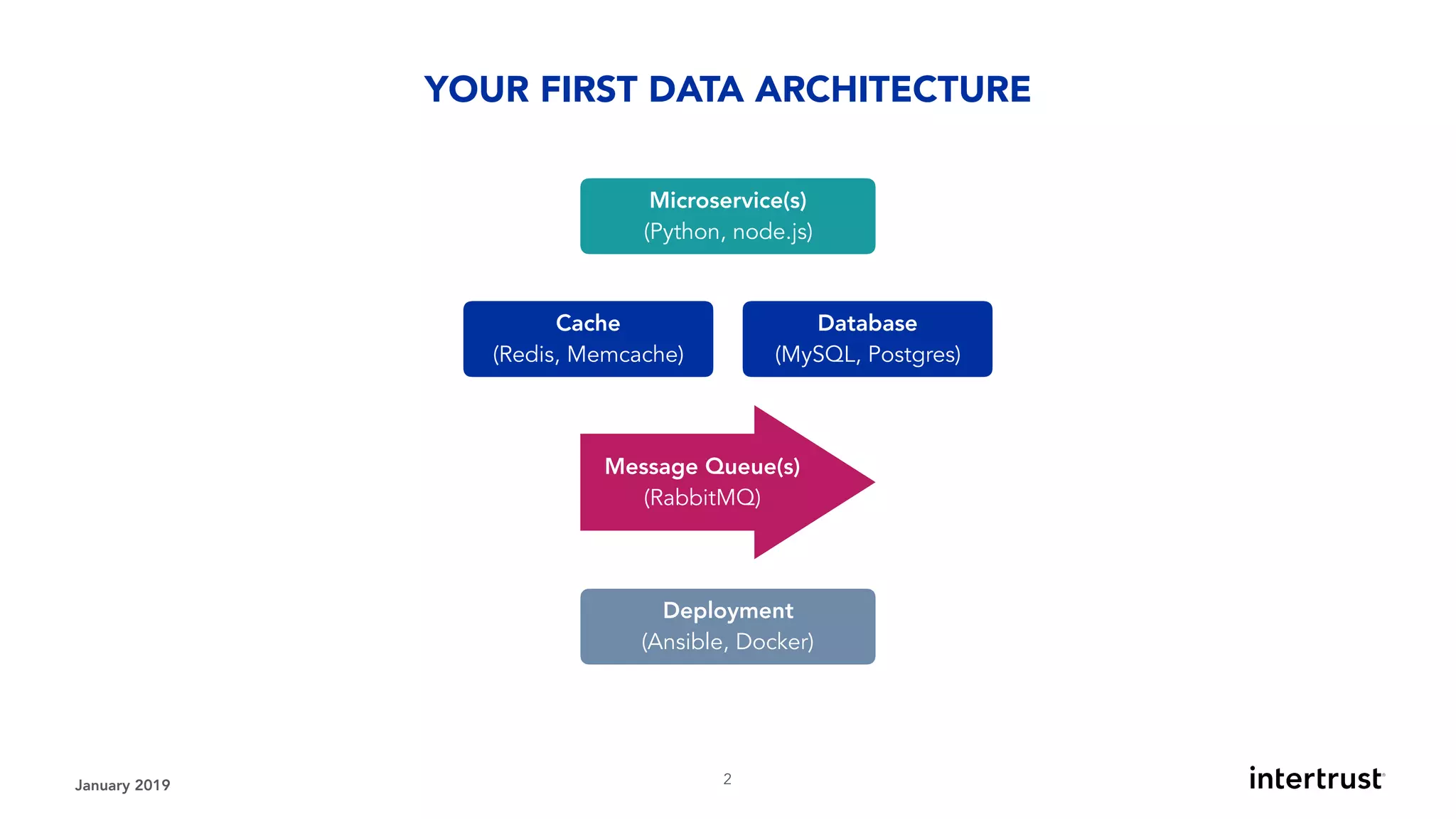
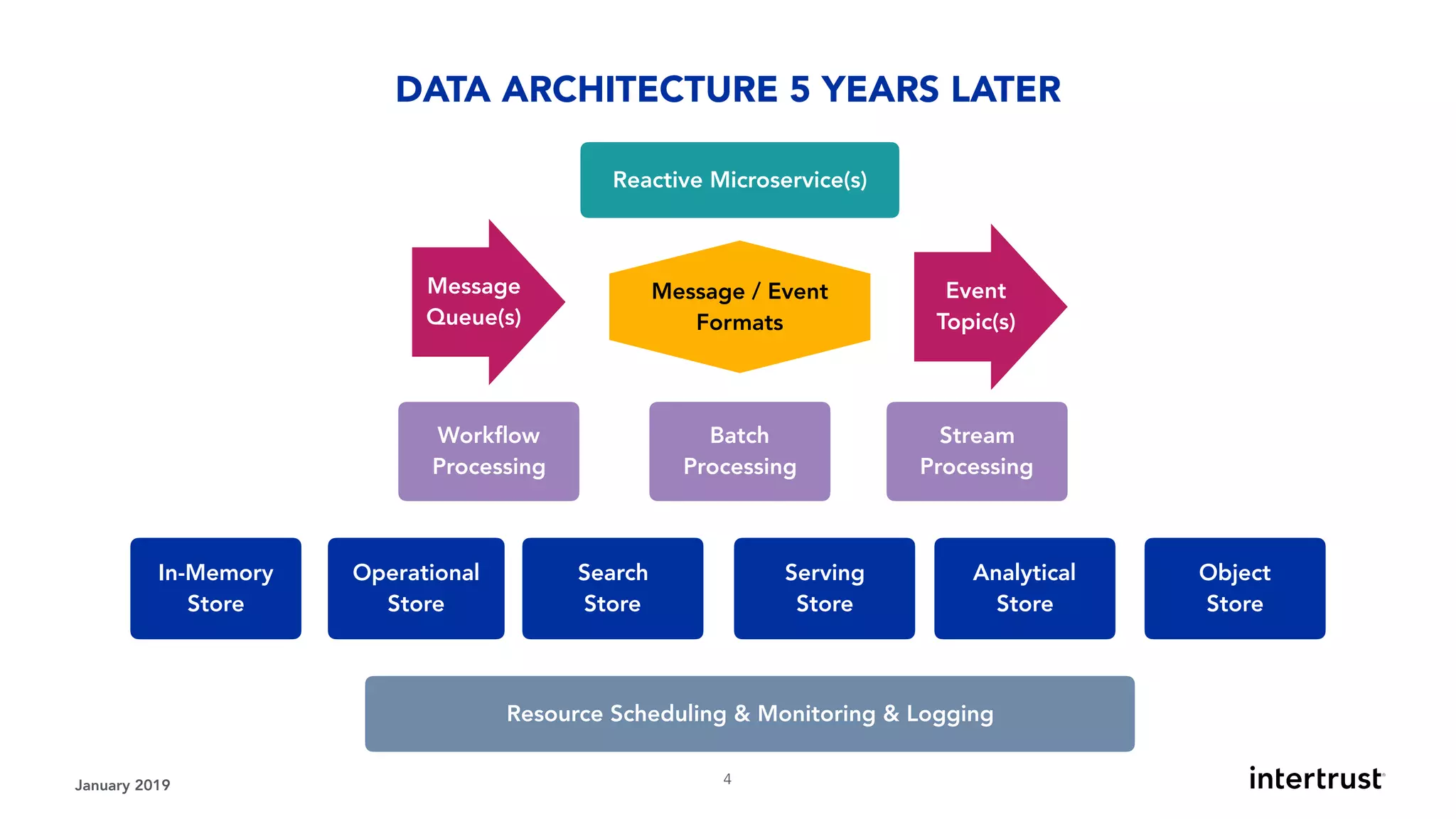
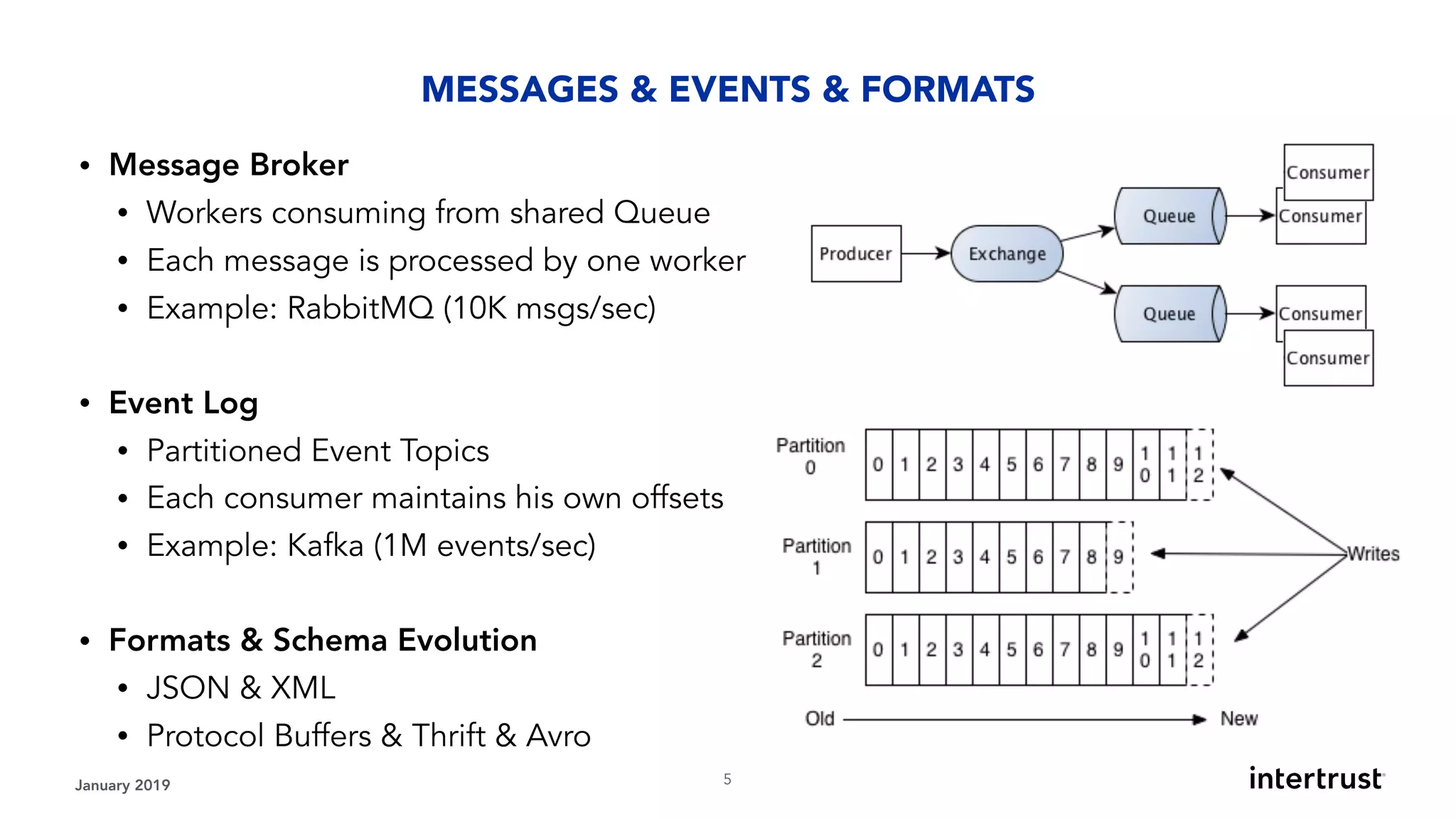
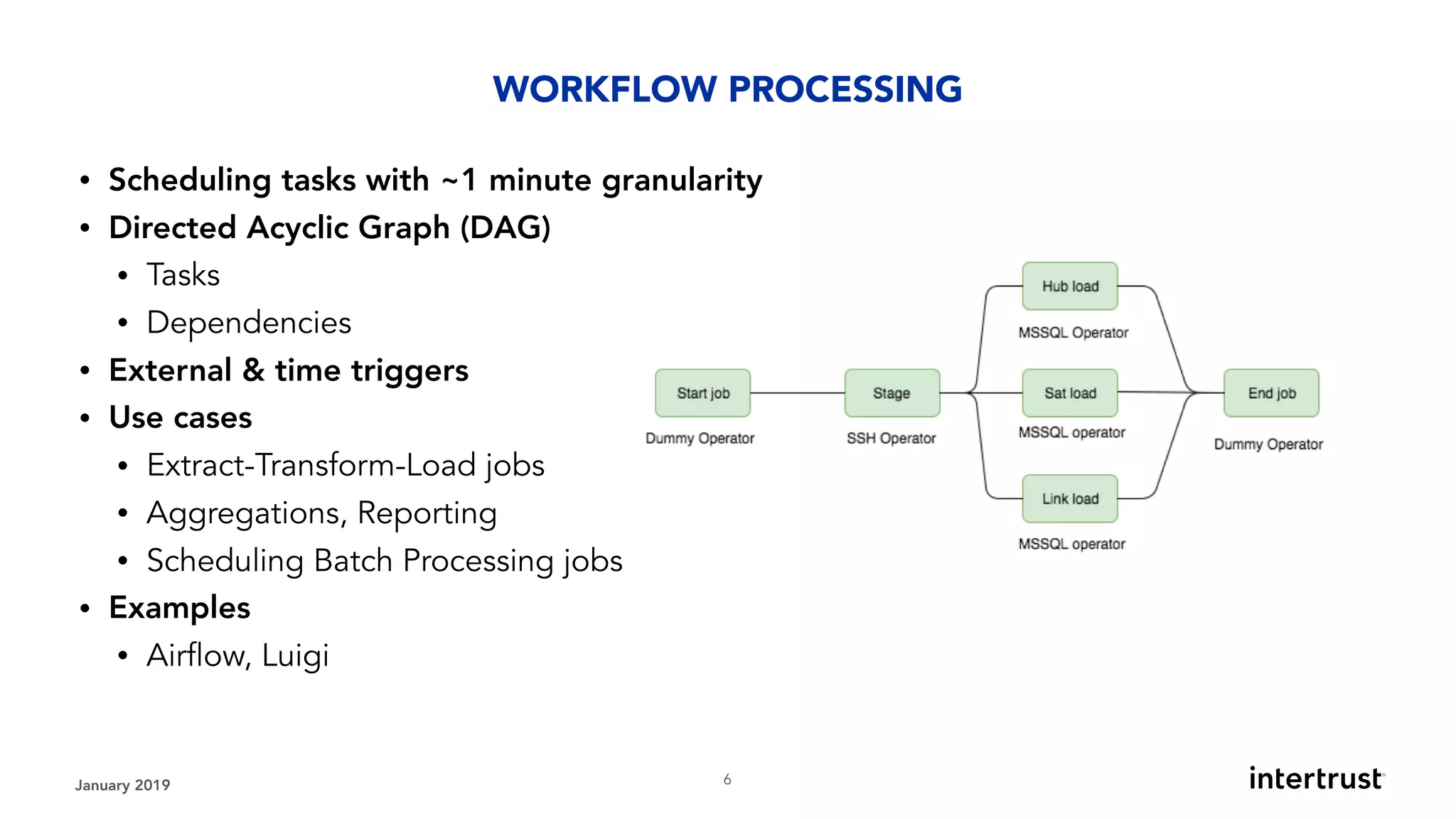
