Download as PDF, PPTX



















![23
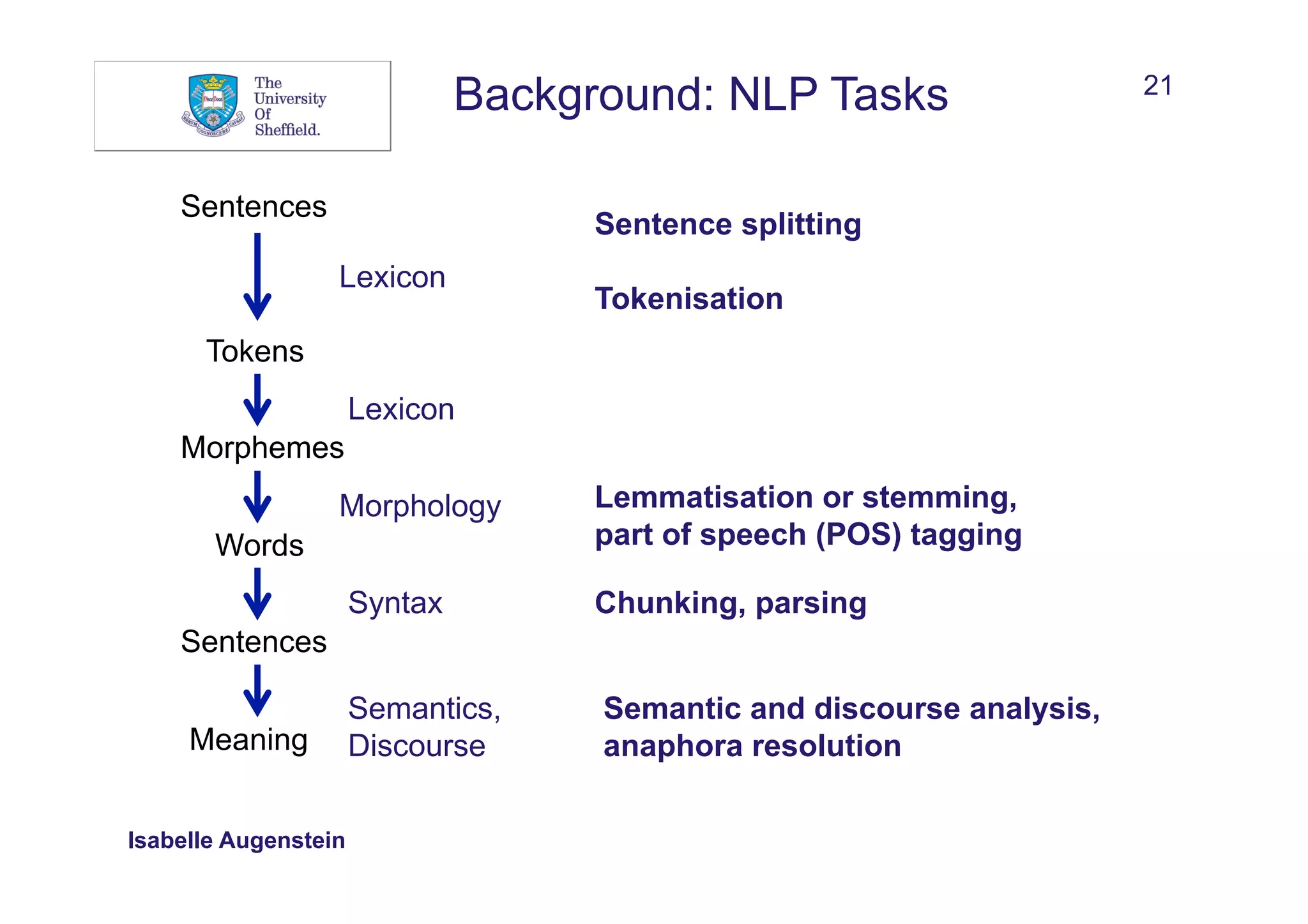
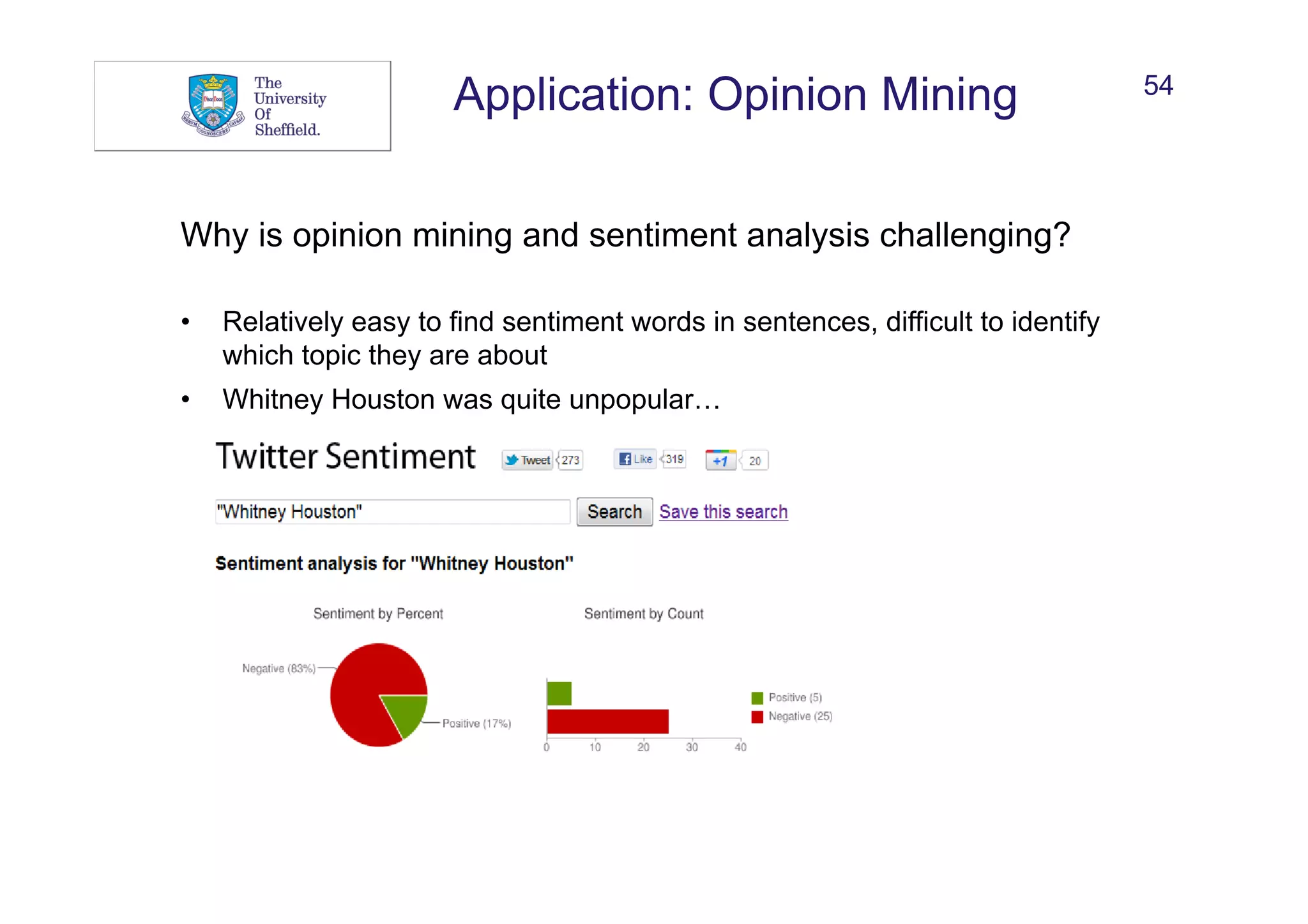
Background: Linguistics
Sentences
Tokens
Morphemes
Words
Sentences
Meaning
Isabelle Augenstein
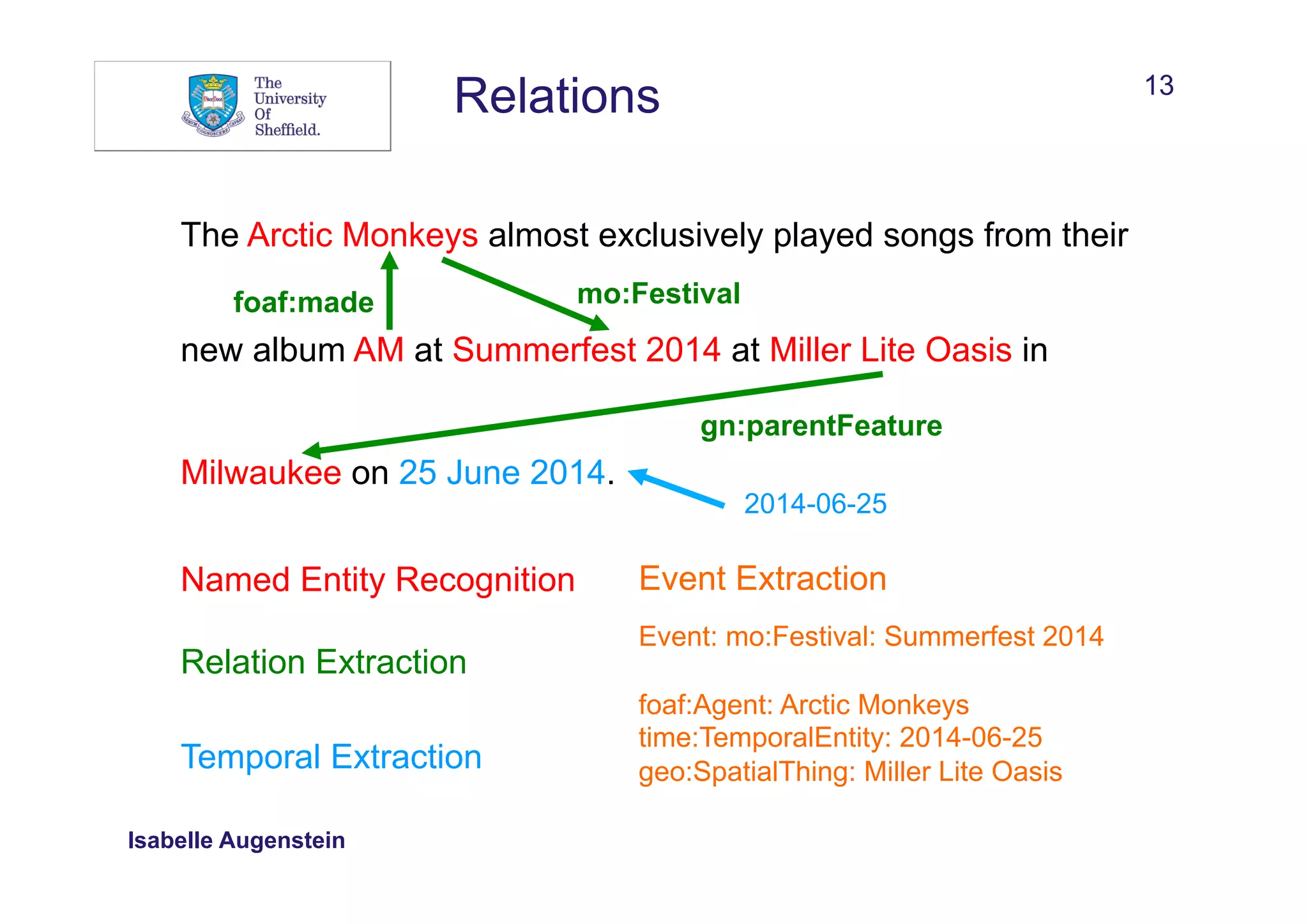
New York-based
[New, York-based] or [New, York, -, based]
Lexicon
Morphology
Syntax
Lexicon
Semantics,
Discourse](https://image.slidesharecdn.com/eswcss-2015-ie-150904112904-lva1-app6891/75/Information-Extraction-with-Linked-Data-23-2048.jpg)
![24
Background: Linguistics
Sentences
Tokens
Morphemes
Words
Sentences
Meaning
Isabelle Augenstein
Lexicon
Morphology
Syntax
Lexicon She’d
Semantics,
Discourse
New York-based
[New, York-based] or [New, York, -, based]](https://image.slidesharecdn.com/eswcss-2015-ie-150904112904-lva1-app6891/75/Information-Extraction-with-Linked-Data-24-2048.jpg)
![25
Background: Linguistics
Sentences
Tokens
Morphemes
Words
Sentences
Meaning
Isabelle Augenstein
Lexicon
Morphology
Syntax
Lexicon She’d -> she would, she had
Semantics,
Discourse
New York-based
