マスター タイトルの書式設定
12
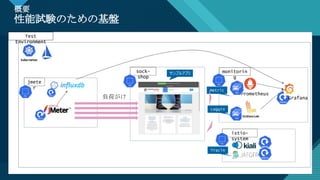
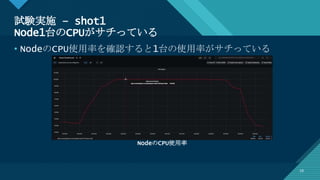
性能改善の営み @K8sの準備
12
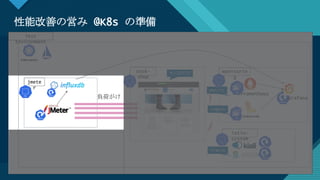
Test
Environment
Prometheus
Loggin
g
sock-
shop
istio-
system
monitorin
g
jmete
r
Metric
s
Tracin
g
負荷がけ
サンプルアプリ
Grafana
マスター タイトルの書式設定
14
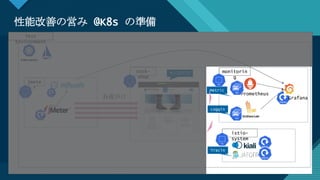
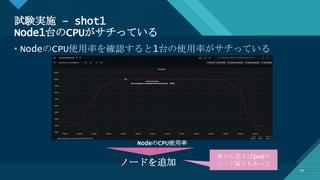
性能改善の営み @K8sの準備
14
Test
Environment
Prometheus
Loggin
g
sock-
shop
istio-
system
monitorin
g
jmete
r
Metric
s
Tracin
g
負荷がけ
サンプルアプリ
Grafana








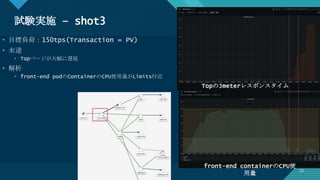
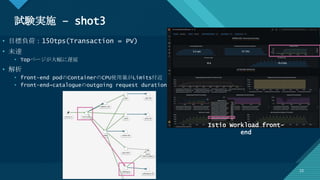
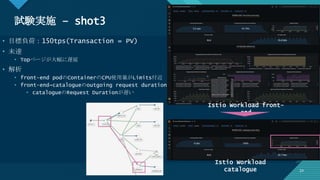
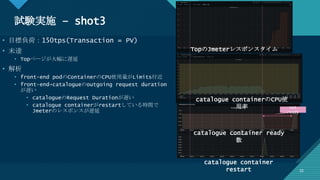






























![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)

