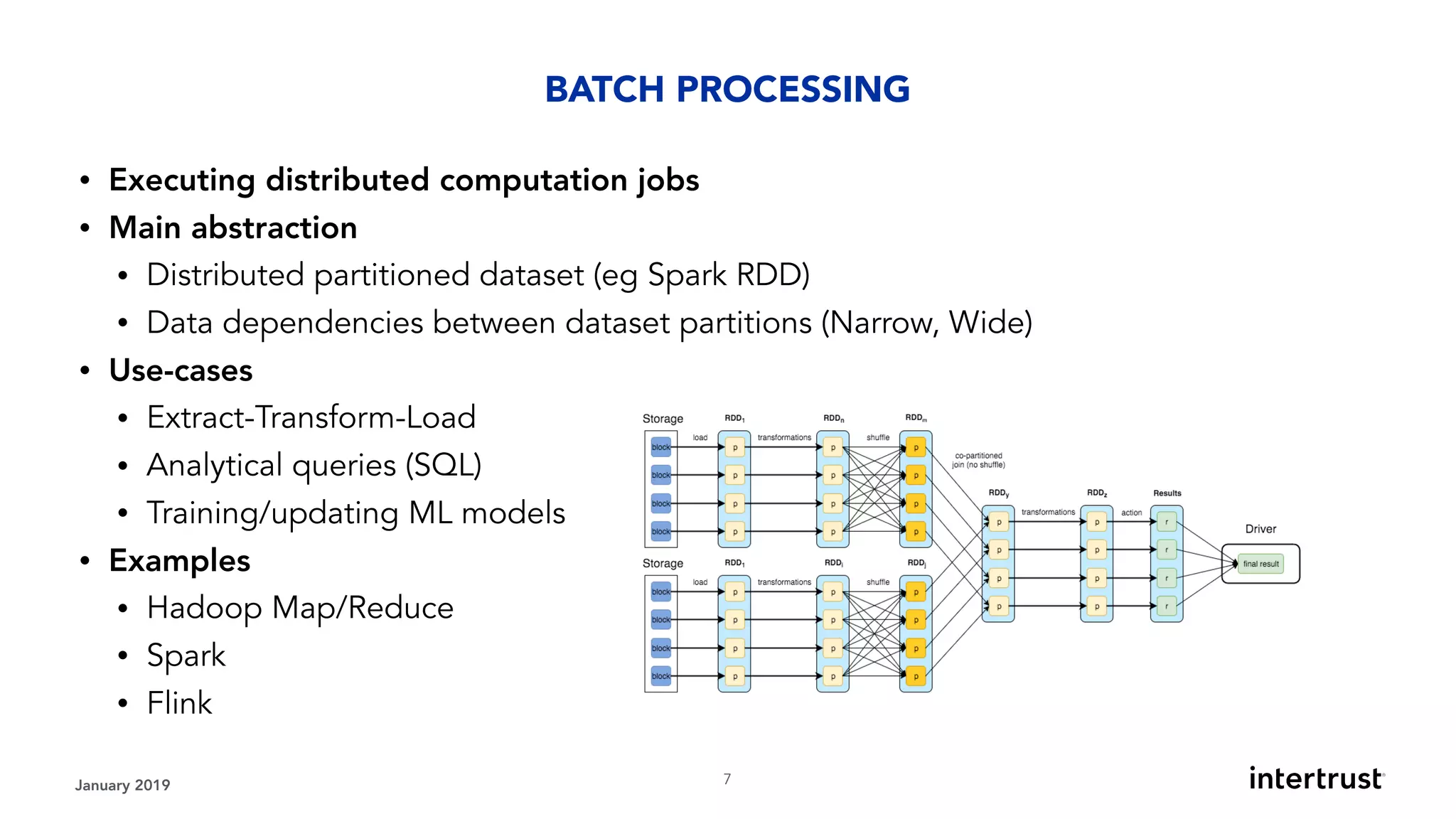
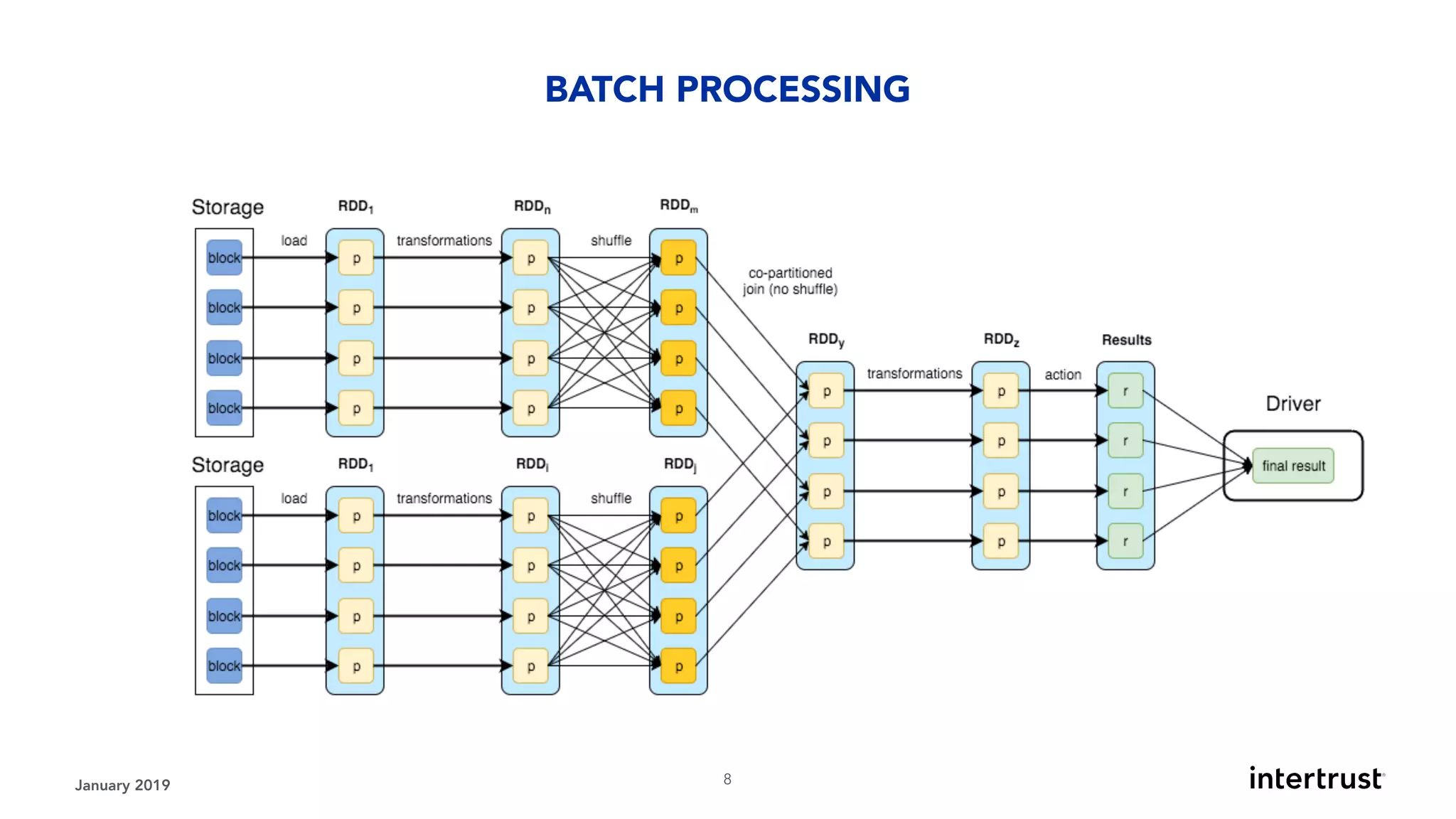
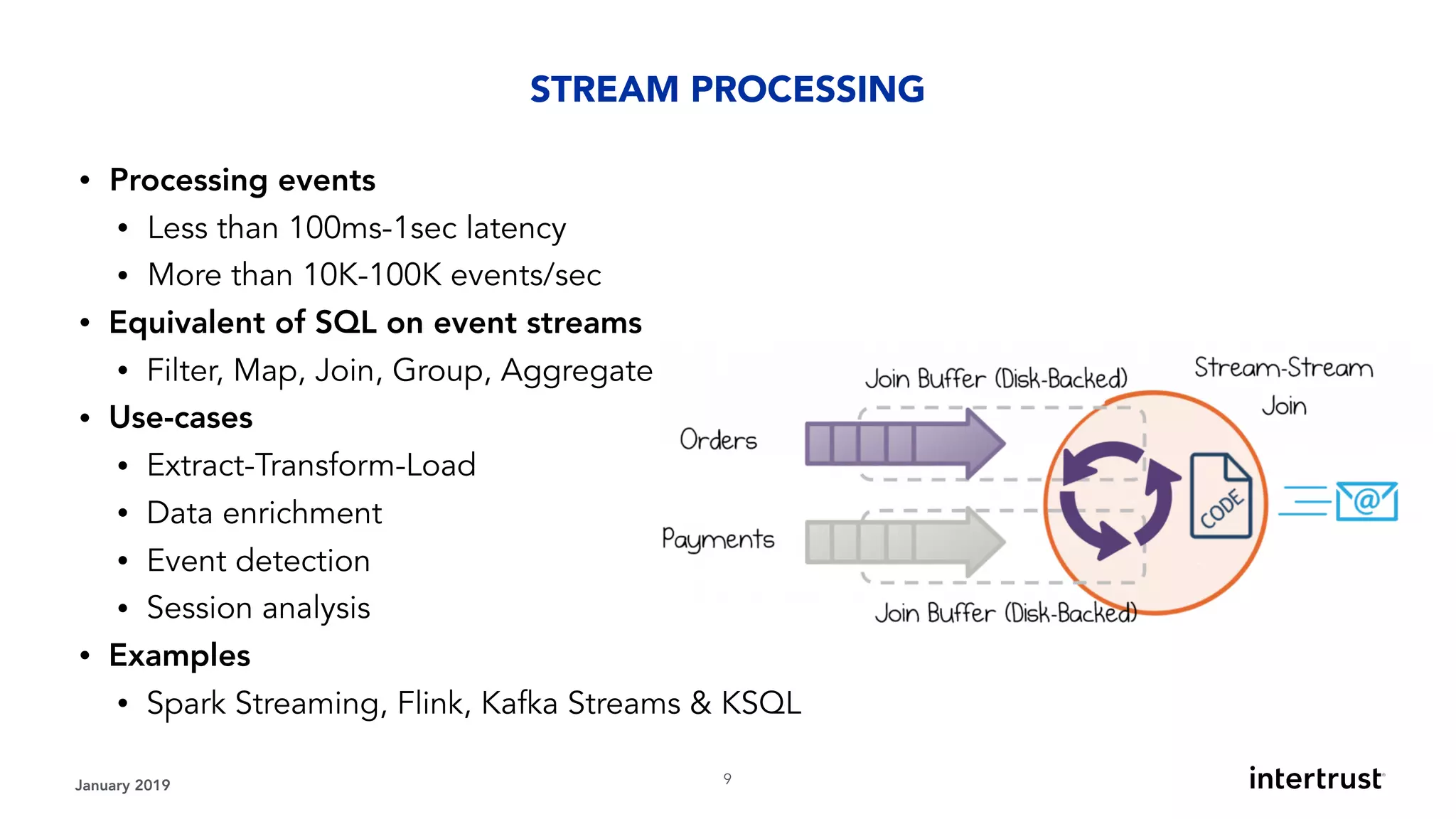
