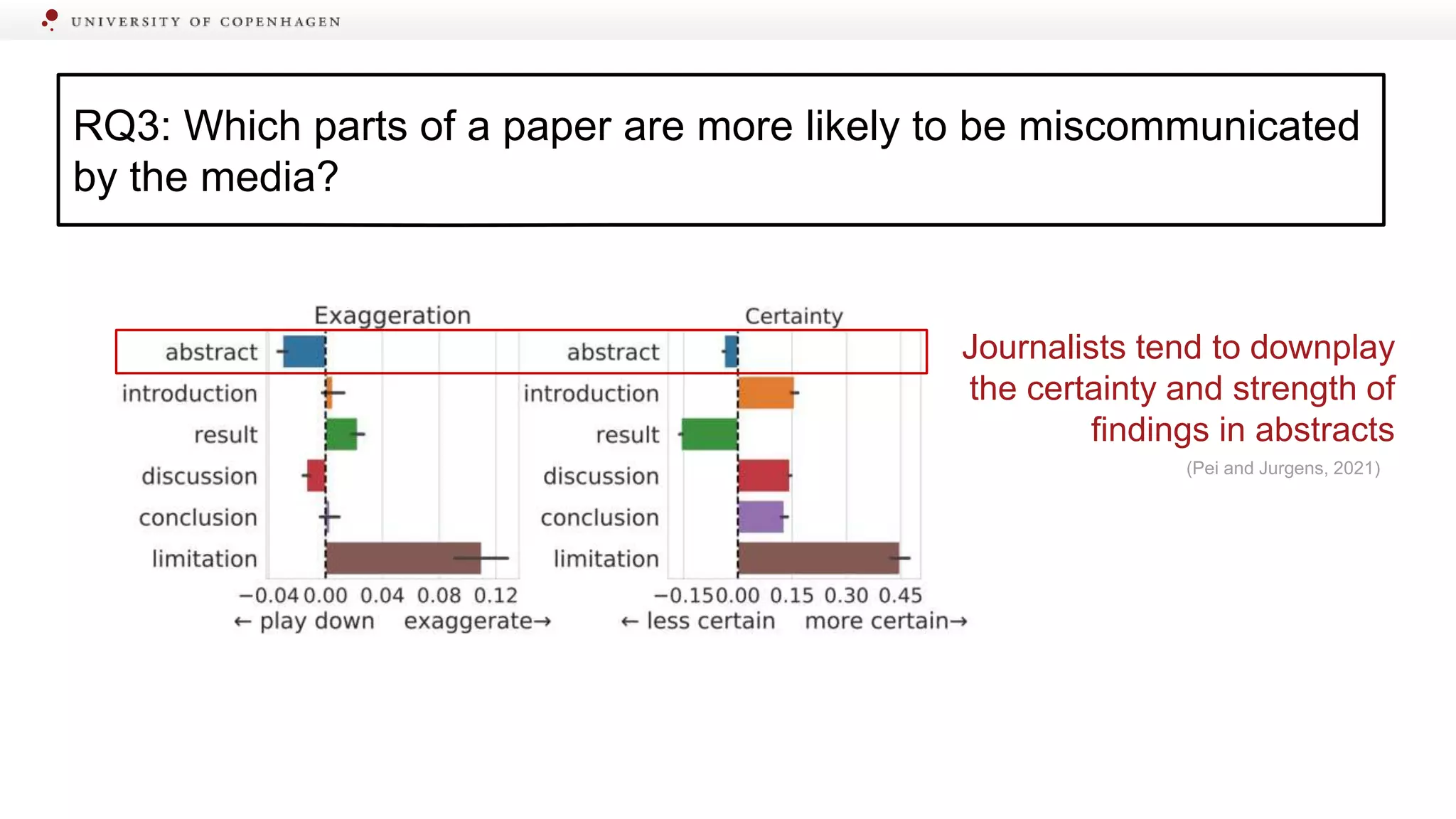
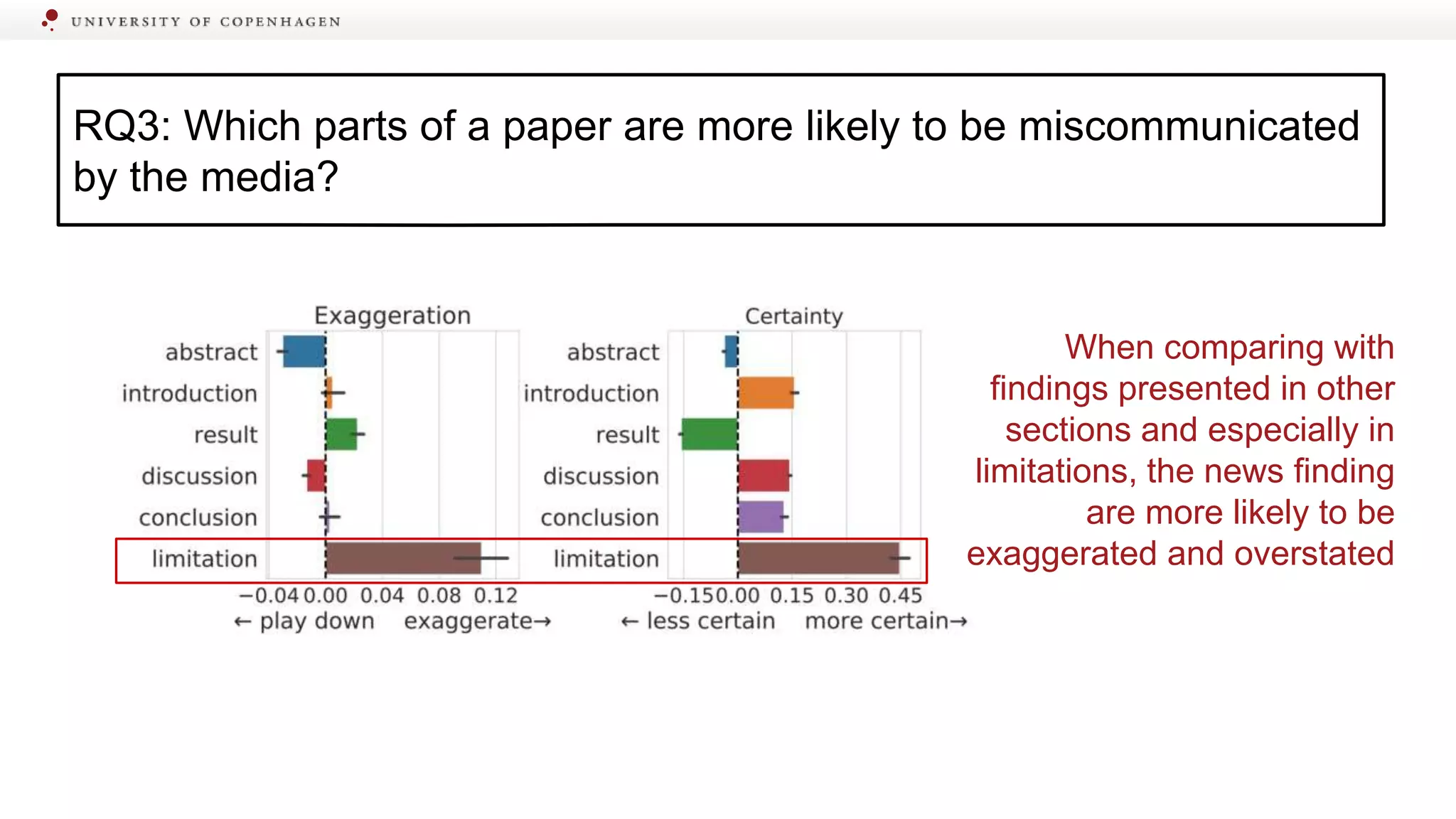
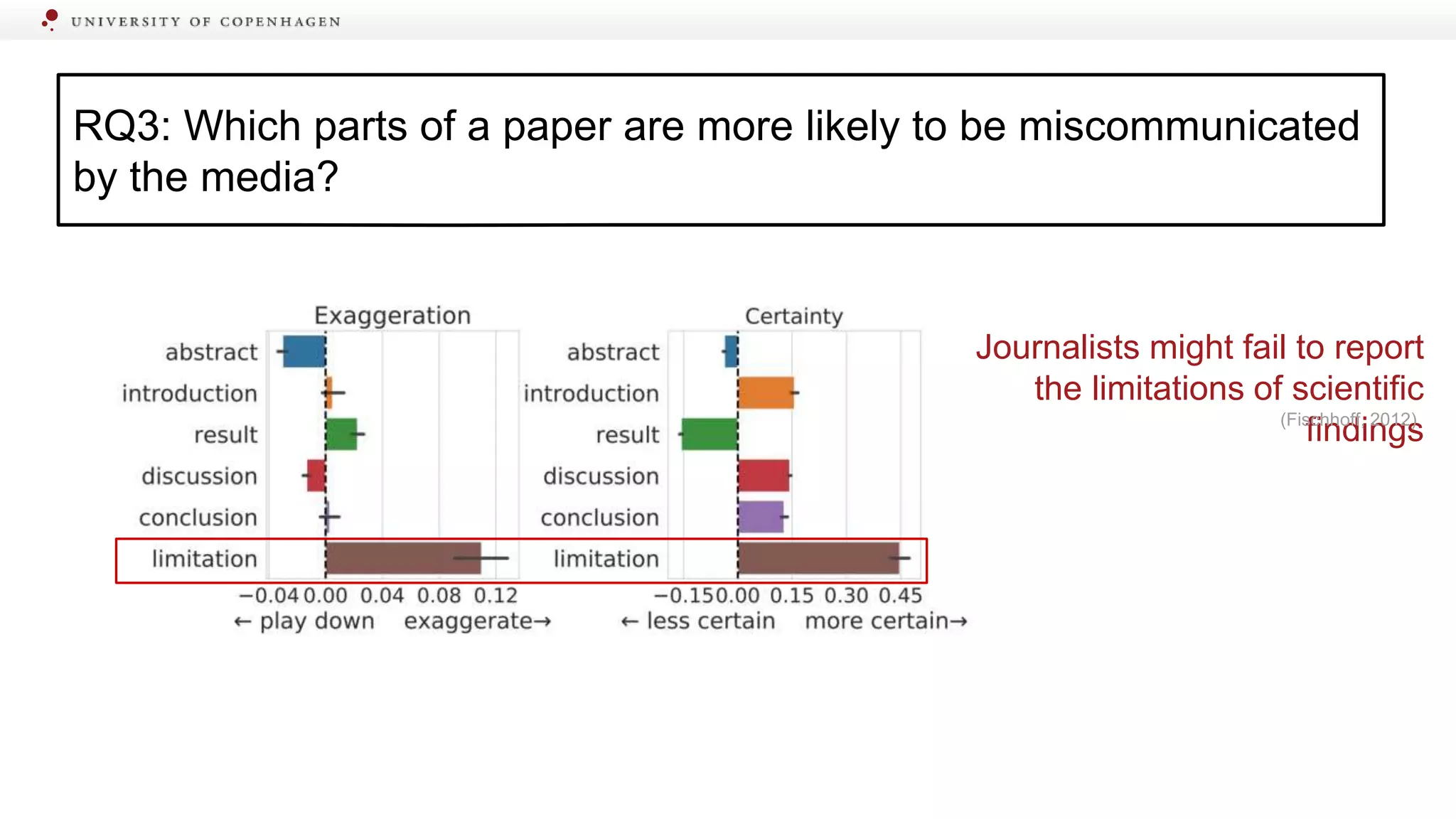
