Download to read offline



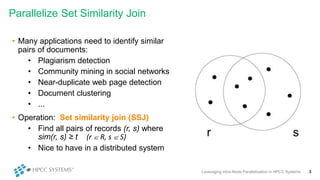

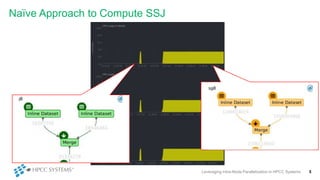

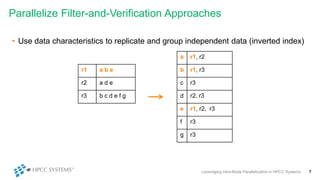
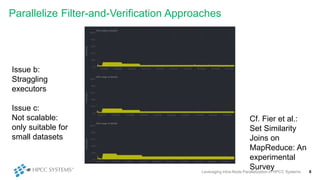


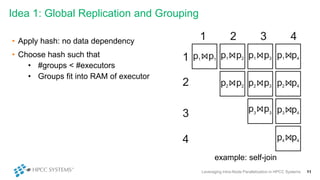

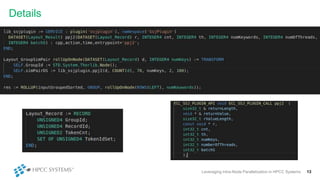



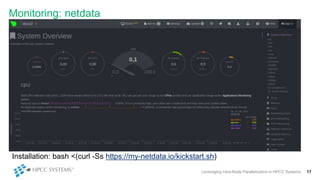
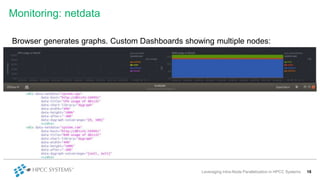
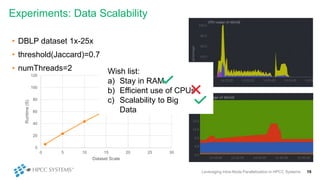
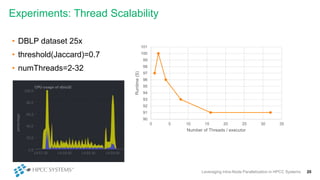
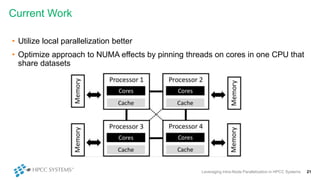



This document discusses leveraging intra-node parallelization in HPCC Systems to improve the performance of set similarity joins (SSJ). It describes a naïve approach to computing SSJ that suffers from memory exhaustion and straggling executors. The presented approach replicates and groups independent data using hashing to address these issues while enabling efficient use of multiple CPU cores through multithreading. Experiments show the approach scales to larger datasets and achieves better performance by increasing the number of threads per executor. Lessons learned include that less complex optimizations are more robust in distributed environments.











![Frossie Economou & Angelo Fausti [Vera C. Rubin Observatory] | How InfluxDB H...](https://cdn.slidesharecdn.com/ss_thumbnails/veracrubininfluxdays2020-201111202349-thumbnail.jpg?width=640&height=640&fit=bounds)










































