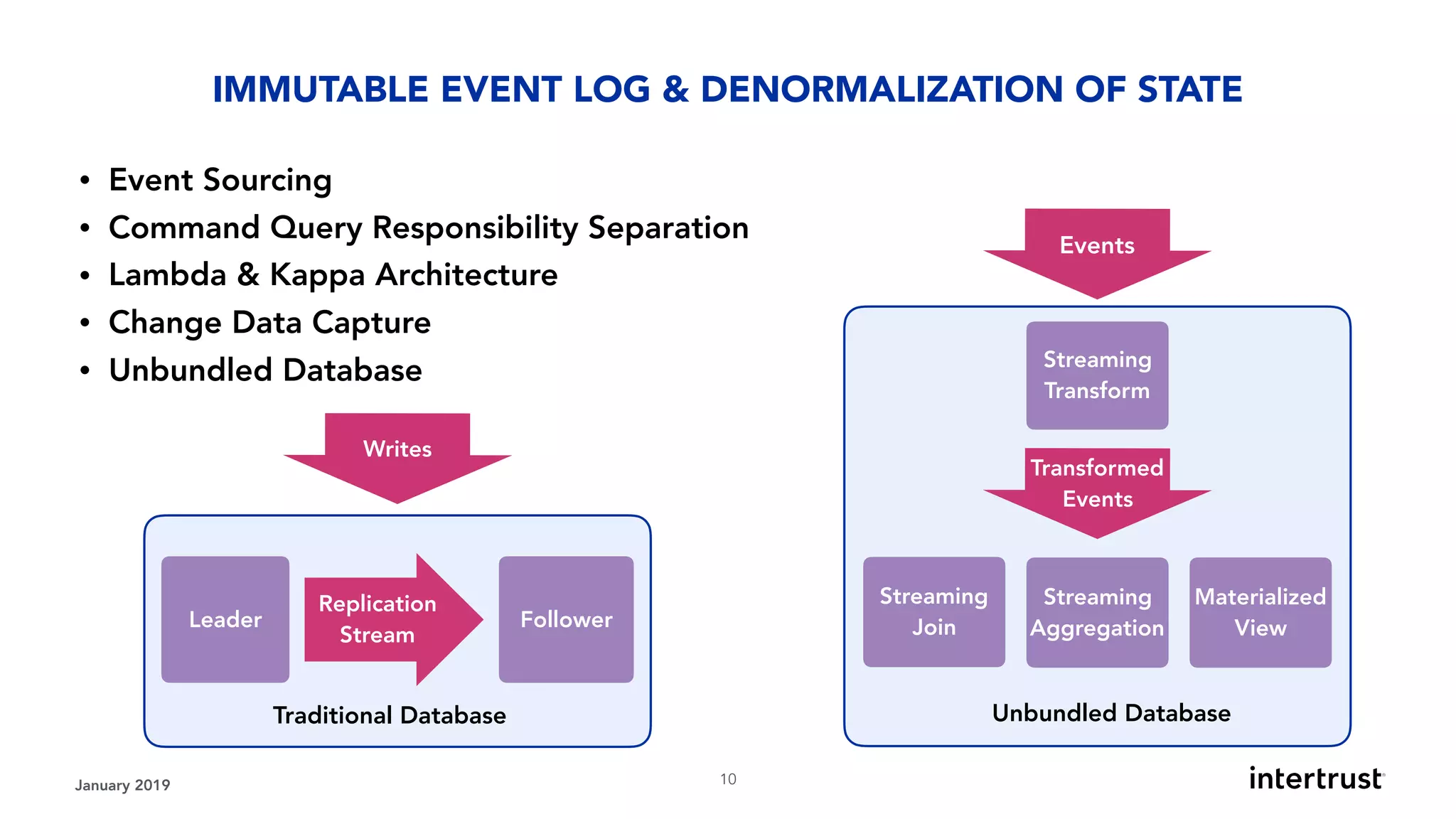
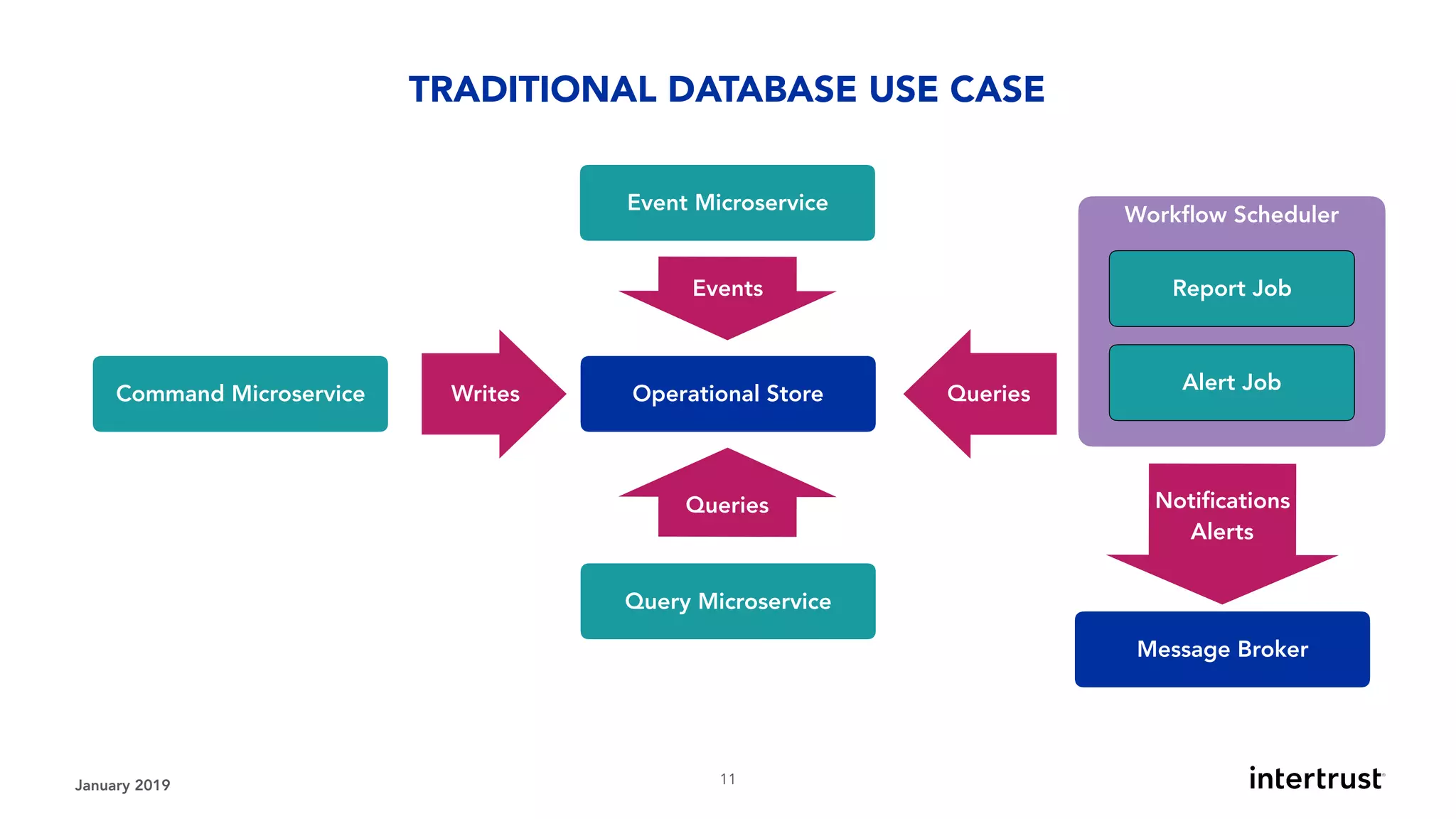
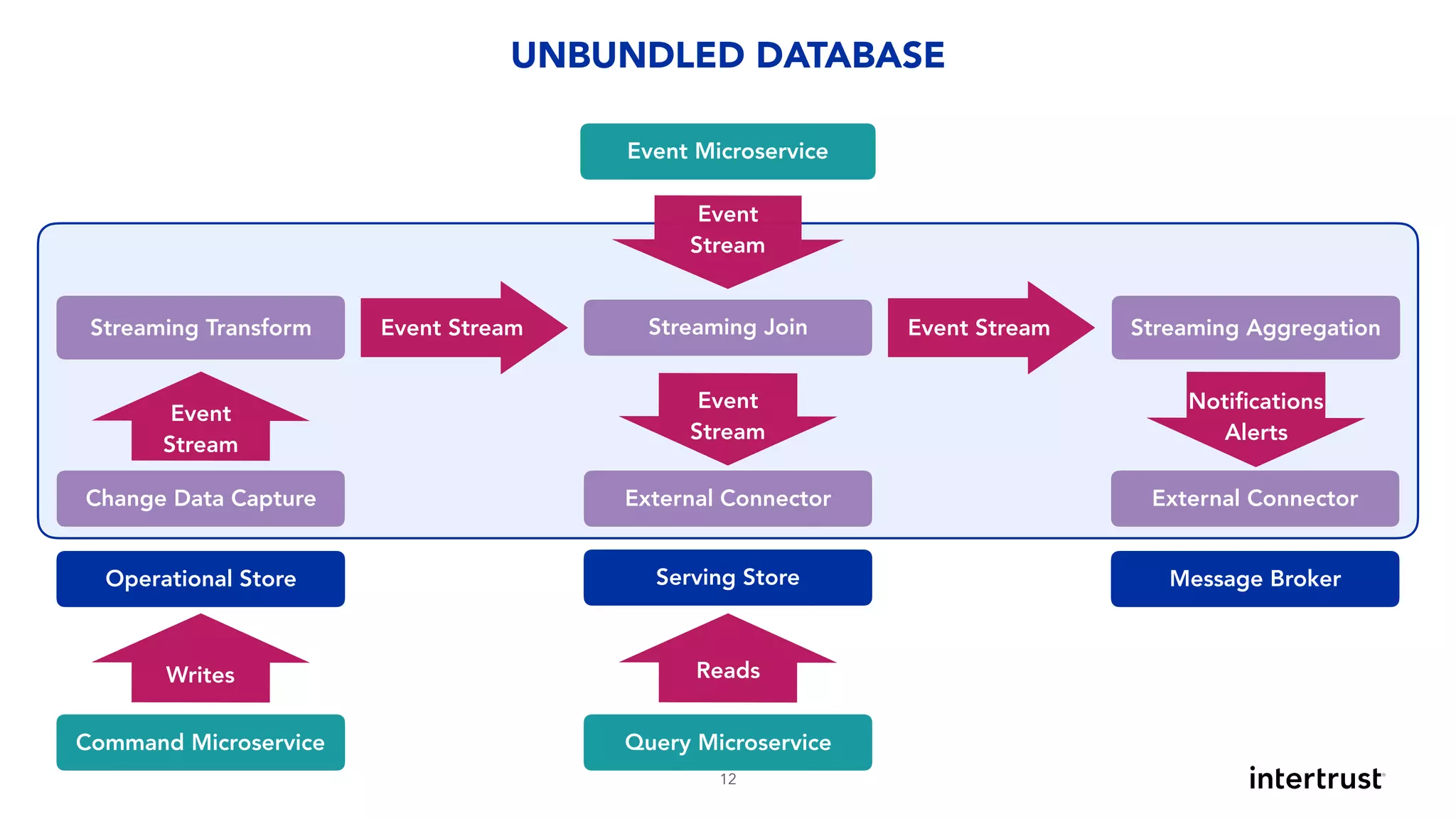
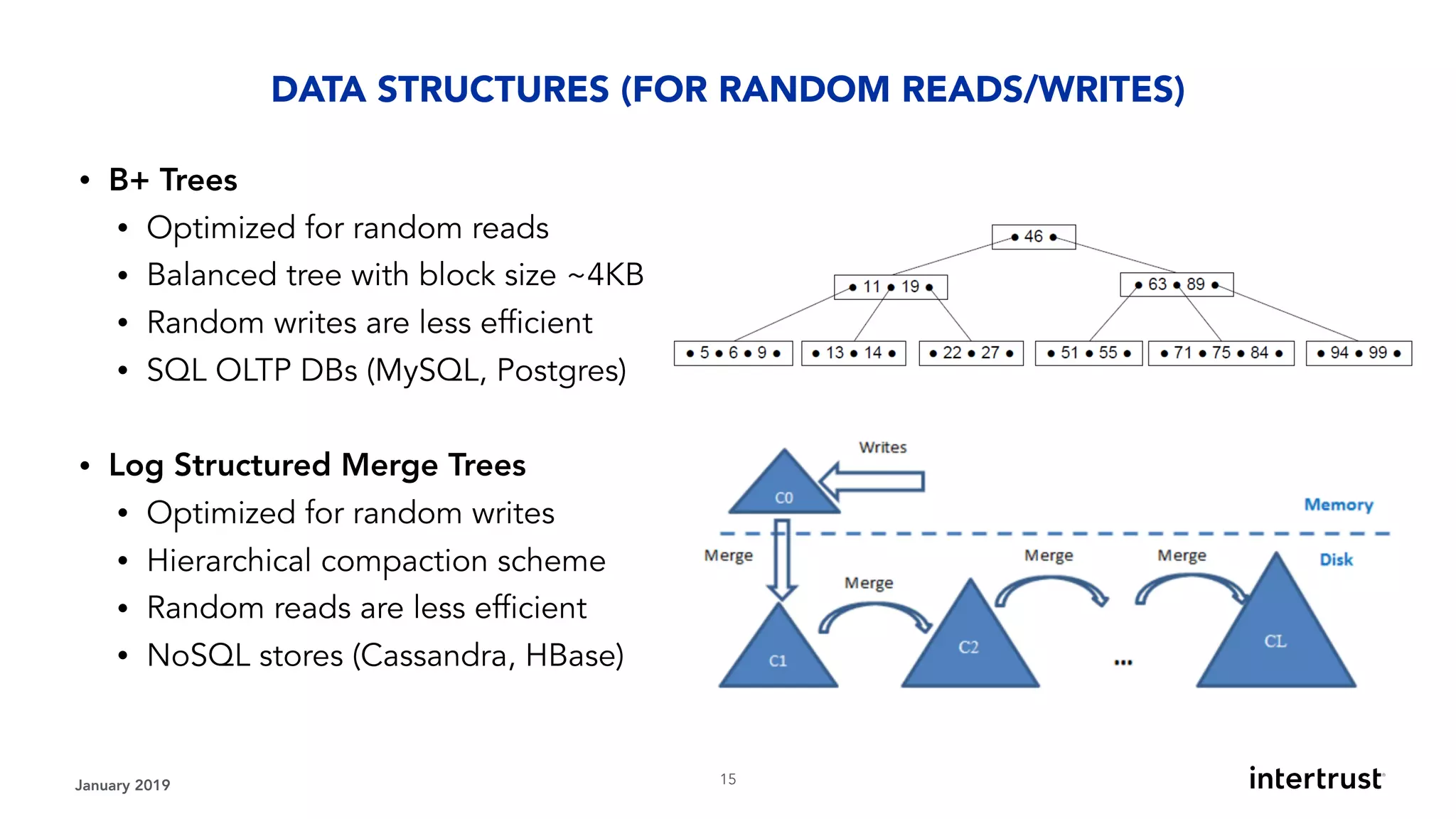
