Download as PDF, PPTX

















































![+ Using the CPU scheduler in code looks something like this:
● Create a place-holder for the scheduling group tag (global for the sake of example):
scheduling_group my_scheduling_group;
● create_scheduling_group(“my_important_sg”, 150).then([] (scheduling_group
new_sg) {
my_scheduling_group = new_sg;
}
Now we have the tag initialized and we can use it.
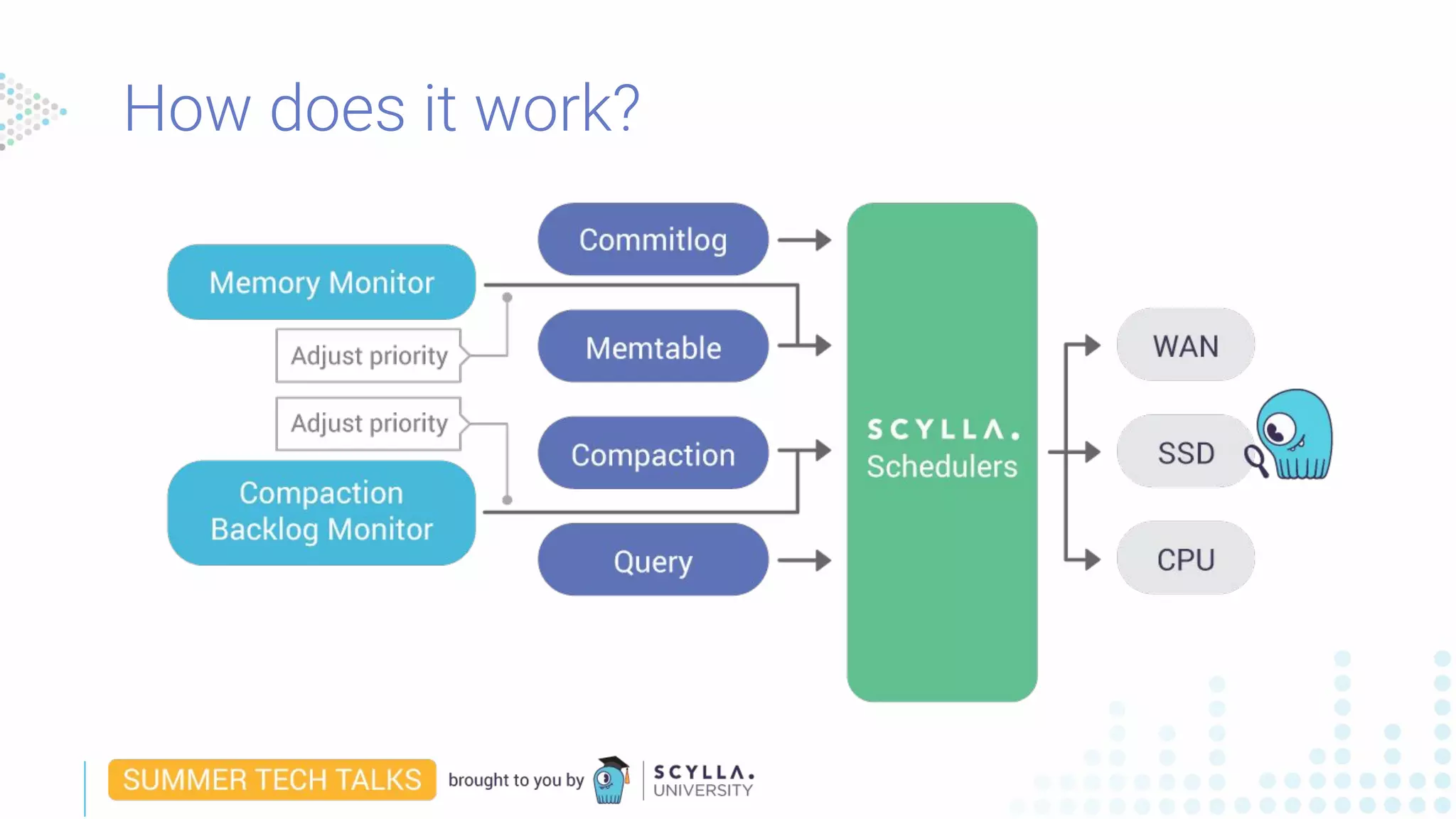
How does it work?](https://image.slidesharecdn.com/workloadprioritizationwebinaraugust142019-190814184259/75/Webinar-How-to-Shrink-Your-Datacenter-Footprint-by-50-64-2048.jpg)
![+ Using the CPU scheduler in code (cont):
● Assuming we have somewhere:
auto my_function = [] () {
… do some stuff ...
