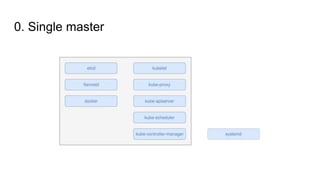
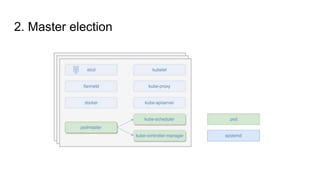
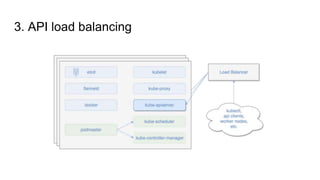
The document outlines a presentation by Alexandre Gervais on implementing high availability (HA) for Kubernetes clusters at a Montreal meetup. It details a three-step program for achieving HA, including etcd clustering, master election, and API load balancing, with references to relevant resources. The emphasis is on the necessity of additional setup beyond a single master in typical Kubernetes setups.