[New, York-based] or [New, York, -, based]](https://image.slidesharecdn.com/eswcss-2015-ie-150904112904-lva1-app6891/75/Information-Extraction-with-Linked-Data-25-2048.jpg)
![26
Background: Linguistics
Sentences
Tokens
Morphemes
Words
Sentences
Meaning
Isabelle Augenstein
Lexicon
Morphology
Syntax
Lexicon She’d -> she would, she had
Semantics,
Discourse
New York-based
[New, York-based] or [New, York, -, based]
Time flies like an arrow](https://image.slidesharecdn.com/eswcss-2015-ie-150904112904-lva1-app6891/75/Information-Extraction-with-Linked-Data-26-2048.jpg)
![27
Background: Linguistics
Sentences
Tokens
Morphemes
Words
Sentences
Meaning
Isabelle Augenstein
Lexicon
Morphology
Syntax
Lexicon She’d -> she would, she had
Semantics,
Discourse
New York-based
[New, York-based] or [New, York, -, based]
Time flies(V/N) like(V/P) an arrow](https://image.slidesharecdn.com/eswcss-2015-ie-150904112904-lva1-app6891/75/Information-Extraction-with-Linked-Data-27-2048.jpg)
![28
Background: Linguistics
Sentences
Tokens
Morphemes
Words
Sentences
Meaning
Isabelle Augenstein
Lexicon
Morphology
Syntax
Lexicon She’d -> she would, she had
Semantics,