}
● We can now run my_function with our newly created priority tag:
future<> fut = with_scheduling_group(my_scheduling_group, my_function);
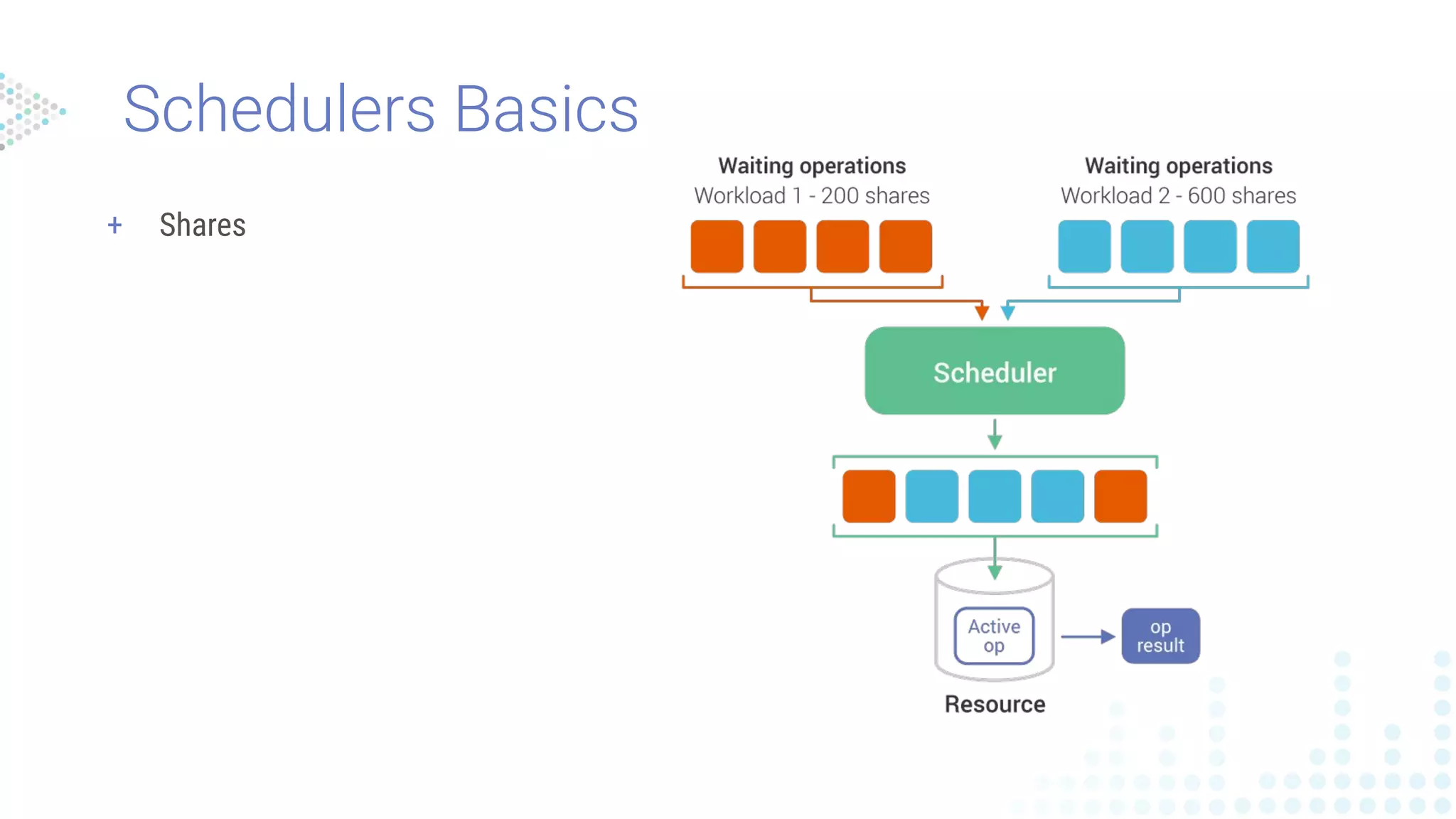
How does it work?](https://image.slidesharecdn.com/workloadprioritizationwebinaraugust142019-190814184259/75/Webinar-How-to-Shrink-Your-Datacenter-Footprint-by-50-65-2048.jpg)

