





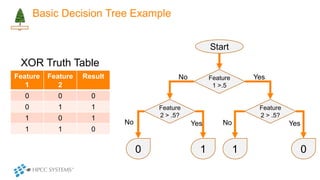
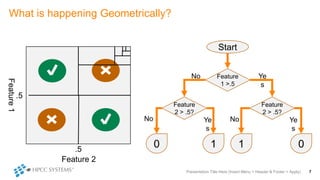
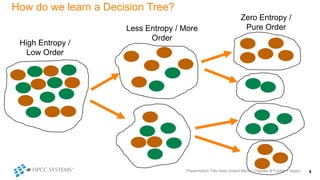


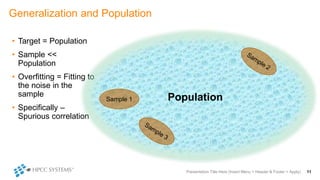

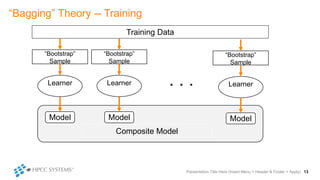



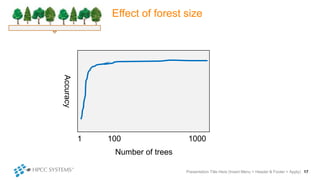


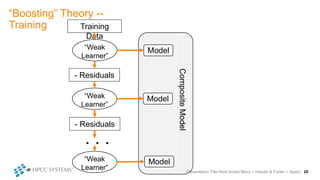
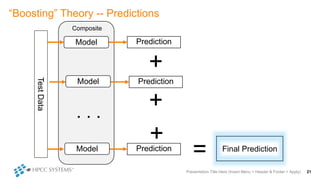






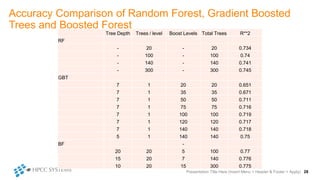
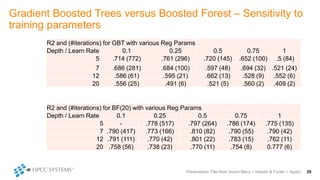

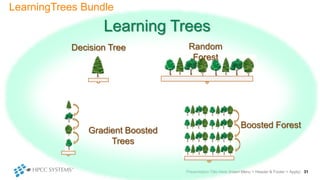

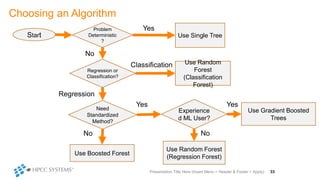


The document outlines decision tree learning methods, highlighting the strengths and weaknesses of decision trees, random forests, and gradient boosted trees. It explains the mechanics of these algorithms, their applications in regression and classification, and compares their accuracy and efficiency. Additionally, it discusses the configuration of parameters and the importance of feature selection in building robust models.



































