Discourse
New York-based
[New, York-based] or [New, York, -, based]
Time flies(V/N) like(V/P) an arrow
The woman saw the man with the
binoculars.](https://image.slidesharecdn.com/eswcss-2015-ie-150904112904-lva1-app6891/75/Information-Extraction-with-Linked-Data-28-2048.jpg)
![29
Background: Linguistics
Sentences
Tokens
Morphemes
Words
Sentences
Meaning
Isabelle Augenstein
Lexicon
Morphology
Syntax
Lexicon She’d -> she would, she had
Semantics,
Discourse
New York-based
[New, York-based] or [New, York, -, based]
Time flies(V/N) like(V/P) an arrow
The woman saw the man with the
binoculars. -> Who had the binoculars?](https://image.slidesharecdn.com/eswcss-2015-ie-150904112904-lva1-app6891/75/Information-Extraction-with-Linked-Data-29-2048.jpg)
![30
Background: Linguistics
Sentences
Tokens
Morphemes
Words
Sentences
Meaning
Isabelle Augenstein
Lexicon
Morphology
Syntax
Lexicon She’d -> she would, she had
Semantics,
Discourse
New York-based
[New, York-based] or [New, York, -, based]
Time flies(V/N) like(V/P) an arrow
The woman saw the man with the
binoculars. -> Who had the binoculars?
