Downloaded 414 times




















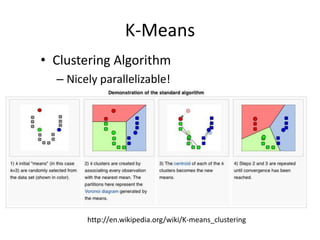


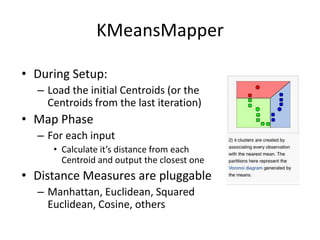
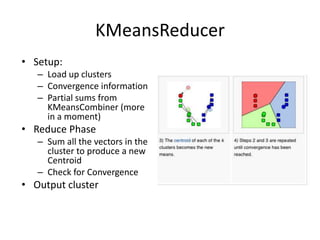


Machine learning is used widely on the web today. Apache Mahout provides scalable machine learning libraries for common tasks like recommendation, clustering, classification and pattern mining. It implements many algorithms like k-means clustering in a MapReduce framework allowing them to scale to large datasets. Mahout functionality includes collaborative filtering, document clustering, categorization and frequent pattern mining.










































































