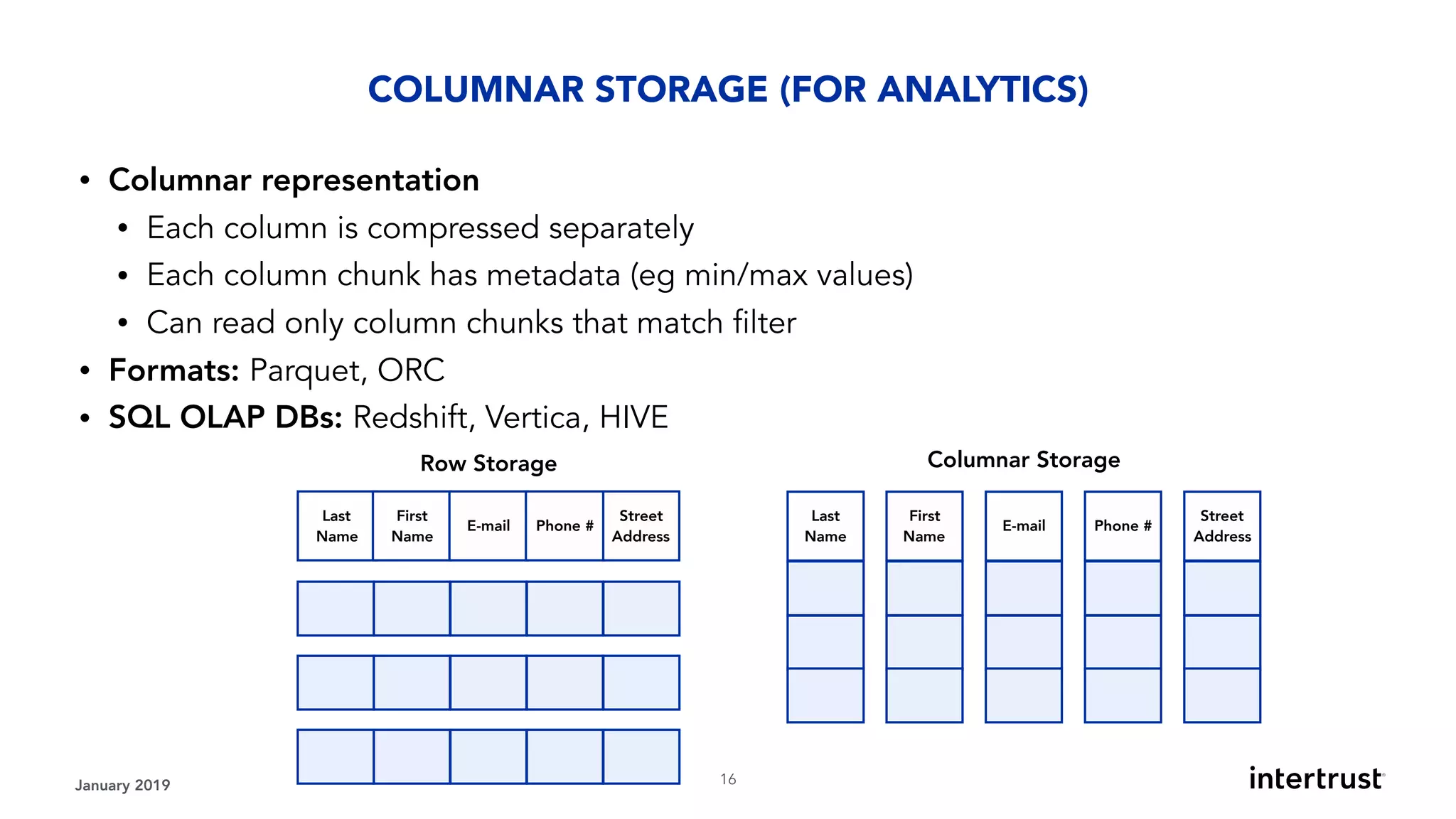
This document provides an overview of designing data-intensive applications. It discusses microservices, databases, caching, messaging queues, and deployment strategies. It outlines requirements like scalability, throughput, reliability and evolvability. Challenges include partitioning data for scalability, handling high transaction volumes, and performing joins across databases. The document then discusses architectures using message/event-driven microservices with different data stores for operational, search, analytical and other workloads. It also covers data processing strategies like batch, stream and workflow processing.































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