Somewhere in Britain, some woman
has a child every thirty seconds.](https://image.slidesharecdn.com/eswcss-2015-ie-150904112904-lva1-app6891/75/Information-Extraction-with-Linked-Data-30-2048.jpg)
![31
Background: Linguistics
Sentences
Tokens
Morphemes
Words
Sentences
Meaning
Isabelle Augenstein
Lexicon
Morphology
Syntax
Lexicon She’d -> she would, she had
Semantics,
Discourse
New York-based
[New, York-based] or [New, York, -, based]
Time flies(V/N) like(V/P) an arrow
The woman saw the man with the
binoculars. -> Who had the binoculars?
Somewhere in Britain, some woman
has a child every thirty seconds.
-> Same woman or different women?](https://image.slidesharecdn.com/eswcss-2015-ie-150904112904-lva1-app6891/75/Information-Extraction-with-Linked-Data-31-2048.jpg)
![32
Background: Linguistics
Sentences
Tokens
Morphemes
Words
Sentences
Meaning
Isabelle Augenstein
Lexicon
Morphology
Syntax
Lexicon She’d -> she would, she had
Semantics,
Discourse
New York-based
[New, York-based] or [New, York, -, based]
Time flies(V/N) like(V/P) an arrow
The woman saw the man with the
binoculars. -> Who had the binoculars?
Somewhere in Britain, some woman
has a child every thirty seconds.
-> Same woman or different women?
Ambiguities on every level](https://image.slidesharecdn.com/eswcss-2015-ie-150904112904-lva1-app6891/75/Information-Extraction-with-Linked-Data-32-2048.jpg)
![33
Background: Linguistics
Sentences
Tokens
Morphemes
Words
Sentences
Meaning
Isabelle Augenstein
Lexicon
Morphology
Syntax
Lexicon She’d -> she would, she had
Semantics,
Discourse
New York-based
[New, York-based] or [New, York, -, based]
Time flies(V/N) like(V/P) an arrow
The woman saw the man with the
binoculars. -> Who had the binoculars?
Somewhere in Britain, some woman
has a child every thirty seconds.
-> Same woman or different women?
Ambiguities on every level
Y U SO
AMBIGUOUS?](https://image.slidesharecdn.com/eswcss-2015-ie-150904112904-lva1-app6891/75/Information-Extraction-with-Linked-Data-33-2048.jpg)


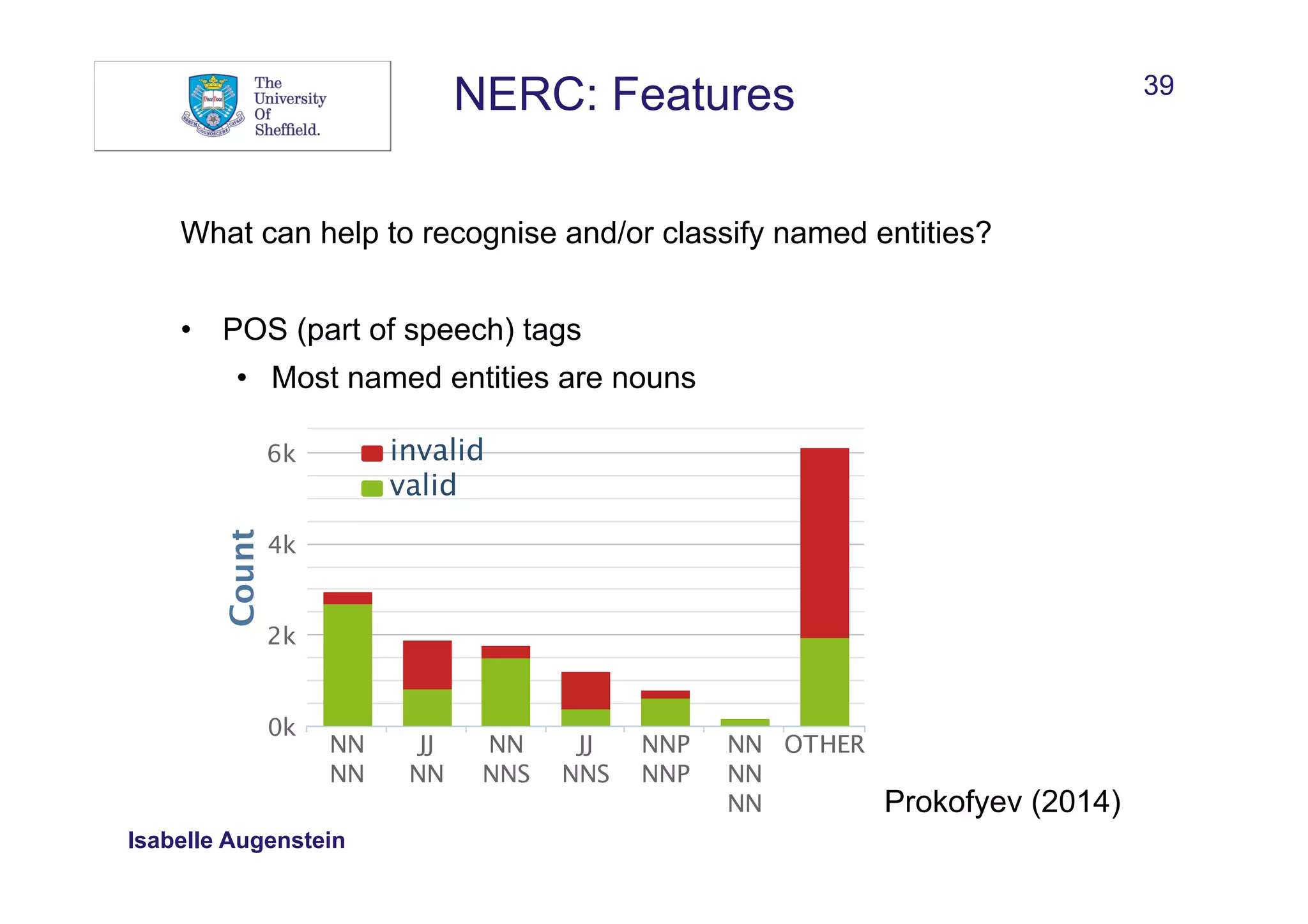
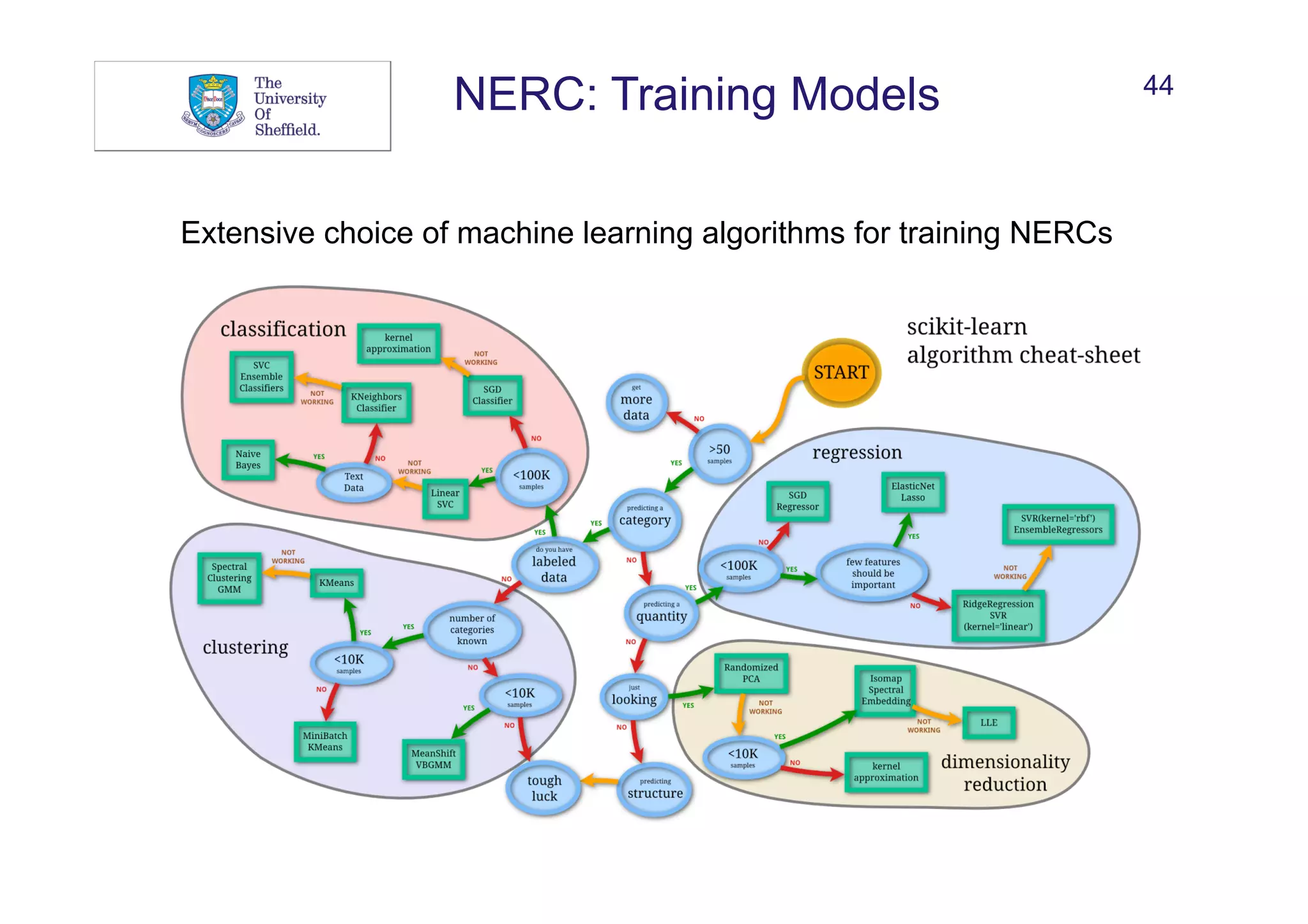
![37
NERC: Features
What can help to recognise and/or classify named entities?