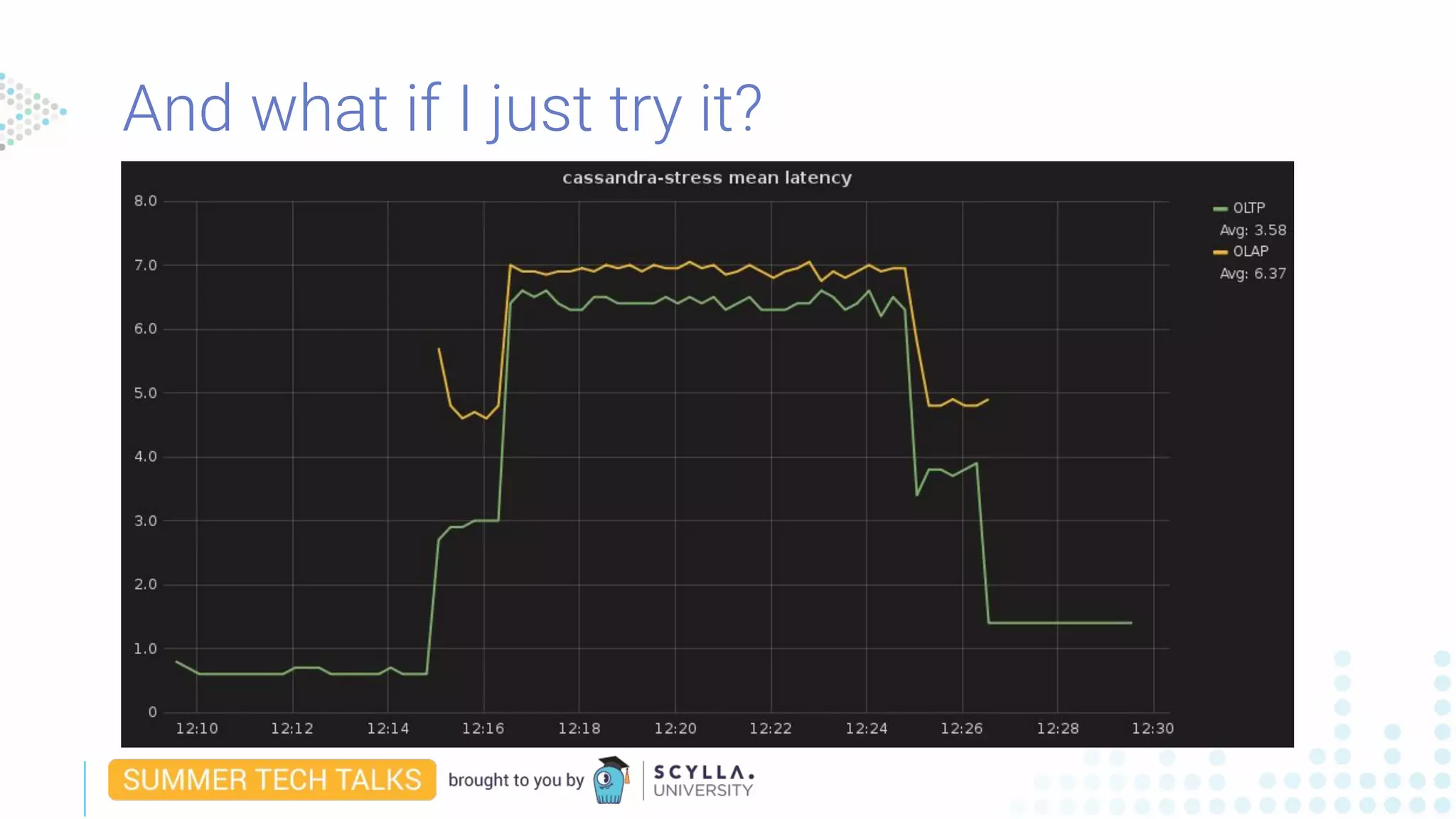
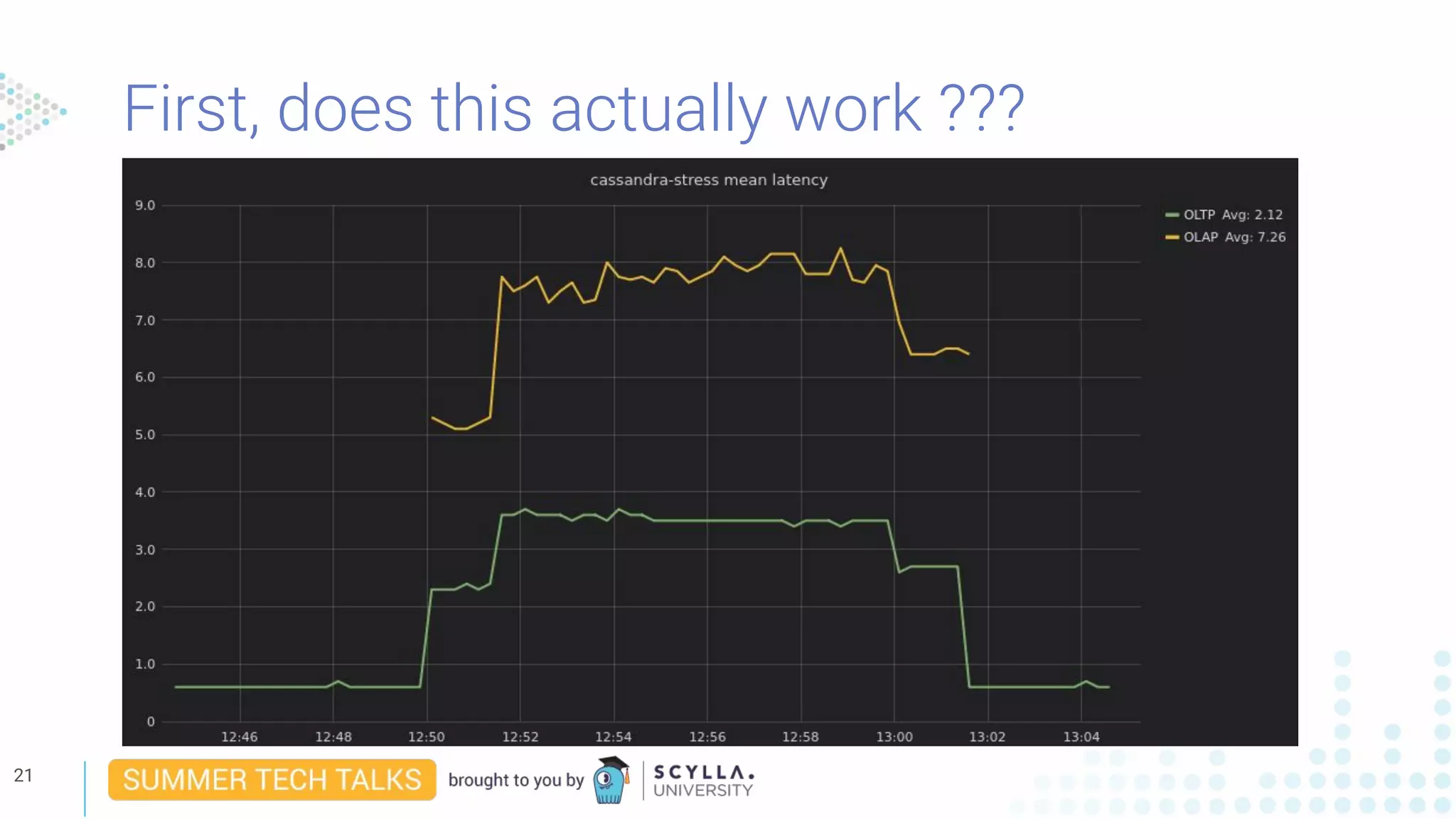
Eliran Sinvani presented on how to shrink a datacenter footprint by 50% using workload prioritization. He discussed how OLTP and OLAP workloads have different needs and how existing solutions like multi-datacenter deployments and time-division waste resources. Workload prioritization uses CPU scheduling to divide resources dynamically based on workload priorities. It allows combining workloads without degrading performance or wasting hardware.






















































































