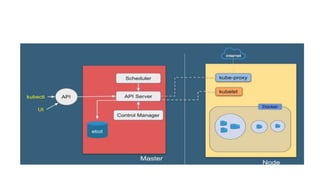
Kubernetes is a container management tool that manages containerized applications, providing features like automatic bin packing, service discovery, load balancing, and self-healing. It uses a cluster architecture composed of at least one worker node and one master node, with an API server facilitating user interactions through the kubectl command line utility. Kubernetes objects are defined in JSON or YAML manifests and can be managed imperatively or declaratively, including deployments that simplify scaling and managing application lifecycle states.