• Words:
• Words in window before and after mention
• Sequences
• Bags of words
Summerfest 2014 took place at Miller Lite Oasis in Milwaukee on 25
June 2014.
w: Milwaukee w-1: in w-2: Oasis w+1: on w+2: 25
seq[-]: Oasis in seq[+]: on 25
bow: Milwaukee bow[-]: in bow[-]: Oasis bow[+]: on bow[+]: 25
Isabelle Augenstein](https://image.slidesharecdn.com/eswcss-2015-ie-150904112904-lva1-app6891/75/Information-Extraction-with-Linked-Data-37-2048.jpg)

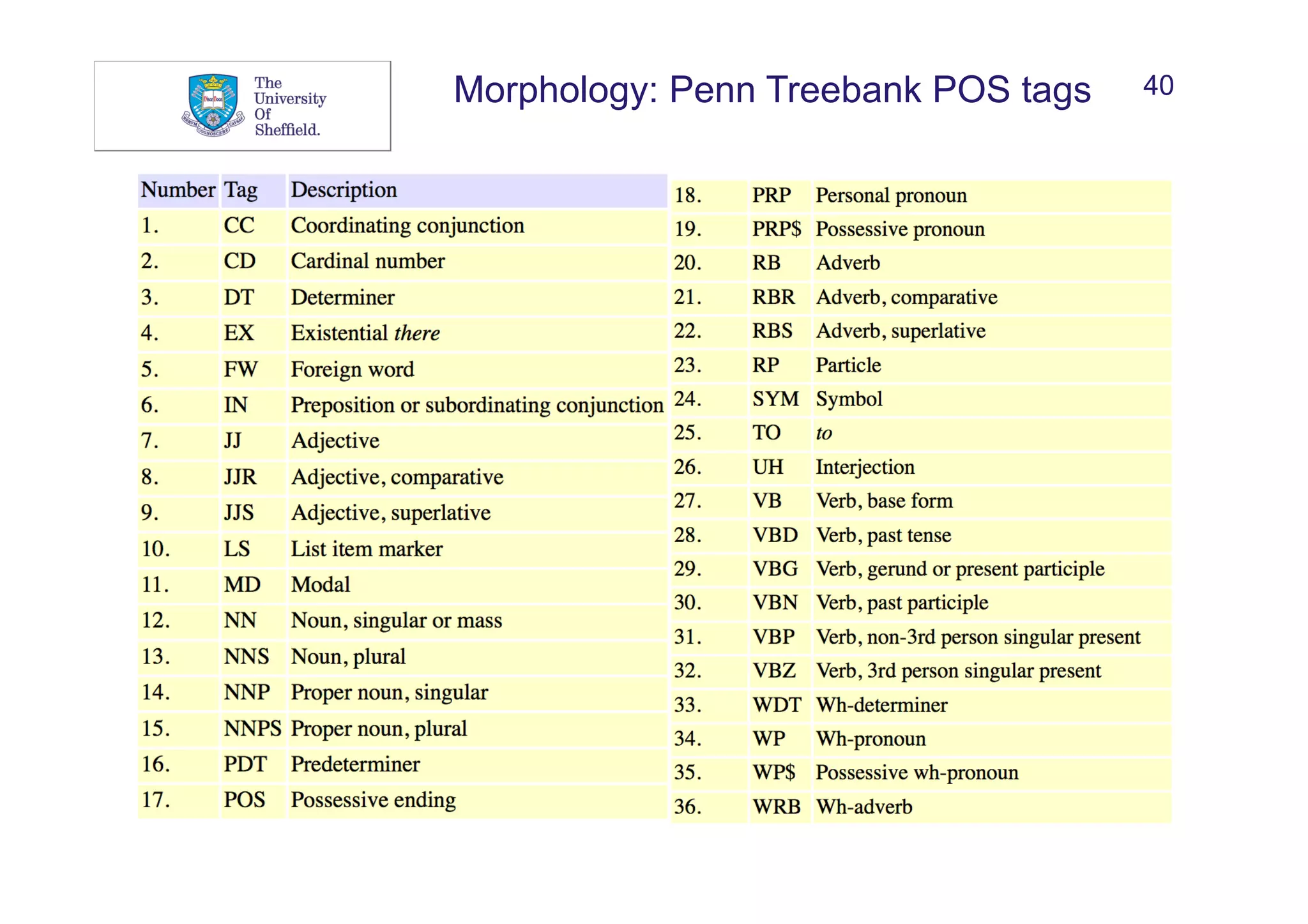
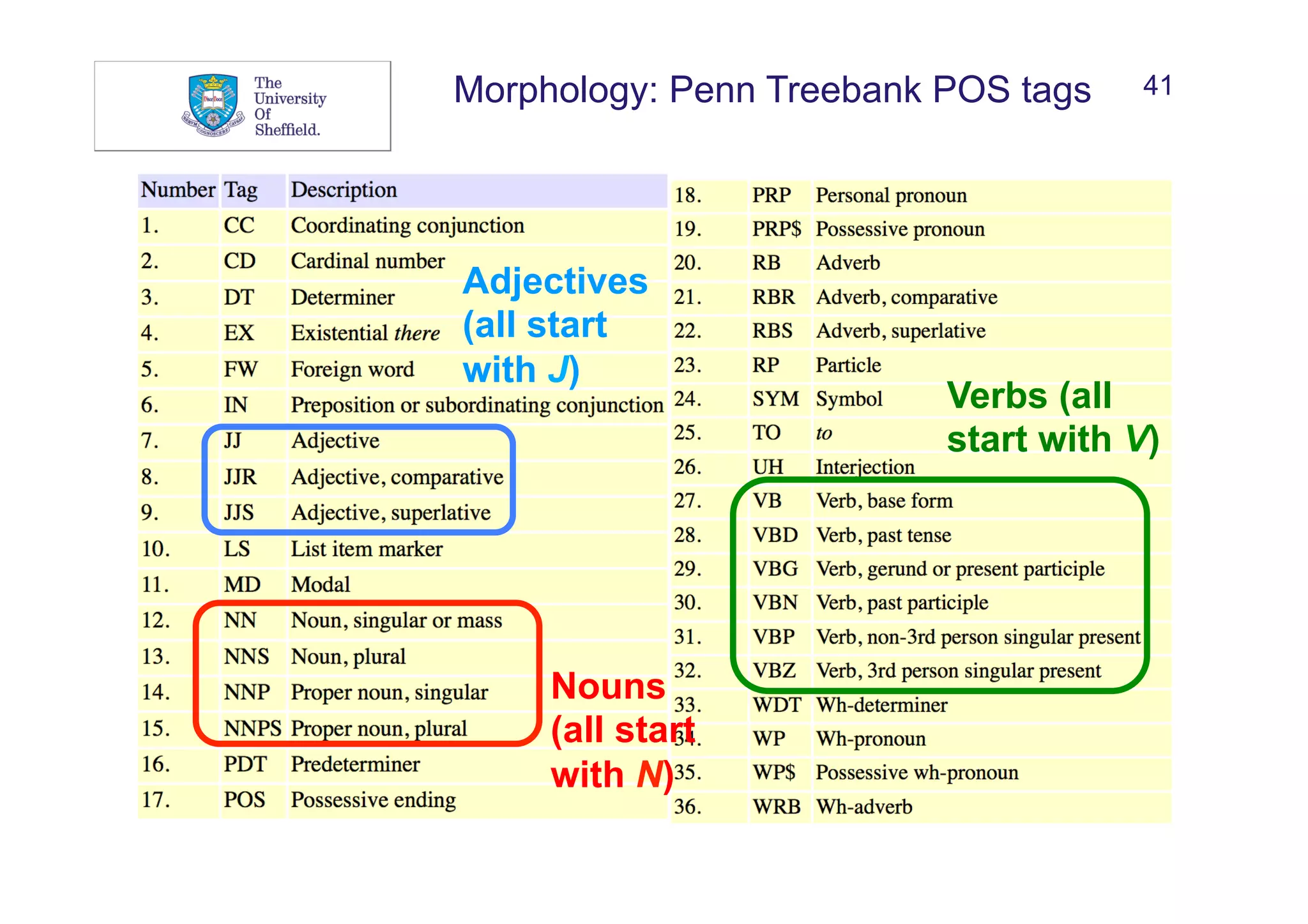