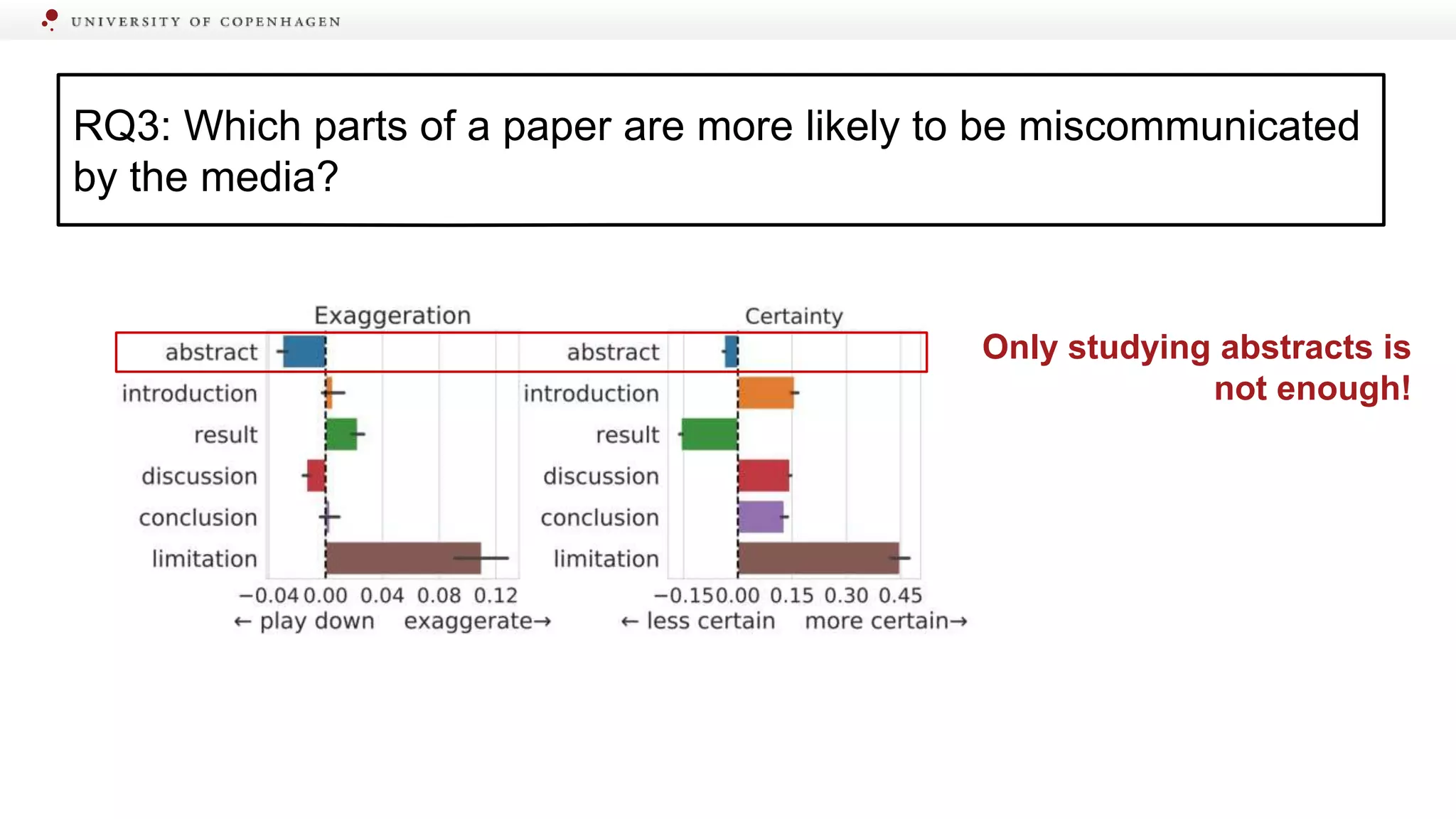
Identifying specific sections of scientific papers that are often miscommunicated by media.
Recap of major findings and future work directions in science communication research.
Acknowledgment of contributors, references, and calls for new positions in the field.



































