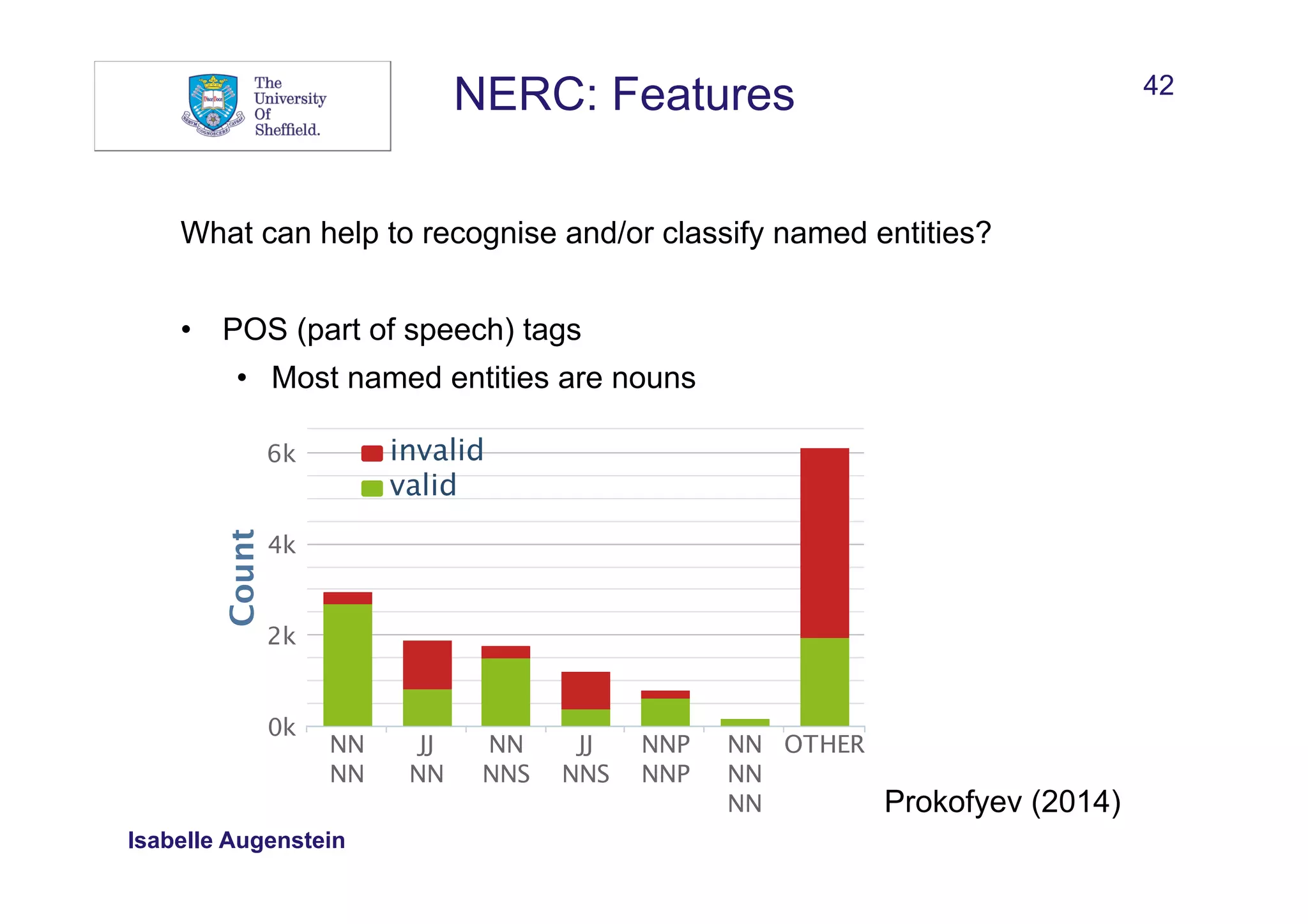
![43
NERC: Features
What can help to recognise and/or classify named entities?
• Gazetteers
• Retrieved from HTML lists or tables [1]
• Using regular expressions patterns and search engines (e.g.
“Popular artists such as * ”)
• Retrieved from knowledge bases
[1] https://en.wikipedia.org/wiki/Billboard_200
Isabelle Augenstein](https://image.slidesharecdn.com/eswcss-2015-ie-150904112904-lva1-app6891/75/Information-Extraction-with-Linked-Data-43-2048.jpg)















The document details techniques for information extraction (IE) using linked data, focusing on methods such as named entity recognition (NER), classification, linking, and relation extraction. It highlights the importance of linguistic features and machine learning approaches in developing effective IE systems. The tutorial aims to demonstrate how these methods can annotate and aggregate data to enhance knowledge bases.



































































